datafountain剧本角色情感分析赛后总结
- 模型的搭建
- 整数与浮点数提交之争
- 上下文的选择以及主语的加入
- 验证集和测试集的划分问题
- 多折模型训练及模型融合的方法
- 融合提升的要点
- 预训练操作
- 对抗训练
- 种子的固定
- 修改代码的注意事项
- 增强数据
- 更换主语
- 一些可能有效没时间尝试的方法以及一些在我们的体系下没有用但是在别人的体系下可能有用的方法
- 选用large模型
- 参考大佬的解题策略,总结一下自己没想到的解题步骤
- 大佬思路1:
- 随机名称的替换
- 文本里增加前置提示语,如在文本开头添加 `剧本: {movie} 场景: {scene} 角色: {character_name}`、文本角色前面添加 `剧本{movie} `等:+0.003
- 使用emb_svr_rapids.py进行调用
- 更加深入的网络结构内容
- 大佬思路2:
- BERT+MMOE
- NEZHA常规模型
- NEZHA+attention
- SKEP+上下文特征融合
- 本赛题应该的正确路线
- 每次训练的过程数据随机化一下
- 融合模型的时候可以加入相应的权重参数在验证集合之上跑最高的分数
- 总结
比赛链接
源码地址
本次我与抖音大佬共同组队参加了剧本角色情感识别的比赛,成绩为二十多名的水平,这个成绩距离前排大佬还有一定的差距,因此我们需要进行一定的反思总结。
模型的搭建
第一个遇到的问题是模型的搭建问题,起初我们的想法是采用常规的分类做法,搭6个网络层,对于每一个网络层使用交叉熵损失函数进行模型训练,但是在这个比赛上这种方式指标并不佳。原因在于本次比赛采用了均方根误差的方式来计算评分,所以使用mse作为损失函数效果较好。
 这里也提醒我们,在打比赛的过程之中一定要采用更加贴合评测指标的损失函数进行训练。
这里也提醒我们,在打比赛的过程之中一定要采用更加贴合评测指标的损失函数进行训练。
修改了模型结构之后,我们选用nezha后面接上一个(768,6)的线性层进行回归计算,效果有明显的提升。
在比赛的过程中,我们还实验过其他结构,比如多个线性层加上dropout
class ClassificationModel(nn.Module):
def __init__(self,model,config,n_labels):
super(ClassificationModel,self).__init__()
#self.embedding = nn.Embedding(30522,768)
self.model = model
self.fc1 = nn.Linear(config.embedding_size,128)
self.activation = F.relu
self.dropout = nn.Dropout(0.2)
#self.activation = F.tanh
self.fc2 = nn.Linear(128,n_labels)
def forward(self,input_ids,segment_ids,input_mask):
#outputs = self.embedding(input_ids)
output = self.model(input_ids)
#[64,128,768]
output = self.dropout(output)
output = output[:,0]
output = self.fc1(output)
output = self.activation(output)
output = self.dropout(output)
output = self.fc2(output)
return output
整体效果与(768,6)线性层效果差不多,另外使用这种结构训练之后进行融合模型结果也没有明显的上升。
整数与浮点数提交之争
对于mse损失函数,有一个必要的特性,就是当你的值越远离增加标签的时候,每远离一步就会放大误差,这里举一个例子来说明
如果真实标签为1的时候,假设标签距离都为0.1
1.本身预测为0.9,放缩为1
减小误差
(
1
−
0.9
)
2
−
(
1
−
1
)
2
=
0.01
(1-0.9)^2 - (1-1)^2 = 0.01
(1−0.9)2−(1−1)2=0.01
2.本身预测为1.9,放缩为2
增大误差
(
2
−
1
)
2
−
(
1.9
−
1
)
2
=
1
−
0.81
=
0.19
(2-1)^2-(1.9-1)^2 =1-0.81 = 0.19
(2−1)2−(1.9−1)2=1−0.81=0.19
可以看出来情形2比情形1放大了19倍
这也就是我们为什么选择浮点数提交的原因
有些标签计算的可能有向正确标签的趋势,但是由于模型学习能力所限未能够达到正确的标签,此时如果选择整数提交的话,可能这一部分数据过大会拉大误差,因此这里我们选择浮点数进行提交
上下文的选择以及主语的加入
如果想要模型学习充分,必须加入所有的特征。
首先我们必须加入主语部分,因为同一句可能包含不同的主语。
其次我们需要加入上下文部分,因为上下文的情感同样也可能影响当前的情感。
对于上文加入,我们有以下几种策略:
1.加入上文不同角色的5句话(可以是n句话,大致4~6句最佳)
2.加入上文同一角色的多句话(可以是n句话,也可以全加)
实验的过程中发现策略1效果更好,猜测可能是由于方案2中的加入多句话有的时候距离较远,可能影响模型对于情感的判断。
同时跨幕在实验中发现结果会下降,说明上一幕的情感并不会影响到本幕的情感。
验证集和测试集的划分问题
验证集和测试集的划分有两种方式:一种是按照不同的情感来进行划分,另外一种是不同的剧本来进行划分。官方的baseline推荐的是按照剧本进行划分,这里我们尝试了两种方案,发现两种方案线上线下都有较大的差距,相对来讲按照剧本划分可能更好一些,因为按照标签划分前面有一些句子可能在模型中训练过了。
多折模型训练及模型融合的方法
通过实验,我们选择按照剧本划分多折,每一折选择3个剧本,总共为10折的过程,模型融合采用平均融合的方式,单折多模可以提升到0.707x的水平。
模型融合的时候应该选择分数相近的模型进行融合,才能有效的提升分数。针对mse一般采用平均融合的方法
之所以可以采用平均的模型融合方法,这里通过举例说明一下:
由于两个模型预测结果分数相近,假设第一个模型对于标签1的距离为0.75,对于标签2的距离为0.25,第二个模型对于标签1的距离为0.25,对于标签2的距离为0.75,则这两个模型的mse均为
1
2
∗
(
0.7
5
2
+
0.2
5
2
)
frac{1}{2}*(0.75^2+0.25^2)
21∗(0.752+0.252),而融合之后两个标签的距离均为0.5,
m
s
e
=
1
2
∗
(
0.
5
2
+
0.
5
2
)
<
1
2
∗
(
0.7
5
2
+
0.2
5
2
)
mse = frac{1}{2}*(0.5^2+0.5^2) < frac{1}{2}*(0.75^2+0.25^2)
mse=21∗(0.52+0.52)<21∗(0.752+0.252)
因此如果分数接近的两个模型融合,很有可能能够提升分数
融合提升的要点
融合模型的过程中最主要的是选择不同路径的分数相近的模型(根据上面分析可得)。
在实验中我们发现,如果选择变化不大的模型进行融合,融合到一定程度分数增长缓慢,因此要选择不同的分数相近的模型进行融合,多尝试不同的模型比如nezha、roberta、electra,同时多尝试不同的方法,比如更换主语,加入不同的上文等。
此外模型还可以采用多模型加入一个线性层进行融合的过程,这种方法由于代码有点复杂就没有尝试,不过有其他小伙伴尝试了,发现线下很猛线上很拉跨,猜想这里本质上还是由于不同剧本的预测难度不同,标签分布不同,导致一个模型预测线下剧本效果还行的情况下线上不一定能提升。
预训练操作
这里预训练的时候我只加入了本文和上一句话下一句话,总共三句话。感觉这里超出maxlen的部分还可以做得更精细一点,通过句子的部分进行分割。
对抗训练
这里我们实验了fgm对抗训练的过程,由于时间有限未能实验不同的epsilon参数以及pgd对抗的过程。
实验的过程中发现,可能原先未使用对抗训练的种子不再适用于对抗训练的种子(分数波动较大),也就是说选择好相应的epsilon参数之后,还需要一定的时间重新调整种子。
种子的固定
为了保证实验的可重复性,我们需要进行种子的固定。
在实验的过程中,我们发现,tensorflow即使固定了种子,同样代码跑两遍也会出现差异,也就是tensorflow无法做到可复现性。pytorch固定了种子之后,可以保证代码的可复现性。但是即使pytorch固定了种子之后,不同的gpu,不同的系统,不同的nvidia、cuda、cudnn版本都有可能造成不同的结果,因为这些都可能导致随机数计算的方法不同,进而导致最后的结果不同,因此深度学习要想完全完整的复现代码效果,基本上是不可能的。
同样我们也发现,相同的策略在不同的模型,体系,gpu下可能效果不一样,比如之前大佬提供的融合最后两层模型的方法在我们的模型体系之下并不能起到涨分的效果,因此要想提分还是要多实验不同的trick,找寻到能够提升自己模型的trick,别人的trick只能作为自己的备选。
修改代码的注意事项
每次如果变换数据处理的时候,需要修改三个地方:train_dataset,test_dataset以及maxlen,如果修改训练部分的内容还需要修改训练部分
增强数据
由于标签3的数据预测的不好,这里我们尝试着加入一些标签3的数据增强模型训练标签3的能力,但是实验完成之后发现效果并不好,因为增加标签3的数据会改变标签的分布,模型预测标签0、1的能力明显下降。(也有可能加少量的数据有帮助,但是始终没有调节出那个比例)
更换主语
融合模型的过程中可以尝试着更换主语,主要有以下两种方法
1.将本句的角色统一成中文主语,其他内容保持不变
2.将所有的角色随机更换成Vocab中的其他内容
本文尝试了方法1,并与其他的模型进行融合,效果有显著的提升
一些可能有效没时间尝试的方法以及一些在我们的体系下没有用但是在别人的体系下可能有用的方法
simcse、rdropout
transformer最后两层连接接线性层输出
使用sigmoid先将概率映射到0~1,计算标签的时候再乘上相应比例系数(或者将标签/3映射到0~3的区间)
加入洪泛法flooding进行训练
ema平均权重
选用large模型
根据查看其他赛友的资料,发现如果使用xxx-large模型可能会有更好的结果,但是由于一开始没有选择large模型,到后面也没有时间去调整参数了。
参考大佬的解题策略,总结一下自己没想到的解题步骤
大佬思路1:
郑大佬的代码阅读
随机名称的替换
# 随机生成大众名字示例:
FIRST_NAMES = '羿祥惠盛捷霞阳豪誉涵颖梅湘丹勇苗悦朝君杰毓乐曦瑶全恒裕帅馨秋山诗东雯紫木水骏昊艳宗国源莲子锦尔蕾兵天钰财桥轩桐海运坤信卿诚欣茂明晓月韬泳绮侦熙龙舟雨晴元峻程金宇启浩莉彤槐巧艺伟伊扬洋琪正森文鹏辉泽婷美超玉娴智敬奎强玄心高嵘思朗萱昆宸甜凌俊治云仕亭苹喜寅书华瑜晨益仁璇满贵利沁淳林伯晞嘉辰'
SECOND_NAMES = '李王张刘陈杨赵黄周吴徐孙胡朱高林何郭马罗梁宋郑谢韩唐冯于'
def gen_names():
f1 = FIRST_NAMES[random.randint(0, len(FIRST_NAMES)-1)]
f2 = FIRST_NAMES[random.randint(0, len(FIRST_NAMES)-1)]
s1 = SECOND_NAMES[random.randint(0, len(SECOND_NAMES)-1)]
return f'{s1}{f1}{f2}'
其他一些替换主语的方式
文本里增加前置提示语,如在文本开头添加 剧本: {movie} 场景: {scene} 角色: {character_name}、文本角色前面添加 剧本{movie} 等:+0.003
处理完成之后的内容
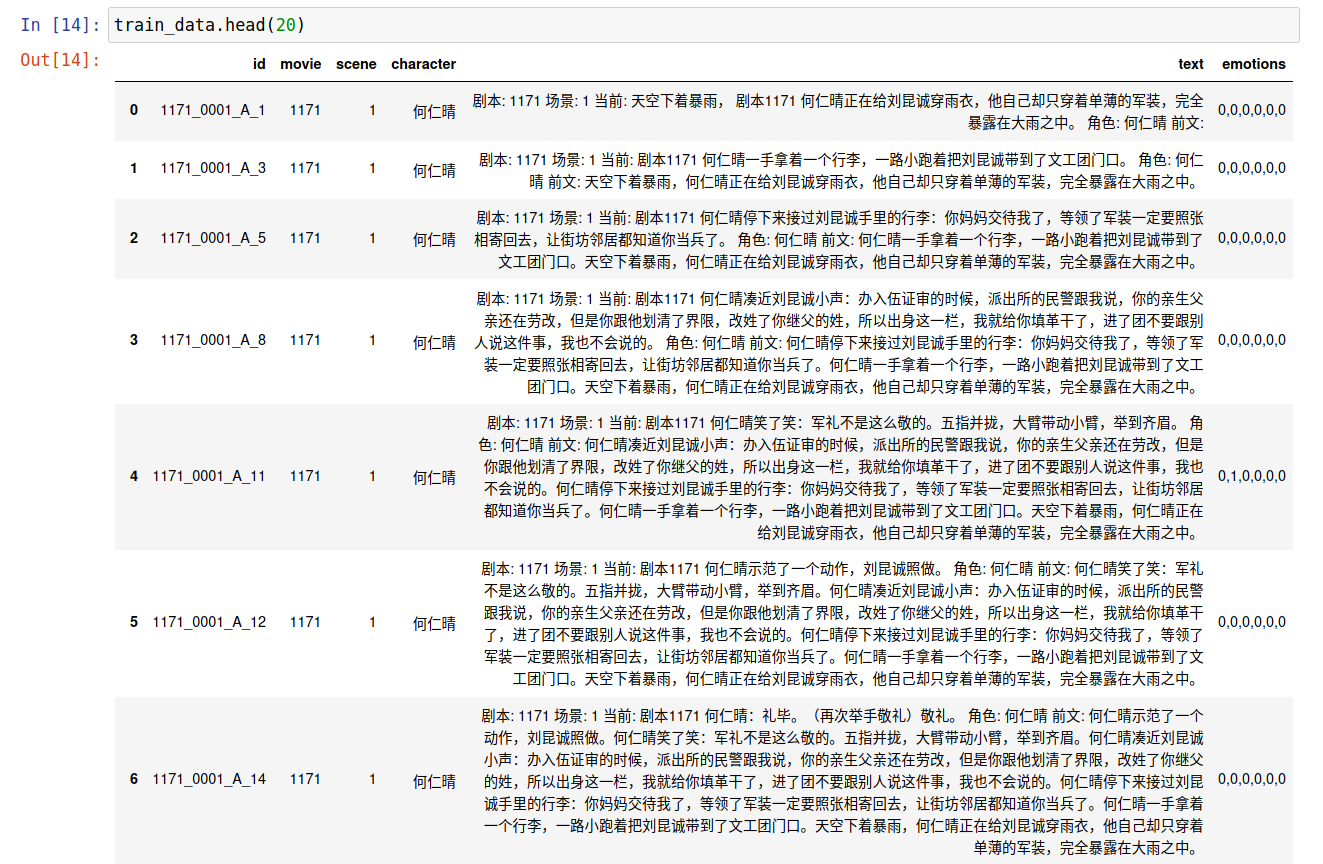
使用emb_svr_rapids.py进行调用
def run_svr(ycol, fold):
X_train = train.iloc[kfolds[f'fold_{fold}']['train']][feature_names]
Y_train = train.iloc[kfolds[f'fold_{fold}']['train']][ycol].astype(np.float32)
X_valid = train.iloc[kfolds[f'fold_{fold}']['valid']][feature_names]
Y_valid = train.iloc[kfolds[f'fold_{fold}']['valid']][ycol].astype(np.float32)
clf = SVR(C=20.0)
clf.fit(X_train, Y_train)
pred_valid = clf.predict(X_valid)
valid_rmse = mean_squared_error(Y_valid, pred_valid, squared=True)
pred = clf.predict(test[feature_names])
return pred, valid_rmse
这里针对计算完成的结果中的训练集和验证集进行进一步的训练,从而减少mse误差。
引申:这里是不是用svr模型进行训练之前的预测结果和验证集合之后,是不是可以再加入个线性层再进行进一步的训练?
更加深入的网络结构内容
class Model(nn.Module):
def __init__(self, ):
super().__init__()
cfg = AutoConfig.from_pretrained(config.MODEL_PATH)
cfg.update({"output_hidden_states": True,
"hidden_dropout_prob": 0.0,
"layer_norm_eps": 1e-7})
self.roberta = AutoModel.from_pretrained(config.MODEL_PATH, config=cfg)
dim = self.roberta.pooler.dense.bias.shape[0]
self.dropout = nn.Dropout(p=0.2)
self.high_dropout = nn.Dropout(p=0.5)
n_weights = 12
weights_init = torch.zeros(n_weights).float()
weights_init.data[:-1] = -3
self.layer_weights = torch.nn.Parameter(weights_init)
self.attention = nn.Sequential(
nn.Linear(768, 768),
nn.Tanh(),
nn.Linear(768, 1),
nn.Softmax(dim=1)
)
self.cls = nn.Sequential(
nn.Linear(dim, 6)
)
init_params([self.cls, self.attention])
def forward(self, input_ids, attention_mask):
roberta_output = self.roberta(input_ids=input_ids,
attention_mask=attention_mask)
cls_outputs = torch.stack(
[self.dropout(layer) for layer in roberta_output[2][-12:]], dim=0
)
cls_output = (
torch.softmax(self.layer_weights, dim=0).unsqueeze(1).unsqueeze(1).unsqueeze(1) * cls_outputs).sum(
0)
logits = torch.mean(
torch.stack(
[torch.sum(self.attention(self.high_dropout(cls_output)) * cls_output, dim=1) for _ in range(5)],
dim=0,
),
dim=0,
)
return self.cls(logits)
这里仔细解析一下里面的结构模型内容
roberta_output = self.roberta(input_ids=input_ids,attention_mask=attention_mask)
输出的内容为
BaseModelOutputWithPoolingAndCrossAttentions(last_hidden_state=tensor([[[ 0.0504, -0.0985, 0.1085, ..., 0.0519, -0.3117, 0.0442],
[ 0.0505, -0.0948, 0.1074, ..., 0.0558, -0.3039, 0.0448],
[ 0.0459, -0.0936, 0.1043, ..., 0.0533, -0.3052, 0.0388],
[ 0.0428, -0.0998, 0.1065, ..., 0.0606, -0.3106, 0.0431],
[ 0.0491, -0.0969, 0.1106, ..., 0.0586, -0.3119, 0.0411]]],
grad_fn=<NativeLayerNormBackward>), pooler_output=tensor([[-4.6556e-02, -1.5395e-01, 5.9907e-03, -7.4320e-03, -9.8382e-02,
............
hidden_states=(tensor([[[ 1.1177, -0.3298, -0.1515, ..., -0.3945, 0.2490, 0.7932],
[-1.0744, -0.1401, 0.5151, ..., -0.7413, 0.7724, -0.2714],
[ 0.4775, -0.5416, -0.5520, ..., -1.6653, -0.1933, -0.3934],
[ 0.0323, -1.0438, 0.3738, ..., -0.0243, -0.1542, -0.2247],
[-0.2077, -0.0289, 0.4554, ..., -0.9181, -0.5198, 0.8601]]],
grad_fn=<NativeLayerNormBackward>), tensor([[[ 0.8476, 0.8109, 0.5727, ..., 0.2524, -0.9158, 0.8542],
[-0.7666, 1.4002, 0.6614, ..., 0.5026, 0.0329, 0.0355],
[ 0.4310, 0.2886, -0.0404, ..., -0.8841, -0.8534, -0.0089],
[ 0.0394, 0.5218, 0.9437, ..., 0.9057, -1.0168, 0.2456],
[ 0.3211, 1.2479, 1.5039, ..., 0.1696, -0.5442, 0.8827]]],
grad_fn=<NativeLayerNormBackward>),
............
接下来取出后面12个transformers网络层的输出并且拼接在一起构成
cls_outputs = torch.stack(
[self.dropout(layer) for layer in roberta_output[2][-12:]], dim=0
)
这里构成的输出内容为
cls_output = (12,1,5,768)
接下来使用权重self.layer_weights对中间的attention的结果赋上权重,这里self.layer_weights原先的值为
self.layer_weights = tensor([-3., -3., -3., -3., -3., -3., -3., -3., -3., -3., -3., 0.]
经过softmax之后得到真正的权重
torch.softmax(self.layer_weights) =
tensor([0.0322, 0.0322, 0.0322, 0.0322, 0.0322, 0.0322,
0.0322, 0.0322, 0.0322, 0.0322, 0.0322, 0.6461], grad_fn=<SoftmaxBackward>)
乘上之后计算结果
current_multiply = torch.softmax(self.layer_weights,dim=0).unsqueeze(1).unsqueeze(1).unsqueeze(1)*cls_outputs
计算出加权之后的结果
(12,1,1,1)*(12,1,5,768) = (12,1,5,768)
然后再将加权之后的结果在dim=0上混合
cls_output = (torch.softmax(self.layer_weights, dim=0).unsqueeze(1).unsqueeze(1).unsqueeze(1) * cls_outputs).sum(0)
获得的结果
(1,5,768)
这里就是将之前加权得到的结果相加求和
接下来调用后续代码的内容
logits = torch.mean(
torch.stack(
[torch.sum(self.attention(self.high_dropout(cls_output)) * cls_output, dim=1) for _ in range(5)],dim=0,
),dim=0,
)
这里先分析内层的代码,之前输出的cls_output = (1,5,768),经过self.high_dropout和self.attention内容的调用
self.attention(self.high_dropout(cls_output))
这里的self.attention的内容可以将(1,5,768)变成(1,5,1),这里的(1,5,1)实际上作为的是每一个数值的权重
由于计算出来的是每一个数值的权重,所以接下来的操作就顺理成章了
torch.sum(self.attention(self.high_dropout(cls_output)) * cls_output, dim=1)
这里先用之前计算出来的权重乘上cls_output计算每一个数值的维度矩阵,然后再进一步进行求和
1.计算权重
self.attention(self.high_dropout(cls_output))*cls_output
2.求和(相当于加权求和)
torch.sum(self.attention(self.high_dropout(cls_output))*cls_output,dim=1)
接下来分析外面的torch.mean和torch.stack内容,个人理解这里是为了去除调self.high_dropout的影响,所以计算五次然后求平均
logits = torch.mean(
torch.stack(.....,dim=0),dim=0,
)
这两个同时去掉的话,结果与都加上相差也并不大
这个与我的模型对比的优势在于此模型更多的关注到每一个字的维度矩阵,同时又加入了dropout多次取平均的思想,而我的模型更多的关注了开头的标志cls的维度矩阵内容。
大佬思路2:
1.清洗标点符号
原文中有一些数据掺杂着中文的标点符号,是 BERT vocab.txt 里面没有的,这些字符训练时候会变成[UNK]。所以进行清洗替换,尽量避免出现[UNK]
具体的中文标点符号如下文所示:
清洗过程:
w_str = w_str.replace('—', "-")
w_str = w_str.replace('“', "'")
w_str = w_str.replace('”', "'")
w_str = w_str.replace('"', "'")
w_str = w_str.replace('[', "")
w_str = w_str.replace(']', "")
2.划分数据
A方案:测试集出现的样本id,都是训练集里没出现过的剧本id,所以我们再对训练数据做验证集划分时,使用剧本id 进行划分。划分五折训练。
B方案:使用 剧本id+场景id进行划分。理由是这样可以使数据每一折的训练数据数量差不多相同。同样也是划分五折训练。
上面的方案B方案提交的效果更好
3.!!!预训练时的trick!!!
1.模型参数初始化的时候加载开源的权重参数(这个肯定是要加载的,不然你从头开始训练?)
2.factor设为10,增加预训练样本多
3.预训练数据,增加情感信息(这点很重要,预训练与后面微调的效果匹配上)
比如下面的一段文字内容
1171_0001_A_11 o2笑了笑:军礼不是这么敬的。五指并拢,大臂带动小臂,举到齐眉。 o2 0,1,0,0,0,0
首先定义原始的情感信息list
emotion_list = ["爱,","乐,","惊,","怒,","恐,","哀,"] # 情感位置
level_list = ["没有", "有点", "很", "非常"]
上面的数据经过处理之后,生成的预训练语料为
o2笑了笑:军礼不是这么敬的。五指并拢,大臂带动小臂,举到齐眉。o2有点乐。
注意这里的有点乐进行预训练的时候每次都需要被mask掉,这样才能加强语料对finetune的效果。
这里的预训练加入了上下句的内容,添加的句子预训练情感紧跟在句子的后面。
注意这里的预训练使用的maxlen跟finetune使用的maxlen长度并不一样,预训练使用的maxlen长度为256,finetune使用的maxlen长度为512,由此也可以看出来预训练的maxlen对于finetune中的maxlen内容没有影响,因为预训练主要是调整embedding以及后面的transformers各层的参数,所以预训练的maxlen不需要与finetune的maxlen必须匹配上
作者一些trick总结放在下面:
有用的 trick:
使用回归任务,而不是分类任务(0.68 -> 0.70);
使用Large模型(0.70 -> 0.704);
使用FGM对抗训练(0.704 -> 0.706);
Nezha 和 MacBert 模型融合(0.706 -> 0.710);
使用二次预训练,预训练语料增加情感信息,初始化权重加载开源权重(0.710 -> 0.713)。【该trick是单模上0.710的关键】
无用的 trick(降分)
6个情感值使用6个单模模型训练建模,不仅耗时,而且没效果;
Finetune训练时,增加前文情感信息,验证集效果非常好能达到 0.72 以上,线上提交测试集不好,因为测试集的前文情感是靠模型预测的,存在偏差;
label统一除以3,FC层使用sigmoid激活,提交时再乘以3。
BERT+MMOE
这里选定使用mask的概率作为最后的分类
构建$[CLS]
c
1
c1
c1 [u1] [u2] [u3] [u4] [u5] [MASK] [u6] [u7] [u8] [u9] [u10] [SEP] 上文
c
1
c1
c1下文[SEP]$
其中[MASK]固定为第八个位置,然后取出[MASK]的内容进行计算分类(类似于取出[CLS]进行计算分类一样)
这里挂一下他研究出来的MMOE后续模型代码
class MMOE(nn.Module):
def __init__(self):
dim=1024
super(MMOE, self).__init__()
self.norm=nn.BatchNorm1d(dim)
self.exports=nn.ModuleList([nn.Sequential(nn.Linear(dim, 2048),nn.BatchNorm1d(2048),nn.ReLU(True)
,nn.Linear(2048, dim),nn.BatchNorm1d(dim),nn.ReLU(True))
for i in range(6)])
self.weights=nn.ModuleList([nn.Sequential(nn.Linear(dim, 6))
for i in range(6)])
self.fc=nn.ModuleList([nn.Sequential(nn.Linear(dim, 1))
for i in range(6)])
def forward(self,x):
#专家网络的输出
weights=[]
exports_out=[]
# or_x=x
x=self.norm(x)
for i in range(6):
weight=F.softmax(self.weights[i](x),dim=-1) # B,6
weights.append(weight)
exports_out.append(self.exports[i](x).unsqueeze(1))
exports_out=torch.cat(exports_out,dim=1) # B,6,dim
# print(exports_out.size())
# print(weights[0].size())
res=[]
for i in range(6):
feat=torch.sum(exports_out*weights[i].unsqueeze(2),dim=1)
# feat=torch.cat([feat,or_x],dim=-1)
res.append(self.fc[i](feat))
res=torch.cat(res,dim=-1)
return res
NEZHA常规模型
后续接上线性层,不多讲
class ContextAttentionLayer(nn.Module):
def __init__(self, embedding_dim, drop_ratio=0):
super(ContextAttentionLayer, self).__init__()
self.linear = nn.Sequential(
nn.Linear(embedding_dim, embedding_dim//2),
nn.ReLU(),
nn.Dropout(drop_ratio),
nn.Linear(embedding_dim//2, 1),
)
def forward(self, x):
out = self.linear(x)
weight = torch.nn.functional.softmax(out, dim=1)
return weight
NEZHA+attention
还可以取出最后的[sep]进行分类操作
这里分别制作了六个不同的线性层
self.bert = NeZhaModel.from_pretrained(BERT_MODEL_PATH + 'pytorch_model.bin', config=config)
self.dropout = nn.Dropout(0.5)
self.dropouts = nn.ModuleList([nn.Dropout(0.5) for i in range(dropout_num)])
self.out_love = nn.Linear(config.hidden_size, 1)
self.out_joy = nn.Linear(config.hidden_size, 1)
self.out_fright = nn.Linear(config.hidden_size, 1)
self.out_anger = nn.Linear(config.hidden_size, 1)
self.out_fear = nn.Linear(config.hidden_size, 1)
self.out_sorrow = nn.Linear(config.hidden_size, 1)
self.contextAttention = ContextAttentionLayer(2 * config.hidden_size, 0.2)
SKEP+上下文特征融合
SKEP是基于情感知识增强的预训练算法,利用无监督挖掘的海量情感知识构建预训练目标,让模型更好理解情感语义,可为各类情感分析任务提供统一且强大的情感语义表示。
们利用最后一层[CLS]隐藏层表示整个文本对,然后利用门控网络融合”上文+当前文本“和”当前文本+下文“的[CLS]隐藏层作为下游预测任务的输入。
也就是说上文+当前文本和当前文本+下文作为两种分案
具体内容查看代码
def forward(self, input_ids, token_type_ids, role_index=None, contexts=None):
last_seq, pooled_output_1 = self.bert(input_ids, token_type_ids)
x, y, _ = contexts[0]
_, pooled_output_2 = self.bert(x, y) # self.get_batch_feat(role_index, last_seq, pooled_output)
# contexts_attens = []
# context_outputs = []
# for x,y,r in contexts:
# seq, outs = self.bert(input_ids=x)
# context_role_features = outs # self.get_batch_feat(r, seq, outs)
# context_outputs.append(context_role_features)
# context_outputs = paddle.stack(context_outputs, axis=1)
# current_output = paddle.stack([target_role_output]*len(contexts), axis=1)
# at_wt = self.contextAttention(paddle.concat([current_output, context_outputs], axis=2))
# context_with_attention = paddle.bmm(paddle.transpose(at_wt, [0,2,1]), context_outputs).squeeze()
task_output = pooled_output_1 + pooled_output_2 # + context_with_attention
ernie_output = self.dropout(task_output)
love = self.out_love(ernie_output)
joy = self.out_joy(ernie_output)
fright = self.out_fright(ernie_output)
anger = self.out_anger(ernie_output)
fear = self.out_fear(ernie_output)
sorrow = self.out_sorrow(ernie_output)
return {
'love': love, 'joy': joy, 'fright': fright,
'anger': anger, 'fear': fear, 'sorrow': sorrow,
}
pooled_output_1 为整个文本,pooled_output_2为上文加本文的句向量和本文加下文的句向量拼接在一起。
预训练的时候盖的情感极性词语不同
本赛题应该的正确路线
搭建模型(选用xxx-large)->单模多折->尝试预训练和多种模型->尝试simcse、rdropout、对抗、sigmoid激活、flooding、加入不同的上文等策略->模型融合->拿钱
每次训练的过程数据随机化一下
固定的数据训练顺序可能会影响模型的效果,如果在训练的过程之中都能够时不时地random一下数据,能够有效地改善训练最后的结果。
融合模型的时候可以加入相应的权重参数在验证集合之上跑最高的分数
def calculate_data(i,j):
for k in range(0,31):
for u in range(0,31):
v = 100-i-j-k-u
for z in range(0,30):
z = z*0.1
less_toxic_wt = np.array(less_toxic1).dot(i)+np.array(less_toxic2).dot(j)+np.array(less_toxic3).dot(k)+
np.array(less_toxic4).dot(u)+np.array(less_toxic5).dot(v)
less_toxic_wt = less_toxic_wt+z*p1_wt
#!!!注意这里的z是乘在哪个部位的 submission时保持一致
more_toxic_wt = np.array(more_toxic1).dot(i)+np.array(more_toxic2).dot(j)+np.array(more_toxic3).dot(k)+
np.array(more_toxic4).dot(u)+np.array(more_toxic5).dot(v)
more_toxic_wt = more_toxic_wt+z*p2_wt
wts_acc.append((i,j,k,u,v,z,
np.round((less_toxic_wt < more_toxic_wt).mean() * 100,2))
)
总结
这个比赛与常规的分类比赛有着一定的特殊性
1.不同本预测难度不一样
2.使用mse作为损失函数
3.特征更多,比如上文,本文中的角色
因此有一定的特殊性,但是本质上又属于一个文本分类问题,因此又有一些文本分类可以尝试的策略,希望以后再遇到类似的问题,能够处理的更加合理。
最后
以上就是勤恳大叔最近收集整理的关于剧本角色情感分析赛后总结的全部内容,更多相关剧本角色情感分析赛后总结内容请搜索靠谱客的其他文章。








发表评论 取消回复