简单介绍这几个概念以及方案。
Redis 缓存场景
客户端请求在缓存层命中直接返回内容,如果Miss就去存储层读取,存储层读取到数据再写入缓存层,然后再返回客户端。
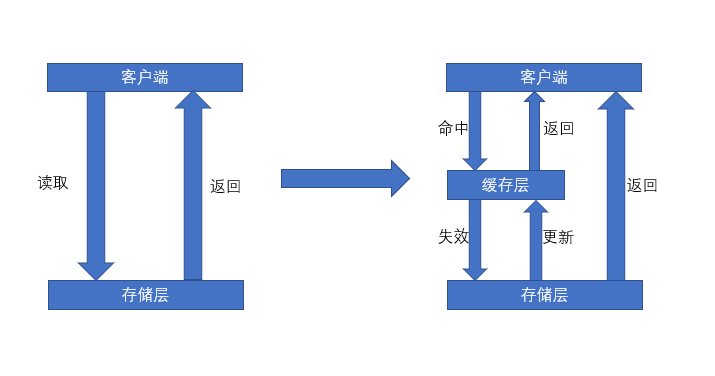
优点:加速读写效率,降低后端负载,减少存储层压力
缺点:数据不能保证一致性,代码维护成本和运维成本
主从复制
主节点数据更新后根据配置和策略,自动同步到备节点的master/slaver的机制,主节点负责写数据,从节点负责读数据,主节点定期把数据同步到从节点保证数据的一致性。
优点:
- 读写分离
- 容灾恢复
缺点:
- 主从复制,若主节点出现问题,则不能提供服务,需要人工修改配置将从变主
- 主从复制主节点的写能力单一,能力有限
- 单机节点的存储能力也有限
哨兵模式
哨兵机制的出现是为了解决主从复制的缺点,能够后台监控主节点是否故障,如果故障了根据投票数自动将从节点转换主节点。
缓存穿透
在查询一个不存在的数据时,在缓存层查不到数据则会去访问存储层,且返回的空数据也不会写入缓存层。这将
导致不存在的数据每次查询都必定会到存储层查询,缓存层失去了存在的意义。当大量恶意查询不存在数据时,可能因为频繁访问导致数据库宕机。
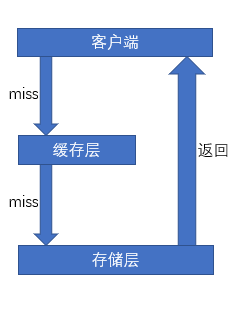
- 方案:
- 最为常简的是采用布隆过滤器,将所有可能存在的数据哈希到一个足够发的 bigmap 中,一个一定不存在的数据会被该 bigmap 拦截掉,从而避免对底层存储系统造成查询压力。
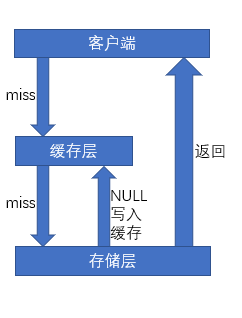
- 【推荐】
如果一个查询返回的数据为空(无论数据为空,或是系统故障),将空结果进行缓存,设置一个最长不超过五分钟的过期时间。这样过期时间内查询的时候就会直接在缓存层获取,并直接返回null。
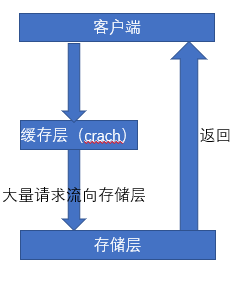
雪崩效应
设置缓存时采用了相同的过期时间,导致缓存在某时刻同时失效,请求全部转向DB,DB瞬时压力过重雪崩。- Redis宕机,导致客户端的请求之间流向DB,拖垮DB。
- 问题一的方案
- 在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。
- 【推荐】 就是
将缓存失效时间分散开,在原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
- 问题二的方案
- 保持缓存层服务器的高可用。
–监控、集群、哨兵。当一个集群里面有一台服务器有问题,让哨兵踢出去。 - 依赖隔离组件为后端限流并降级。
比如推荐服务中,如果个性化推荐服务不可用,可以降级为热点数据。 - 提前演练。
演练 缓存层crash后,应用以及后端的负载情况以及可能出现的问题。 对此做一些预案设定。
- 保持缓存层服务器的高可用。
热点KEY
类似微博热搜,一段时间内疯狂请求一个key,导致redis崩溃
解决方式:设置二级缓存,可以用hashmap存,后端处理捕获热点key,将热点key数据存入内存中,不再请求redis。减缓缓存压力
最后
以上就是鲜艳巨人最近收集整理的关于Redis | 主从复制、哨兵模式、缓存穿透、雪崩、热点KEY的全部内容,更多相关Redis内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复