前言:
现在需要用到tensorflow+keras,有一些遇到的问题在此记录,内容随时更新可能会非常杂乱,也许会整理。
版本对应问题
从TensorFlow 2.3开始可以使用tensorflow.keras来导入Keras,即可以
import tensorflow as tf
import tensorflow.keras as keras
# 通常会直接从keras中导入模型使用,即:
from tensorflow.keras import Sequential
# 可以直接导入贯序模型使用
以下列出tensorflow、keras和python的几个常用较低版本的对应关系:(详细完整的对应关系见官方文档)
| tensorflow版本 | keras版本 | python版本 |
|---|---|---|
| TensorFlow 2.2.0 | Keras 2.3.1 | Python 3.7 |
| TensorFlow 2.1.0 | Keras 2.3.1 | Python 3.6 |
| TensorFlow 2.0.0 | Keras 2.3.1 | Python 3.6 |
| TensorFlow 1.15.0 | Keras 2.3.1 | Python 3.6 |
| TensorFlow 1.14.0 | Keras 2.2.5 | Python 3.6 |
交叉熵损失函数
直接调用compile使用自定义的加权交叉熵损失函数作为loss时,keras接收的是一个batch_size大小的tensor对象,因此在初用时遇到定义时没问题但fit时compile收到报错:Incompatible shapes: [100,1] vs. [159999,1](这里我的batch_size是100,样本个数159999也即自定义的损失函数输出了一个159999维的向量,这里应该要让损失函数的输出维度等于1——即计算这159999个数的均值再输出,然后模型会将batch_size个均值以向量形式一次输出作为一个epoch的损失)。
接下来又发现,直接用tf.keras.losses.binary_crossentropy()是可以的,即:
def my_loss(y_true, y_pred):
return keras.losses.binary_crossentropy(y_true,y_pred)*lamda
正常运行(其中lamda是全局变量)
发现网上大家普遍有两种调用交叉熵损失函数的方法,用到了两个不同的keras定义的交叉熵损失函数:
- tf.keras.losses.binary_crossentropy()
- tf.keras.backend.binary_crossentropy()
tf.keras.losses.binary_crossentropy()是通过调用tf.keras.backend.binary_crossentropy()来工作的,以下为官方文档提供的源码说明中的关键部分:源码地址

即可以理解为:
from keras import backend as K
tf.keras.losses.binary_crossentropy():
return K.mean( K.binary_crossentropy() )
而backend.binary_crossentropy()的完整计算过程为:(红框为关键部分)
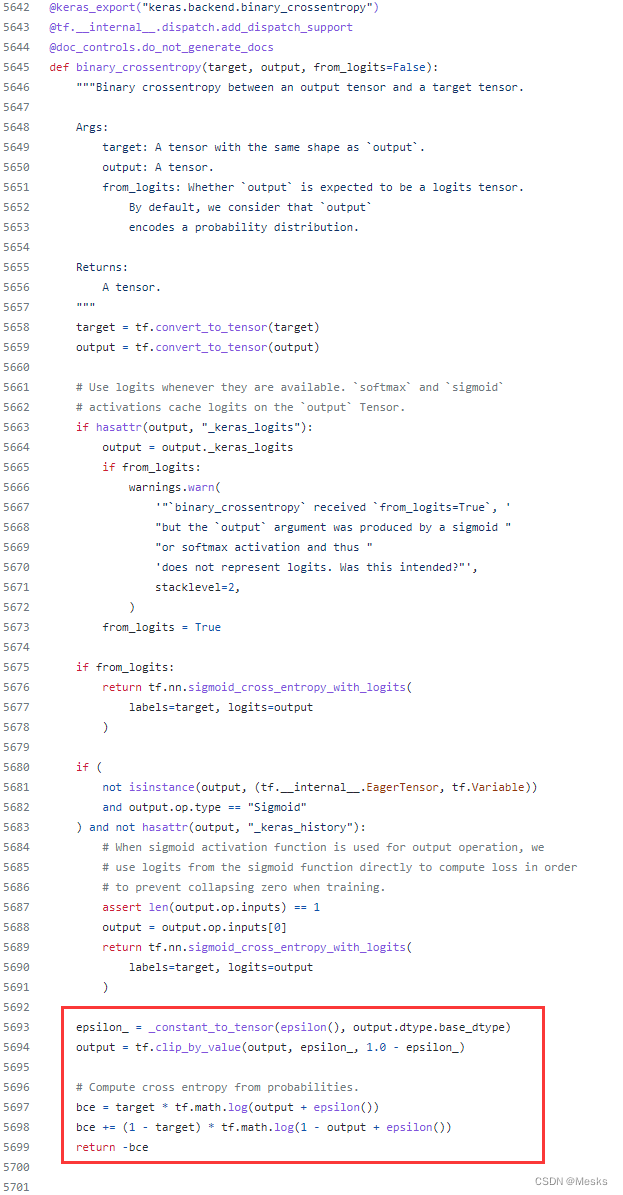
可以发现计算公式为:(公式图片来源知乎(懒得自己写了))
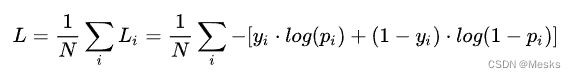
tensorflow中填充tensor的方法
背景: 我在自定义的损失函数最后计算损失时,由于最后一个批次的数量不足一个batch_size的大小,因此在做损失累加时会出错,因此需要在计算loss时将tensor重构为尺寸是[batch_size,1]的tensor。
需求: 将一个[15,1]的Tensor转为一个[16,1]的Tensor。
要实现需求,需要的函数是tensorflow.pad(),首先感谢这位博主对tensor维度操作的总结及绘图:博文地址
以下提炼以下tensorflow.pad()的用法:
import tensorflow as tf
最后
以上就是陶醉鲜花最近收集整理的关于tensorflow+keras杂话的全部内容,更多相关tensorflow+keras杂话内容请搜索靠谱客的其他文章。
![tensorflow——[keras]内置数据集tensorflow——[keras]内置数据集](https://www.shuijiaxian.com/files_image/reation/bcimg5.png)







发表评论 取消回复