参考链接:
- https://blog.csdn.net/hyzhyzhyz12345/article/details/104181606
- https://www.jianshu.com/p/a68288613a0f
- https://blog.csdn.net/u012526436/article/details/87882985
- https://www.jianshu.com/p/6c2bfa1848f2
- https://zhuanlan.zhihu.com/p/57251615
- https://www.jiqizhixin.com/articles/2019-08-26-12
GPT1
全称:Generative Pre-Training 1.0
论文:《Improving Language Understanding by Generative Pre-Training》
概述
GPT1采用了NLP中常用的“预训练+微调(generative pre-training + discriminative fine-tuning)”的模式。
由于LSTM等结构在捕获长期依赖的局限性,GPT1的模型是Transformer的Decoder部分,其采用的self-attention机制较好地弥补了LSTM的弊端。
框架
1.无监督的预训练阶段(Unsupervised pre-training)
给定一个无监督的(无标签)tokens语料库 U = { u 1 , ⋅ ⋅ ⋅ , u n } mathrm{U}=left {u_{1},cdot cdot cdot ,u_{n}right } U={u1,⋅⋅⋅,un},选择标准的语言模型目标函数(即根据前 k k k个词预测下一个词),需最大化:
L 1 ( U ) = ∑ i l o g P ( u i ∣ u i − k , ⋅ ⋅ ⋅ , u i − 1 ; Θ ) L_{1}left ( mathrm{U}right )=sum_{i}^{}log Pleft ( u_{i}|u_{i-k},cdot cdot cdot ,u_{i-1};Theta right ) L1(U)=∑ilog P(ui∣ui−k,⋅⋅⋅,ui−1;Θ)
其中,
k
k
k为token的上下文窗口大小,条件概率
P
P
P使用参数为
Θ
Theta
Θ的神经网络建模。GPT1的结构示意图如下:
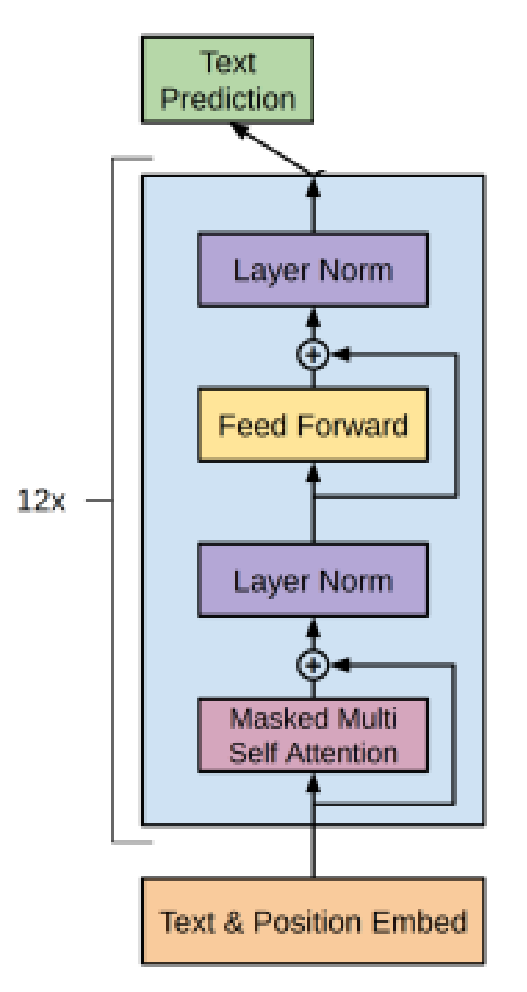
1)输入为前k个词和位置的embedding
h 0 = U W e + W p h_{0}=UW_{e}+W_{p} h0=UWe+Wp
其中, U = ( u − k , ⋅ ⋅ ⋅ , u − 1 ) U=left ( u_{-k},cdot cdot cdot ,u_{-1}right ) U=(u−k,⋅⋅⋅,u−1)为token上下文one-hot向量,则 U W e UW_{e} UWe为上下文对应的embedding。
2)经过n层transformer-decoder层(12层)
h l = t r a n s f o r m e r b l o c k ( h l − 1 ) ∀ l ∈ [ 1 , n ] h_{l}=transformer_blockleft ( h_{l-1}right ) forall lin left [ 1,nright ] hl=transformerblock(hl−1) ∀l∈[1,n]
3)乘上一个token embedding矩阵,通过softmax得到概率
P ( u ) = s o f t m a x ( h n W e T ) Pleft ( uright )=softmaxleft ( h_{n}W_{e}^{T}right ) P(u)=softmax(hnWeT)
2.有监督的微调阶段(Supervised fine-tuning)
微调过程的示意图如下:
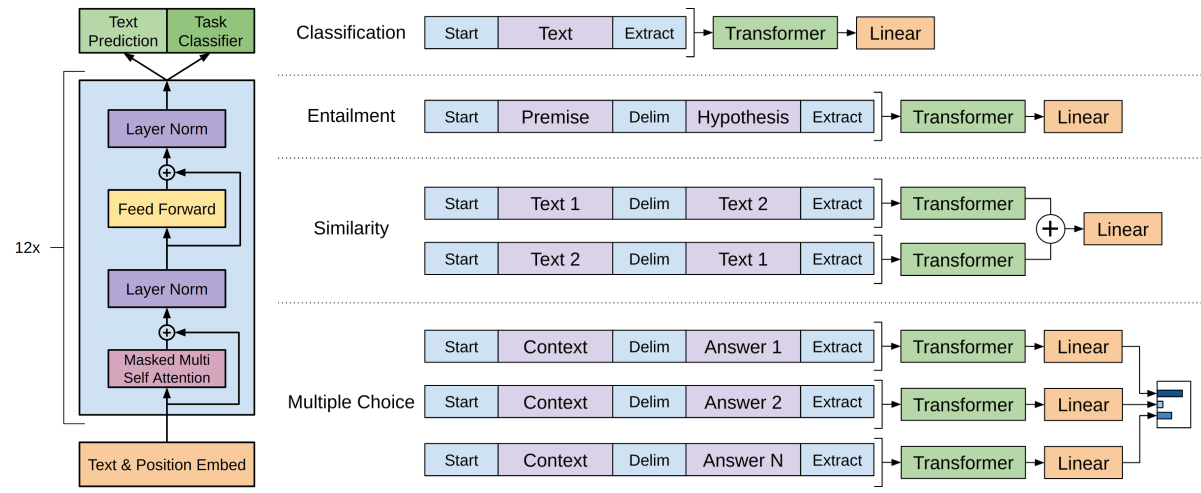
对比预训练阶段,可以看出,只是多增加了“Task Classifier”模块。
对于有监督的训练,数据集 C textrm{C} C每个样本自然包括一个输入tokens序列 x 1 , ⋅ ⋅ ⋅ , x m x^{1},cdot cdot cdot ,x^{m} x1,⋅⋅⋅,xm和对应的标签 y y y,具体任务相应的目标函数为:
L 2 ( C ) = ∑ ( x , y ) l o g P ( y ∣ x 1 , ⋅ ⋅ ⋅ , x m ) L_{2}left ( textrm{C}right )=sum_{left ( x,yright )}^{}log Pleft ( y|x^{1},cdot cdot cdot ,x^{m}right ) L2(C)=∑(x,y)log P(y∣x1,⋅⋅⋅,xm)
其中, P ( y ∣ x 1 , ⋅ ⋅ ⋅ , x m ) = s o f t m a x ( h l m W y ) Pleft ( y|x^{1},cdot cdot cdot ,x^{m}right )=softmaxleft ( h_{l}^{m}W_{y}right ) P(y∣x1,⋅⋅⋅,xm)=softmax(hlmWy), h l m h_{l}^{m} hlm为最后一个token x m x^{m} xm对应的最后一层transformer-decoder的输出。所以需要额外调整的参数只有 W y W_{y} Wy。
最终,微调阶段的目标函数为:
L 3 ( C ) = L 2 ( C ) + λ ∗ L 1 ( C ) L_{3}left ( textrm{C}right )=L_{2}left ( textrm{C}right )+lambda ast L_{1}left ( textrm{C}right ) L3(C)=L2(C)+λ∗L1(C)
上图还展示了一个细节,就是针对不同的任务,模型的输入token序列是有区别的:
-
对于文本分类任务,输入格式与预训练时一样,[start;text;extract];
-
对于文本蕴含任务,在前提(premise)和假设(hypothesis)间加上了一个分隔符(delimiter),[start;premise;delimiter;hypothesis;extract];
注:文本蕴含任务(text entailment),它的任务形式是:给定一个前提文本(premise),根据这个前提去推断假设文本(hypothesis)与前提文本的关系,一般分为蕴含关系(entailment)和矛盾关系(contradiction),蕴含关系(entailment)表示从前提文本中可以推断出假设文本;矛盾关系(contradiction)即假设文本与前提文本矛盾。文本蕴含的结果就是这几个概率值。 -
对于文本相似性度量任务,由于两个文本间没有相对顺序,所以把两种情况([start;text1;delimiter;text2;extract]和[start;text2;delimiter;text1;extract])分别处理后得到两个 h l m h_{l}^{m} hlm后,再按位相加经过全连接层;
-
对于问答和常识推理任务,将上下文文档(context document)和问题(question)与不同的答案(answer)分别拼接起来([start;context;question;delimiter;answer1];[start;context;question;delimiter;answer2]…),经过模型后,再经过softmax层。
GPT2
全称:Generative Pre-Training 2.0
论文:《Language Models are Unsupervised Multitask Learners》
概述
GPT2有4个不同的版本,分别如下图所示,区别在于embedding的维度和transformer-decoder的层数。所有的模型目前在WebText上都还存在欠拟合的情况,如果给更多的时间去训练的话效果还能进一步的提升。
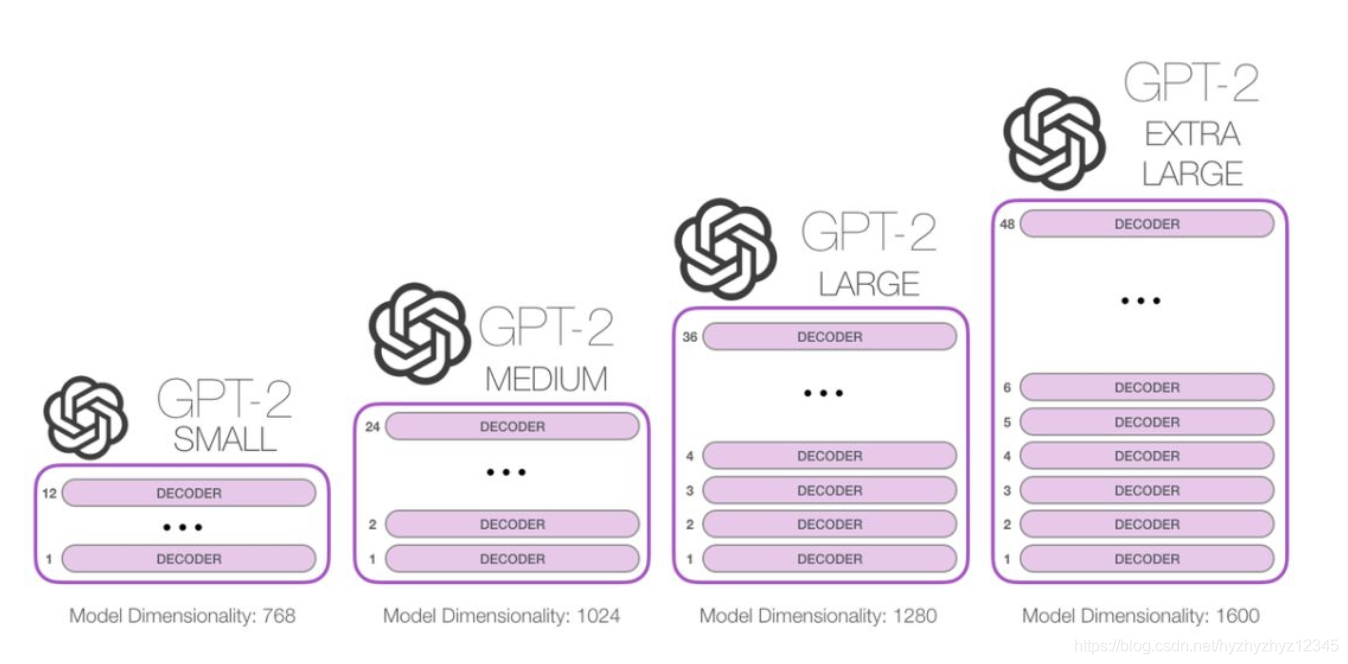
GPT2与GPT1
最主要的区别还是GPT2完全变成无监督训练,直接用于下游任务,属于零样本学习(Zero-shot learning)。下面具体介绍一些区别。
输入表征(Input Representation)
为了解决word级别的embedding常存在的OOV问题(out-of-vocabulary,即词典以外的词汇),而字符级的embedding效果又不太好。
本文采用了字节对编码(BPE,Byte Pair Encoding),即将频率高的字节对一起编码。
(以下部分内容为本人的推测)
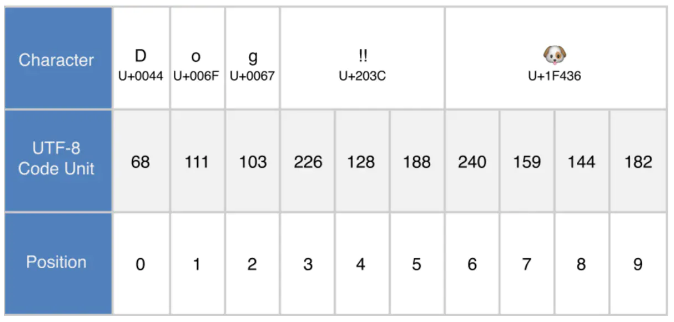
GPT2可能使用的是UTF-8的编码方式,如下图所示,UTF-8会将字符以8位为一个编码单元进行编码,所以只需要有0~255对应的embedding就可以得到每个字符embedding(与原文“a byte-level version of BPE only requires a base vocabulary of size 256.”对应),如将266、128、188对应的embedding加起来就得到了“!!”的embedding。
但这种效果肯定不好,所以对高频的字符串应该进行额外学习embedding,如“dog”有很高的频率一起出现,所以单独给它一个embedding。但“dog?”、“dog.”、“dog!”等也有很高的频率一起出现,如果也单独给它们一个embedding有些浪费资源,所以设置一个规则:对于包含多类字符的字符串不额外学习embedding。
如此,GPT2不需要任何预处理即可用于任意数据集。
模型(Model)
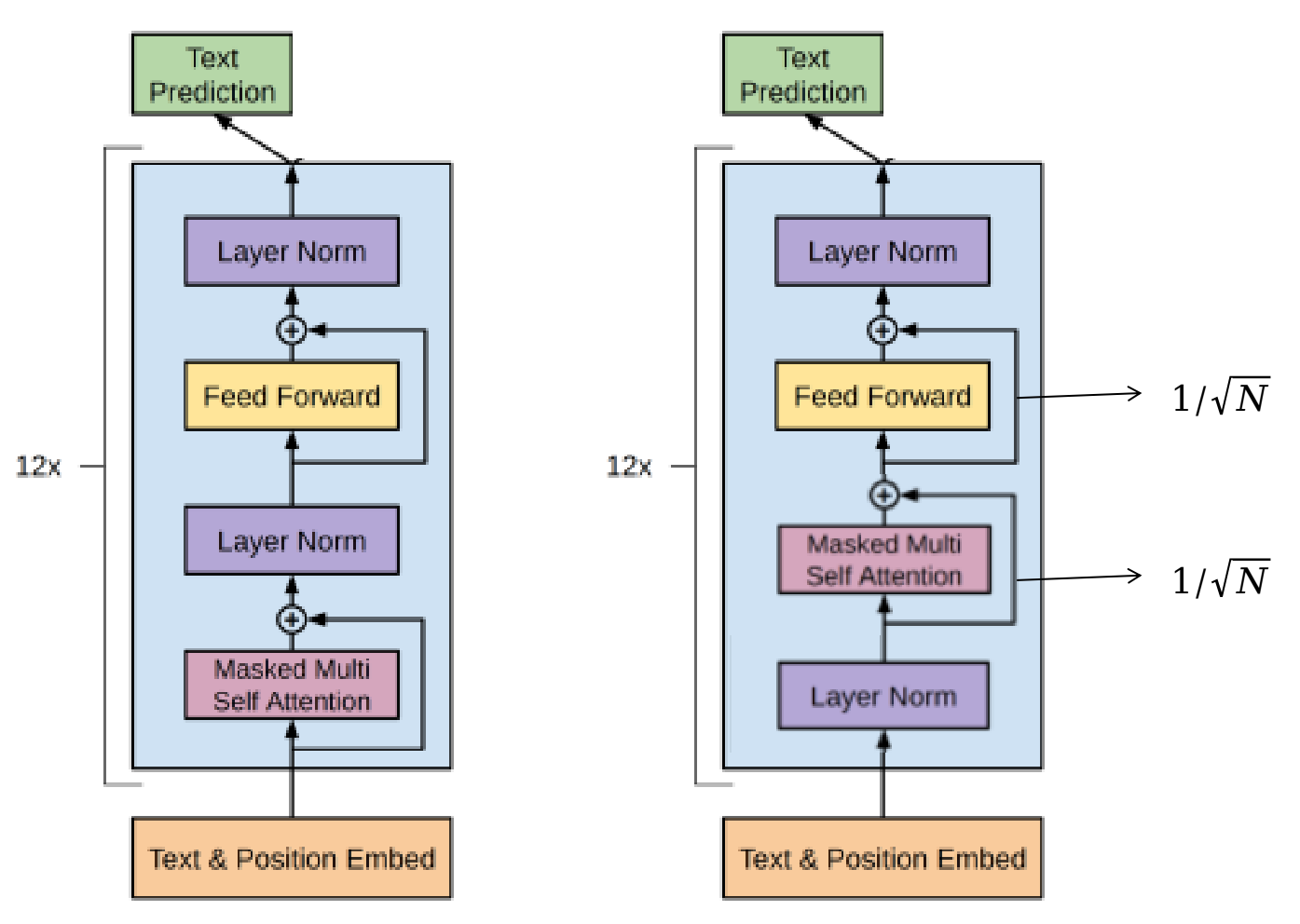
- Layer normalization层被移动到了每个子块的输入;
- 在每个self-attention block后加normaliztion;
- 修改residual layers的权重( 1 / N 1/sqrt{N} 1/N,其中 N sqrt{N} N为残差层的数量),即残差层的参数初始化根据网络深度进行调节;
- 词汇量增加到50257;
- 上下文大小从512增加到1024;
- batchsize增加到512
GPT2的模型大概八成可能也就像下图右一:
参数个数统计
GPT2-small的参数统计表如下:
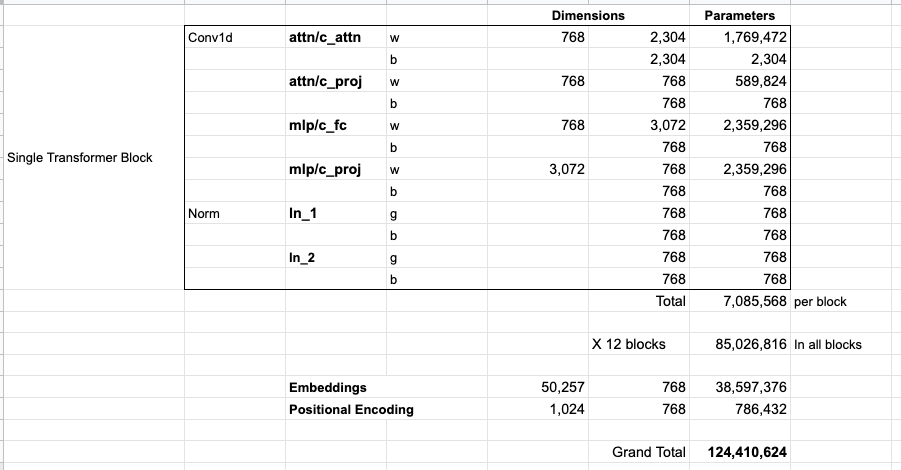
其中,attn/c_attn和attn/c_proj分别为Self-Attention模块中的attention矩阵和映射矩阵;attn/c_proj和attn/fc分别为Feed-Forward模块中的全连接层和映射层;ln_1和ln_2为两个Layer Normalization层。
如何使用
这里直接借用了李宏毅老师的ppt:

可以看出,在使用模型时,只需要给GPT少量的文本和提示词,GPT就可以自动完成阅读理解、文本摘要和翻译等任务。
最后
以上就是酷酷白昼最近收集整理的关于总结GPT1和GPT2的全部内容,更多相关总结GPT1和GPT2内容请搜索靠谱客的其他文章。








发表评论 取消回复