一、各个角色解释
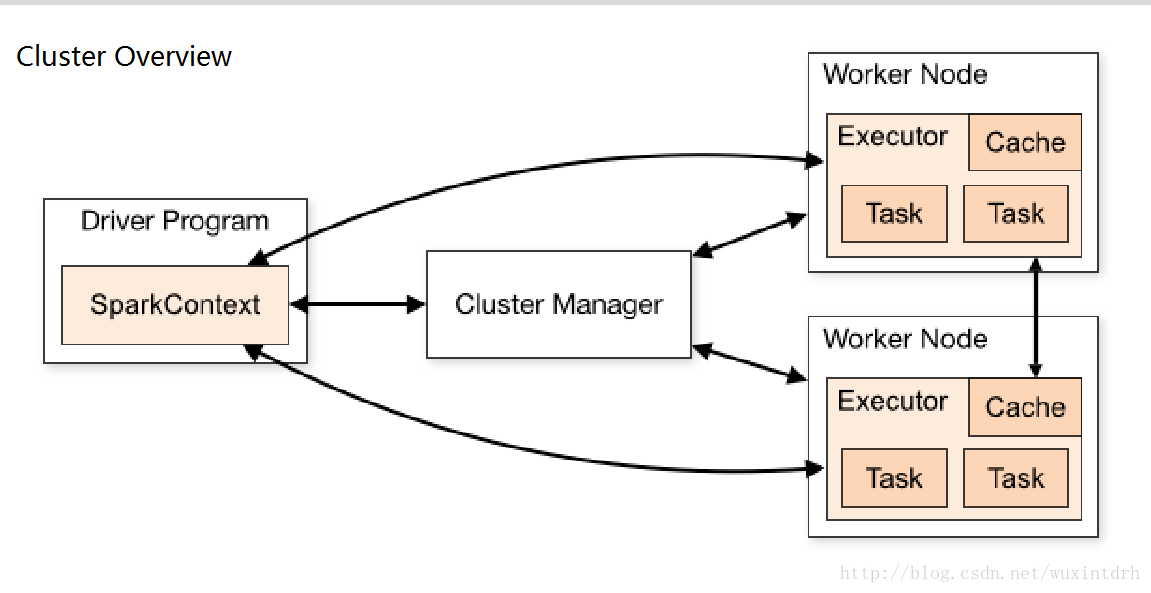
- Application 基于Spark的应用程序,包含了driver程序和 集群上的executor
- Driver Program 运⾏行main函数并且新建SparkContext的 程序
- Cluster Manager 在集群上获取资源的外部服务(例如 standalone,Mesos,Yarn )
- Worker Node 集群中任何可以运⾏行应⽤用代码的节点
- Executor是在⼀一个worker node上为某应⽤用启动的⼀一 个进程,该进程负责运⾏行任务,并且负责将数据存在内存或 者磁盘上。每个应⽤用都有各⾃自独⽴立的executor
- Task 被送到某个executor上的工作单元
- Job 包含很多任务的并行计算,可以看做和Spark的action 对应。一个Action操作产生一个Job
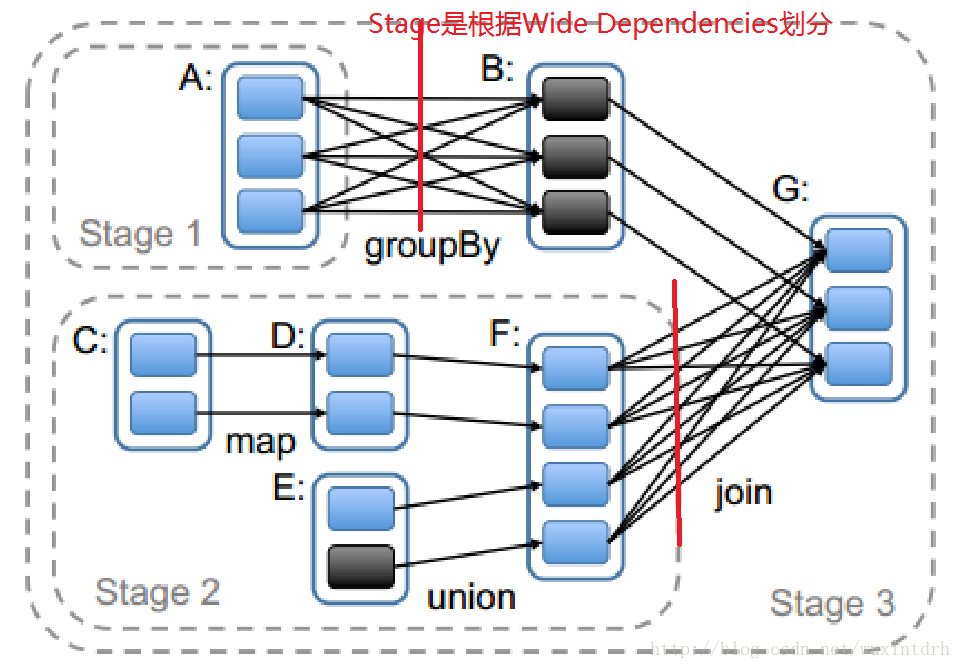
- Stage⼀一个Job会被拆分很多组任务,每组任务被称为 Stage(就像Mapreduce分map任务和reduce任务⼀一样)。一个transformation操作划分一个Stage, stage的划分是通过宽依赖。在下图中,我们可以看到:
二、Spark任务调度器
2.1、调度器根据RDD的结构信息为每个Action操作确定有效的执行计划 。调度器的接口是runJob函数,参数为RDD及其分区集,和 一个RDD分区上的函数。该接口足以表示Spark中的所有动作 (即count、collect、save等)。
2.2、总的来说,我们的调度器跟Dryad类似,但我们还考虑了哪些 RDD分区是缓存在内存中的。调度器根据目标RDD的Lineage 图创建一个由 stage构成的有向无环路图(DAG)。每个 stage内部尽可能多地包含一组具有窄依赖关系的转换,并将 它们流水线并行化(pipeline)。
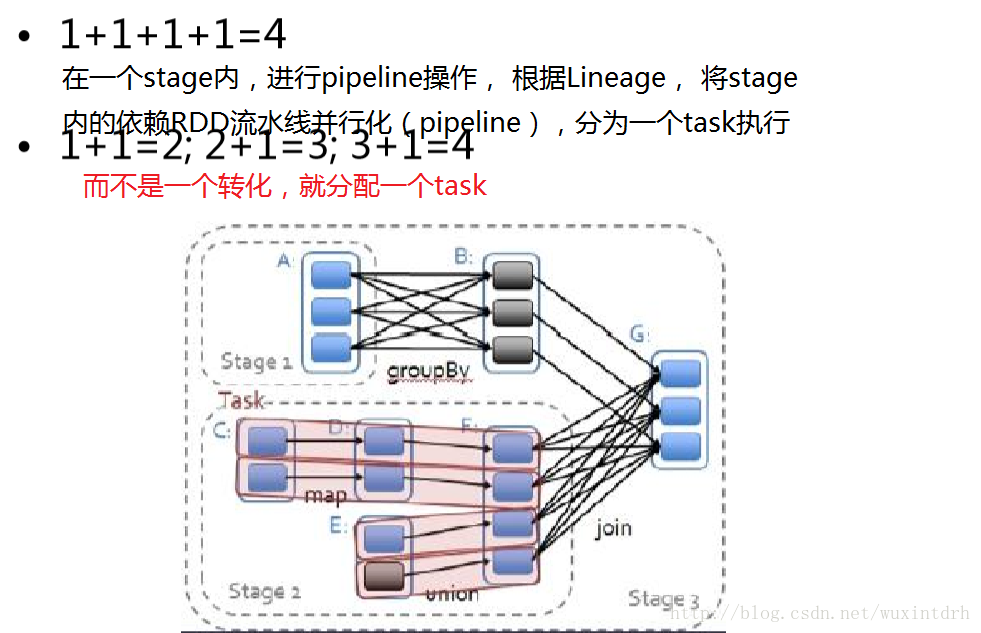 ### stage的边界有两种情况:
### stage的边界有两种情况:
- 一是宽依赖上的Shuffle操作;
- 二是已缓存分区,它可以缩短 父RDD的计算过程。
父RDD完成计算后,可以在 stage内启动一组任务计算丢失的分区。
三、任务调度
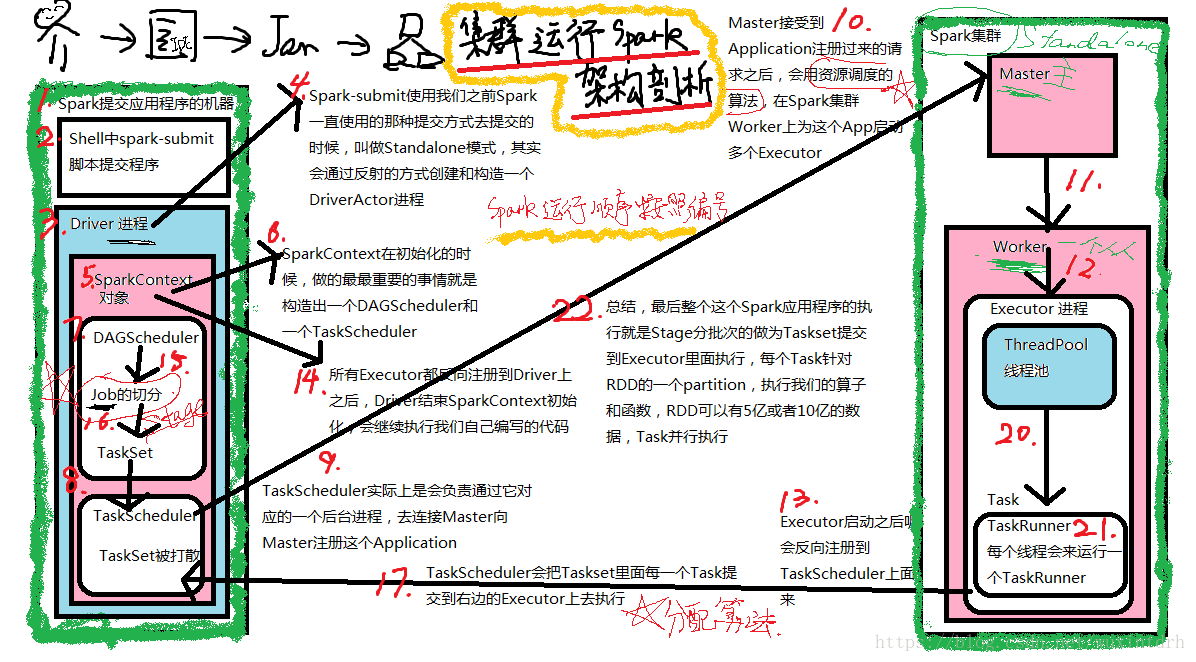
3.1standlone模式执行架构
3.2、yarn-client模式执行架构
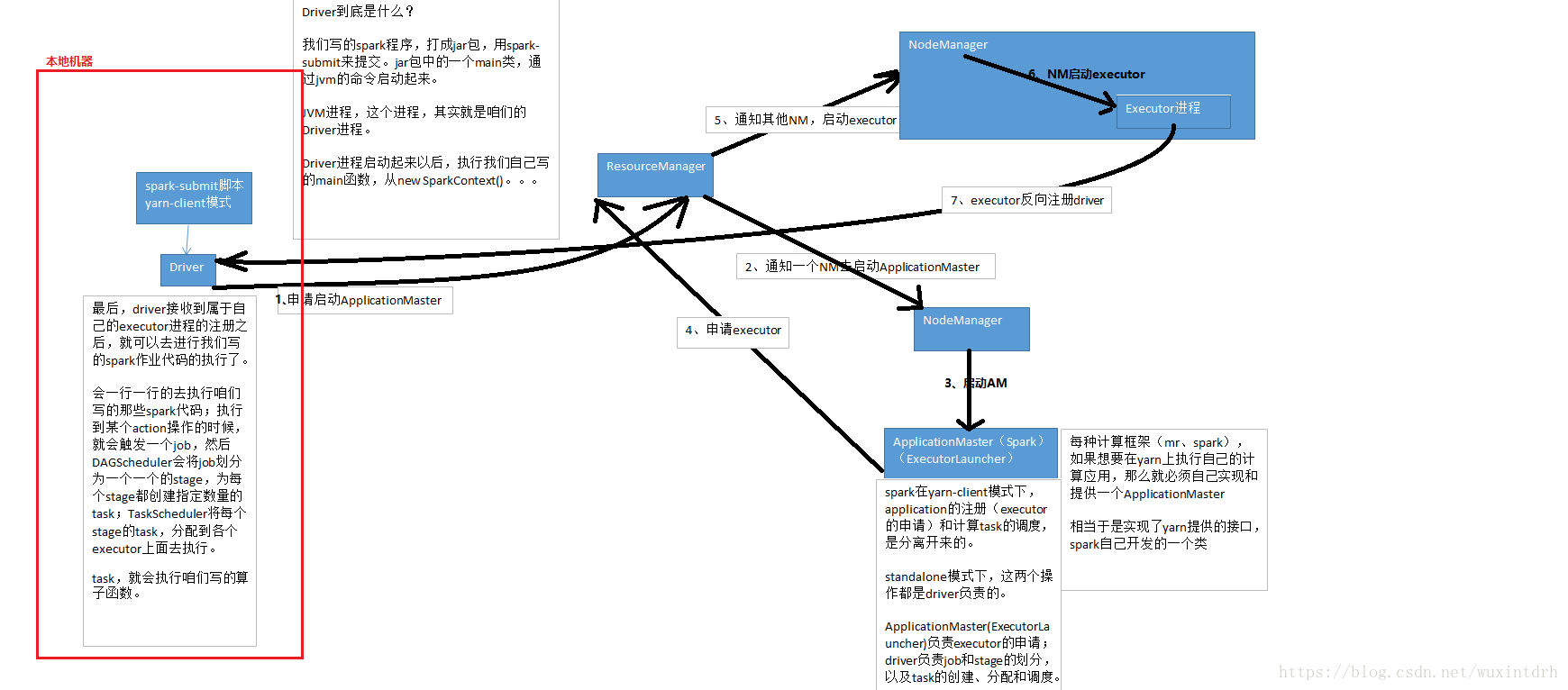
3.2.1、yarn-client模式下,会产生什么样的问题呢?
由于咱们的driver是启动在本地机器的,而且driver是全权负责所有的任务的调度的,也就是说要跟yarn集群上运行的多个executor进行频繁的通信(中间有task的启动消息、task的执行统计消息、task的运行状态、shuffle的输出结果)。
比如你的executor有100个,stage有10个,task有1000个。每个stage运行的时候,都有1000个task提交到executor上面去运行,平均每个executor有10个task。接下来问题来了,driver要频繁地跟executor上运行的1000个task进行通信。通信消息特别多,通信的频率特别高。运行完一个stage,接着运行下一个stage,又是频繁的通信。
在整个spark运行的生命周期内,都会频繁的去进行通信和调度。所有这一切通信和调度都是从你的本地机器上发出去的,和接收到的。这是最要人命的地方。你的本地机器,很可能在30分钟内(spark作业运行的周期内),进行频繁大量的网络通信。那么此时,你的本地机器的网络通信负载是非常非常高的。会导致你的本地机器的网卡流量会激增!!!
你的本地机器的网卡流量激增,当然不是一件好事了。因为在一些大的公司里面,对每台机器的使用情况,都是有监控的。不会允许单个机器出现耗费大量网络带宽等等这种资源的情况。运维人员。可能对公司的网络,或者其他(你的机器还是一台虚拟机),对其他机器,都会有负面和恶劣的影响。
3.2.2、解决的方法:
实际上解决的方法很简单,就是心里要清楚,yarn-client模式是什么情况下,可以使用的?yarn-client模式,通常咱们就只会使用在测试环境中,你写好了某个spark作业,打了一个jar包,在某台测试机器上,用yarn-client模式去提交一下。因为测试的行为是偶尔为之的,不会长时间连续提交大量的spark作业去测试。还有一点好处,yarn-client模式提交,可以在本地机器观察到详细全面的log。通过查看log,可以去解决线上报错的故障(troubleshooting)、对性能进行观察并进行性能调优。
实际上线了以后,在生产环境中,都得用yarn-cluster模式,去提交你的spark作业。
yarn-cluster模式,就跟你的本地机器引起的网卡流量激增的问题,就没有关系了。也就是说,就算有问题,也应该是yarn运维团队和基础运维团队之间的事情了。使用了yarn-cluster模式以后,就不是你的本地机器运行Driver,进行task调度了。是yarn集群中,某个节点会运行driver进程,负责task调度。
3.3、yarn-cluster模式执行架构
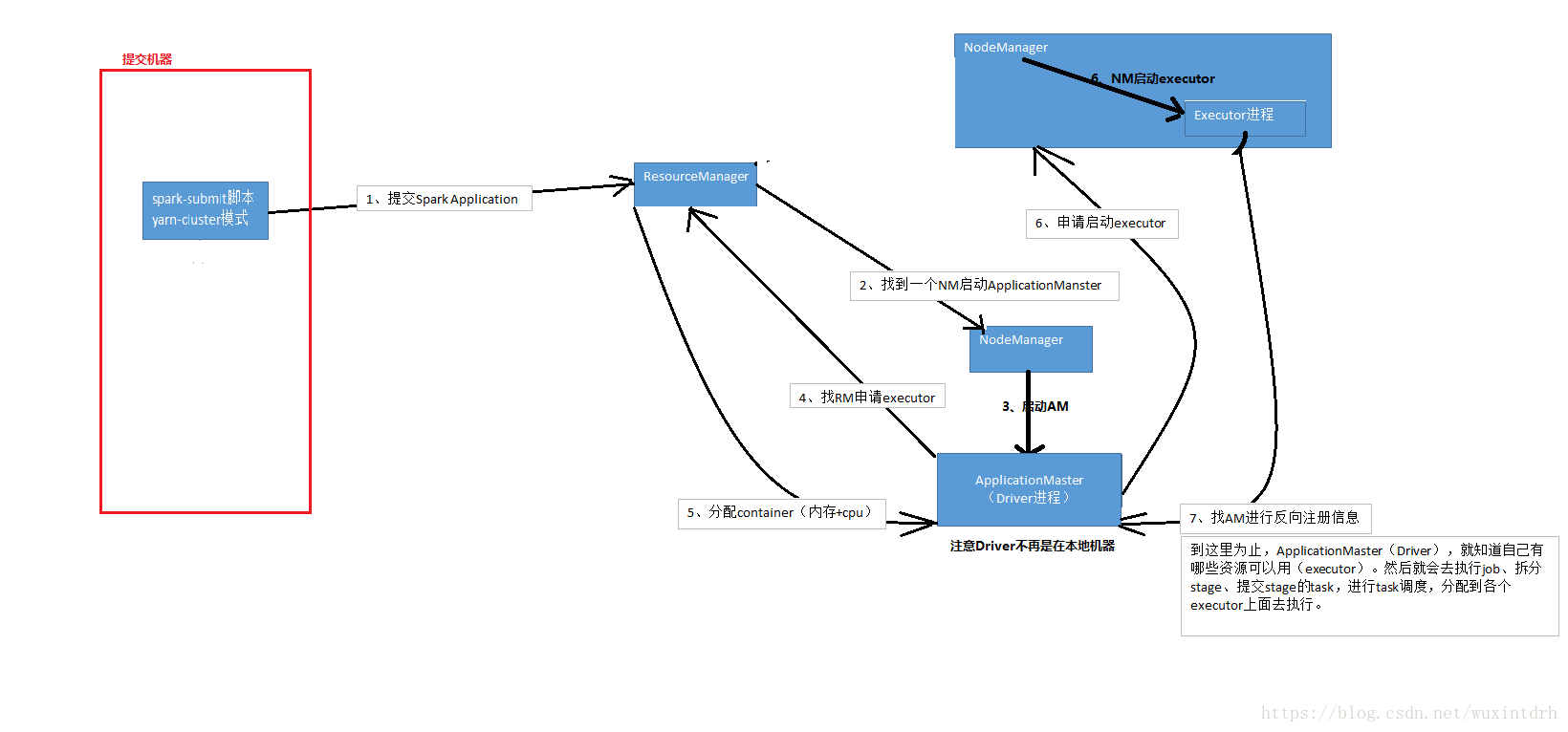
==================================
3.3.1、实践经验,碰到的yarn-cluster的问题:
有的时候,运行一些包含了spark sql的spark作业,可能会碰到yarn-client模式下,可以正常提交运行;yarn-cluster模式下,可能是无法提交运行的,会报出JVM的PermGen(永久代)的内存溢出,OOM。
yarn-client模式下,driver是运行在本地机器上的,spark使用的JVM的PermGen的配置,是本地的spark-class文件(spark客户端是默认有配置的),JVM的永久代的大小是128M,这个是没有问题的;但是呢,在yarn-cluster模式下,driver是运行在yarn集群的某个节点上的,使用的是没有经过配置的默认设置(PermGen永久代大小),82M。
spark-sql,它的内部是要进行很复杂的SQL的语义解析、语法树的转换等等,特别复杂,在这种复杂的情况下,如果说你的sql本身特别复杂的话,很可能会比较导致性能的消耗,内存的消耗。可能对PermGen永久代的占用会比较大。
所以,此时,如果对永久代的占用需求,超过了82M的话,但是呢又在128M以内;就会出现如上所述的问题,yarn-client模式下,默认是128M,这个还能运行;如果在yarn-cluster模式下,默认是82M,就有问题了。会报出PermGen Out of Memory error log。
3.3.2、如何解决这种问题?
既然是JVM的PermGen永久代内存溢出,那么就是内存不够用。咱们呢,就给yarn-cluster模式下的,driver的PermGen多设置一些。
spark-submit脚本中,加入以下配置即可:
--conf spark.driver.extraJavaOptions="-XX:PermSize=128M -XX:MaxPermSize=256M"
这个就设置了driver永久代的大小,默认是128M,最大是256M。那么,这样的话,就可以基本保证你的spark作业不会出现上述的yarn-cluster模式导致的永久代内存溢出的问题。
总结一下yarn-client和yarn-cluster模式的不同之处:
yarn-client模式,driver运行在本地机器上的;
yarn-cluster模式,driver是运行在yarn集群上某个NM节点上面的。
yarn-client会导致本地机器负责spark作业的调度,所以网卡流量会激增;
yarn-cluster模式就没有这个问题。
yarn-client的driver运行在本地,通常来说本地机器跟yarn集群都不会在一个机房的,所以说性能可能不是特别好;
yarn-cluster模式下,driver是跟yarn集群运行在一个机房内,性能上来说,也会好一些。
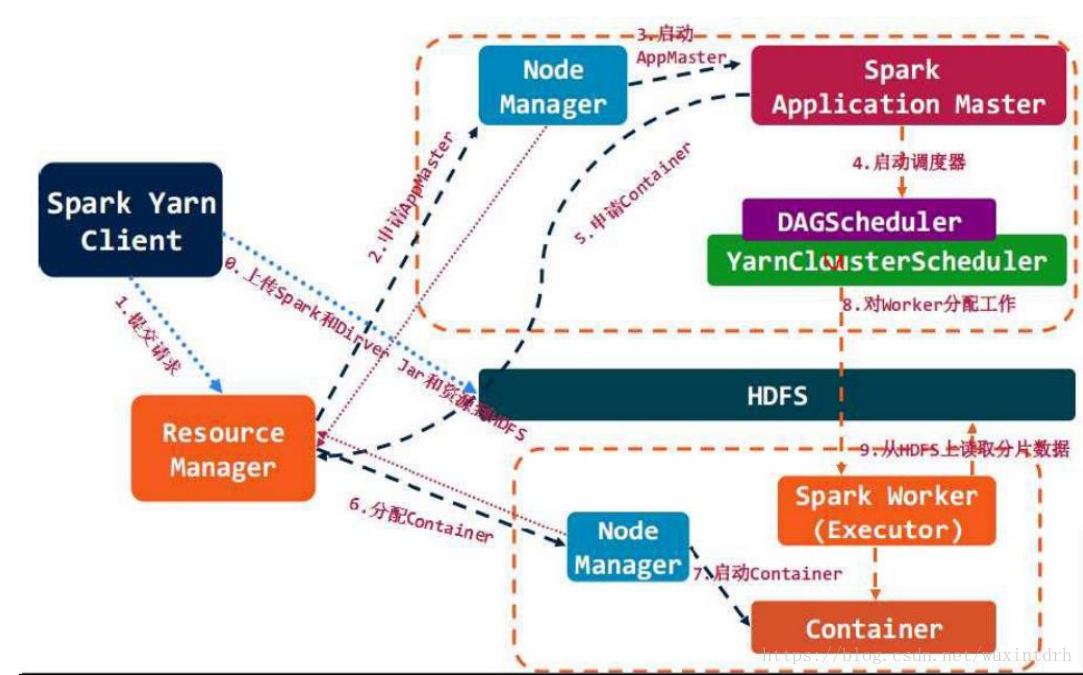
下图为流程图
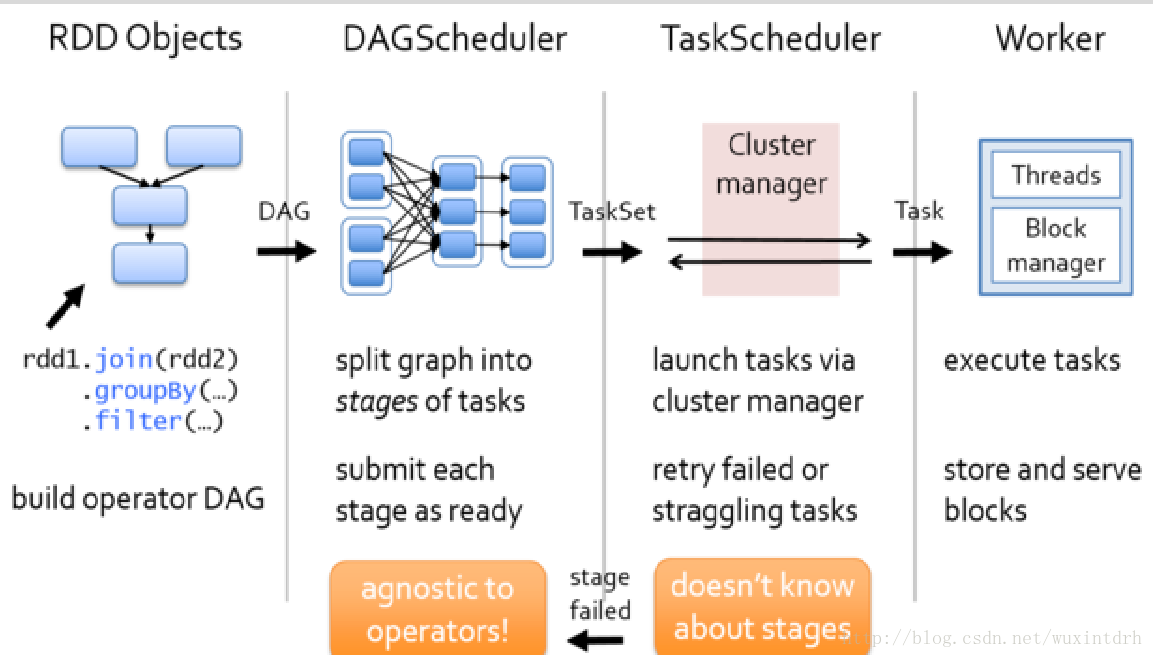
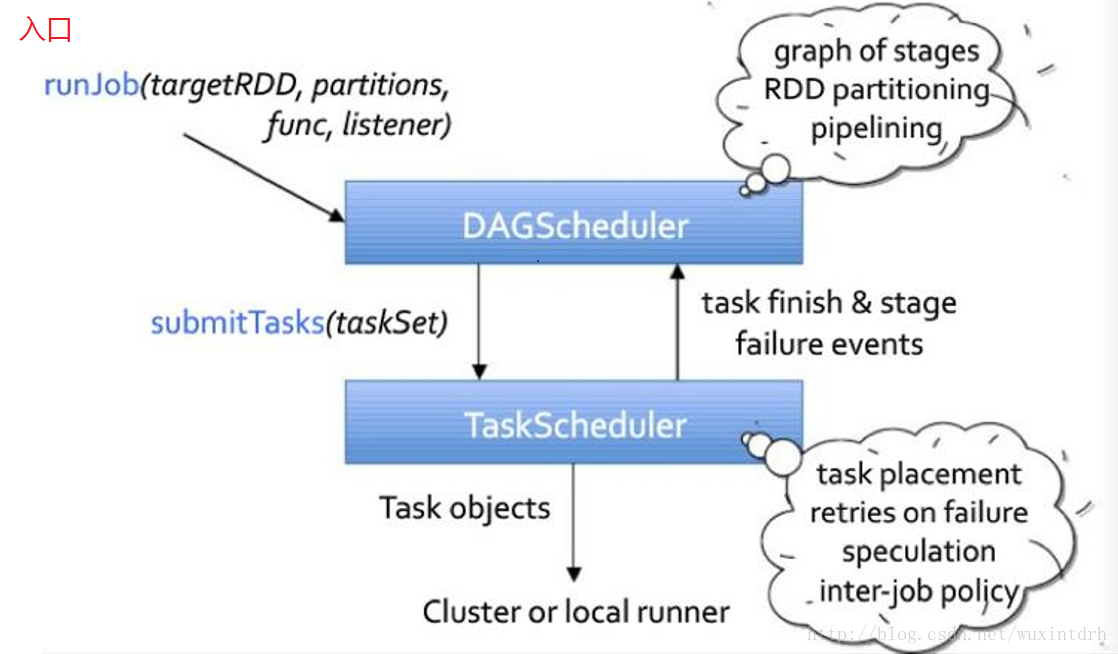
3.1、DAG Scheduler
• 基于Stage构建DAG,决定每个任务的最佳位置
• 记录哪个RDD或者Stage输出被物化
• 将taskset传给底层调度器TaskScheduler
• 重新提交shuffle输出丢失的stage
3.2、Task Scheduler
• 提交taskset(⼀一组task)到集群运⾏行并汇报结果
• 出现shuffle输出lost要报告fetch failed错误
• 碰到straggle任务需要放到别的节点上重试
• 为每一个TaskSet维护一个TaskSetManager(追踪本地性 及错误信息)
四、任务的调度
最后
以上就是善良火最近收集整理的关于Spark之任务流程和角色的全部内容,更多相关Spark之任务流程和角色内容请搜索靠谱客的其他文章。








发表评论 取消回复