2016中国高校计算机大赛大数据挑战赛上,data_coders团队对阿里音乐流行趋势预测进行了自己的阐述理解。首先对赛题进行了分析,确定解题思路,重点对算法进行了说明,包括类别分析、特征提取和算法模型,最后做了简要的总结。一起来欣赏下。
问题分析
已知20150301-20150830的用户行为和歌手歌曲历史记录,预测9月1日至10月30日1000位歌手每天的歌曲点播量?
对用户来说,用户涉及到的歌手进行点播量预测累加,但是单个用户点播行为随机性大,误差积累,模型复杂,直接Pass掉;对歌曲来说,每一首歌曲进行预测累加,但是单首歌曲点播量随机性大,误差积累,所以也被抛弃了;因此,我们从歌手的角度出发,直接预测,统计183天每一天的歌曲点播量,从中构建模型预测,抽样用户越多,歌手歌曲点播量规律越明显。
求解思路
- 时序模型预测:arima模型需要对每个歌手训练三个参数,参数多且需要手动调参,不适合长时间序列的预测;
- 回归模型预测:采用gbdt、rf机器学习算法,需要构建特征,但特征不充足,效果不好;
- 中位数:选用最后十天点播量中位数,不受奇异值影响,反映数据集中趋势,效果让我们惊喜;
虽然能够从用户涉及的歌手找到规律,但仅仅靠这些规律去构建模型,预测接下来两个月每一天的点播量,还是有点不切实际的,只要在两个月中歌手有突发因素发生,由于突变因素导致的点播量猛增,模型是没有办法预测的,所以启发我们构建歌手画像+歌手分类+函数拟合的思路。
算法介绍
数据处理
- Language:1:国语;2:日语;3:韩语;4:英语;11:粤语;12:闽南语;14:法语;100:纯音乐。
- Gender:1:男;2:女;3:团体。
- 歌手画像:性别,语言,专辑发行时间,专辑包含的歌曲数。
- 根据歌手画像从虾米官网爬取歌手姓名。
- 爬取歌手在20150301-20151030期间发行的专辑。
- 爬取20150301-20151030期间发行专辑的详细信息:专辑发行时间,专辑的歌曲数,专辑评论数,专辑评分,专辑乐评时间及乐评内容。
查找20150301-20151030期间的综艺节目有哪些信息涉及到需要预测的歌手(譬如:中国好声音,蒙面歌王,无限挑战等);查找20150301-20151030期间的热门电影,电视剧主题曲有没有需要预测的歌手演唱;查找20150301-20151030期间有哪些国外歌手在中国开过演唱会;绘制每个歌手183天的趋势图。
类别分析
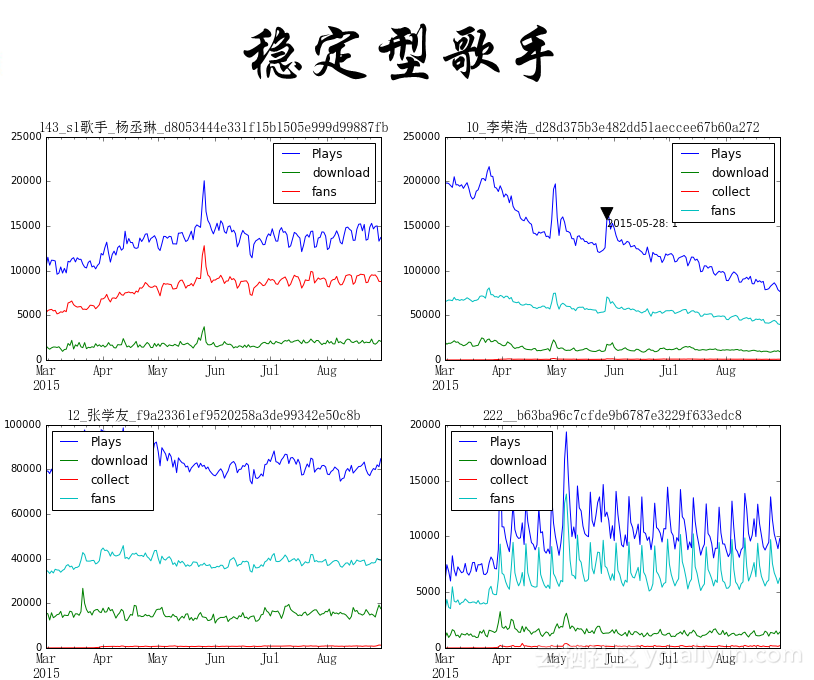
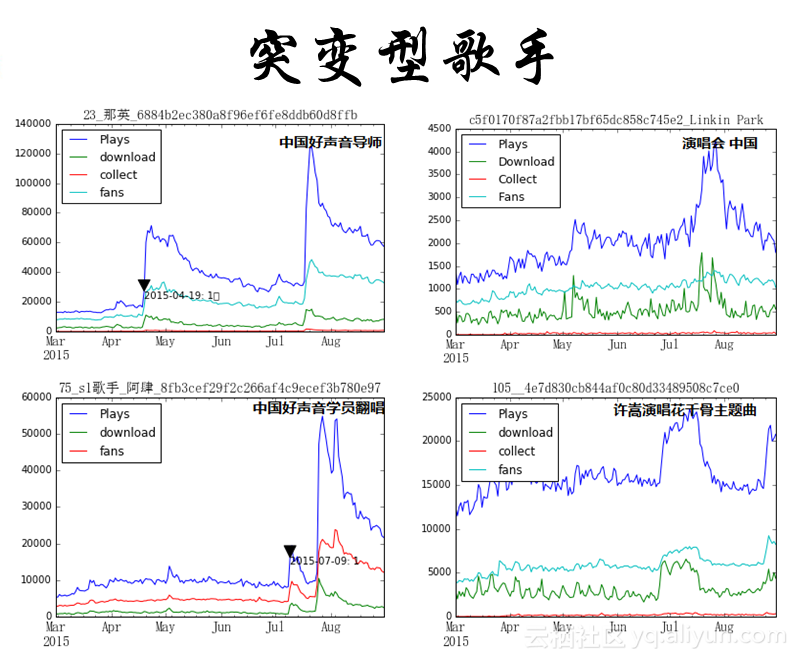
将歌手分为两大类:
- 平稳型歌手:
A.上升型歌手;B.下降型歌手;C.稳定型歌手;D.周期型歌手。
- 突变型歌手:
E.发行新专辑;F.参加综艺节目;G.开演唱会;H.中国好声音有学员翻唱其歌曲; I.演唱热门电视剧或者电影主题曲等。
特征提取
突变歌手特征:
1. 一般来说,突变型歌手的点播量在突变因素发生后呈现出长尾效应的特征,符合互联网短平快的特点;
2. 突变因素发生后的5天内点播量会达到最大峰值,突变因素效应持续大概15—30天不等,之后达到稳定值,稳定值停留在峰值和突变因素发生前10天点播量中位数的中间位置附近。
此外,我们发现不少歌手点播量呈现周期性规律;节假日点播量一般会稍微降低;每日用户数周期性规律明显,呈现总体上升趋势。
算法模型
- A、B、C平稳型歌手:(线性拟合)
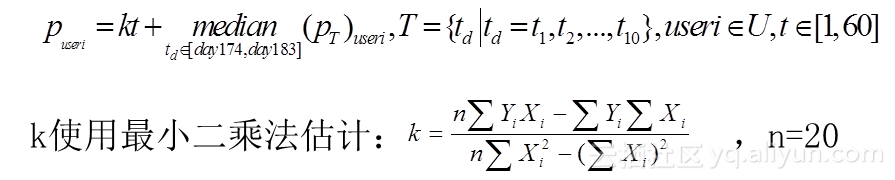
- 周期型歌手D:(规则+中位数)
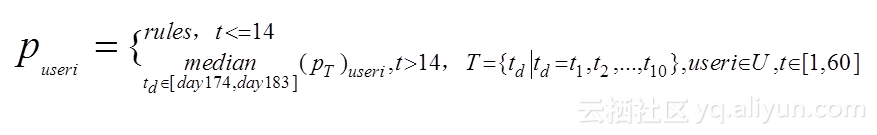
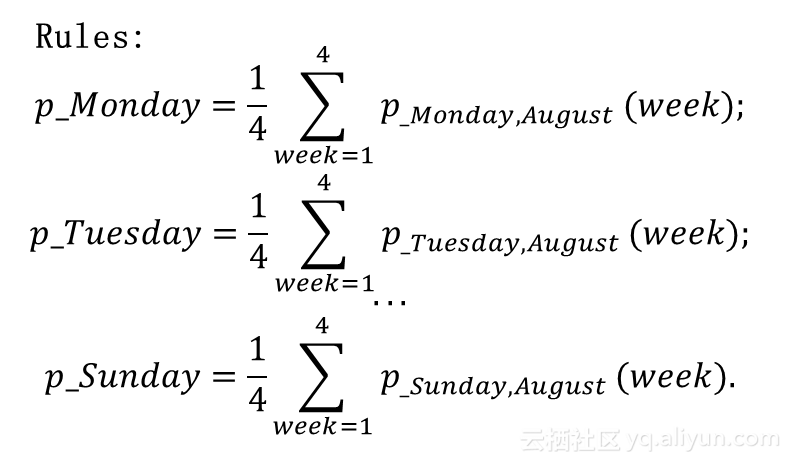
- E、F、G、H、I突变型歌手:(高斯函数拟合)

比如对于突变因素为发行新专辑的歌手,特征主要包括专辑发行时间,专辑的歌曲数,专辑评论数,专辑评分,专辑乐评时间及乐评情感得分等。
收获与成长
通过这次实践,我们收获颇多,认为应该以业务为本、数据为源、模型为武器,将主要精力从算法转移到对业务的深刻理解和分析中,呈现出来的模型才有可视用性和泛化性。
同时,我们也感谢阿里提供的真实的数据、优秀的大数据平台和良好的技术交流环境。我们也希望平台今后可以支持Python语言,可以更好地支持数据可视化。
最后
以上就是微笑高山最近收集整理的关于2016中国高校计算机大赛——大数据挑战赛极客奖:data_coders团队的全部内容,更多相关2016中国高校计算机大赛——大数据挑战赛极客奖内容请搜索靠谱客的其他文章。








发表评论 取消回复