
文章目录
- 一、Multi-loss Regularized Deep Neural Network
- 二、Network in network
- 三、Artificial Intelligence-aided OFDM Receiver:Design and Experimental Results
一、Multi-loss Regularized Deep Neural Network
多损失正则化深度神经网络(计算机视觉)
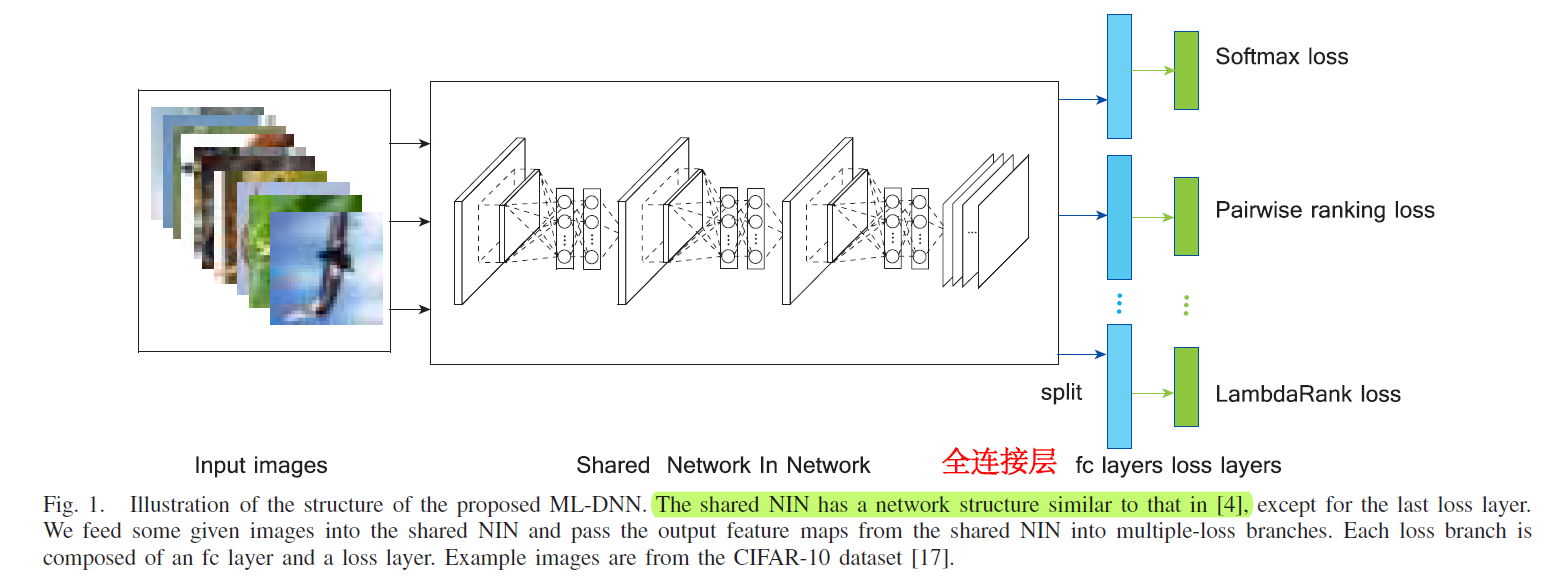
这种多重损失框架的直觉是,具有不同理论动机的损失函数(例如成对排名损失和LambdaRank损失)可能会阻止算法过度拟合到一个单一损失函数(例如softmax损失)。
来自不同损失函数的参数梯度因此可以方便地用于优化共享NIN的参数。
此外,不同的损失函数具有一定的互补性,并且它们带来的梯度有助于从不同方面迭代学习参数。这样,整个ML-DNN就能同时考虑所有这些多重损失函数,并避免训练过程中的过度拟合问题。
实验:
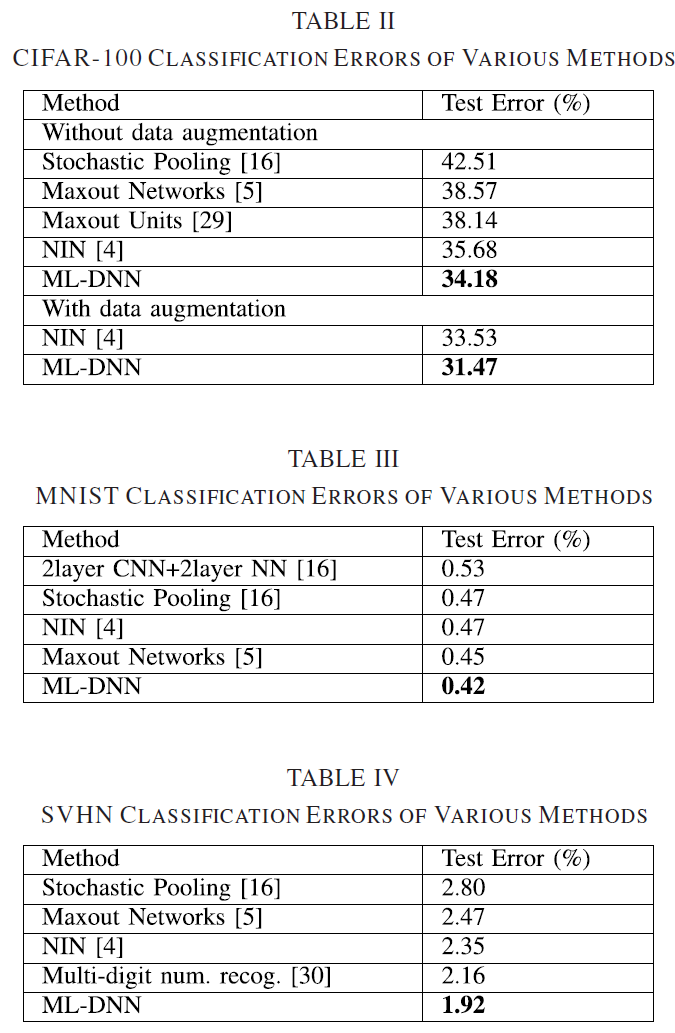
四个标准数据集:CIFAR-10、CIFAR-100、MNIST、SVHN
实验一:不同的正则化技术:
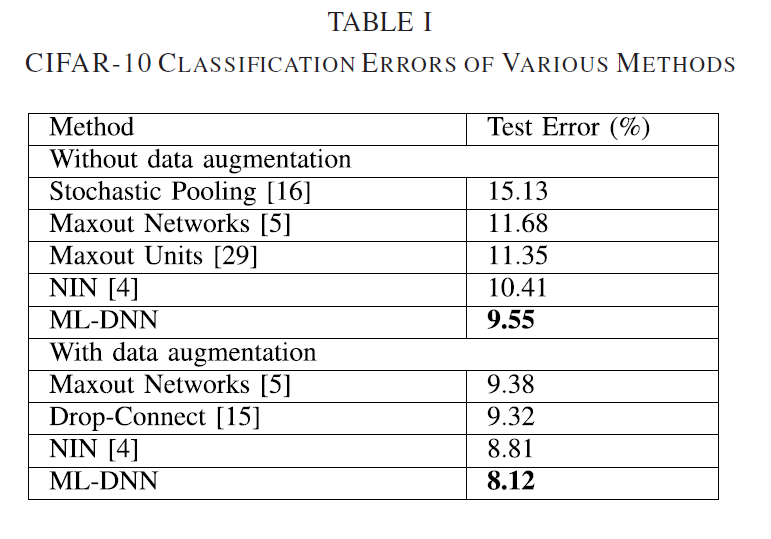
以上说明该方法
(1)提高了DNN网络分类的表现,泛化能力更强。
(2)缓解过拟合问题。
(3)性能优于常见的 regularization techniques—dropout, stochastic pooling, and maxout network
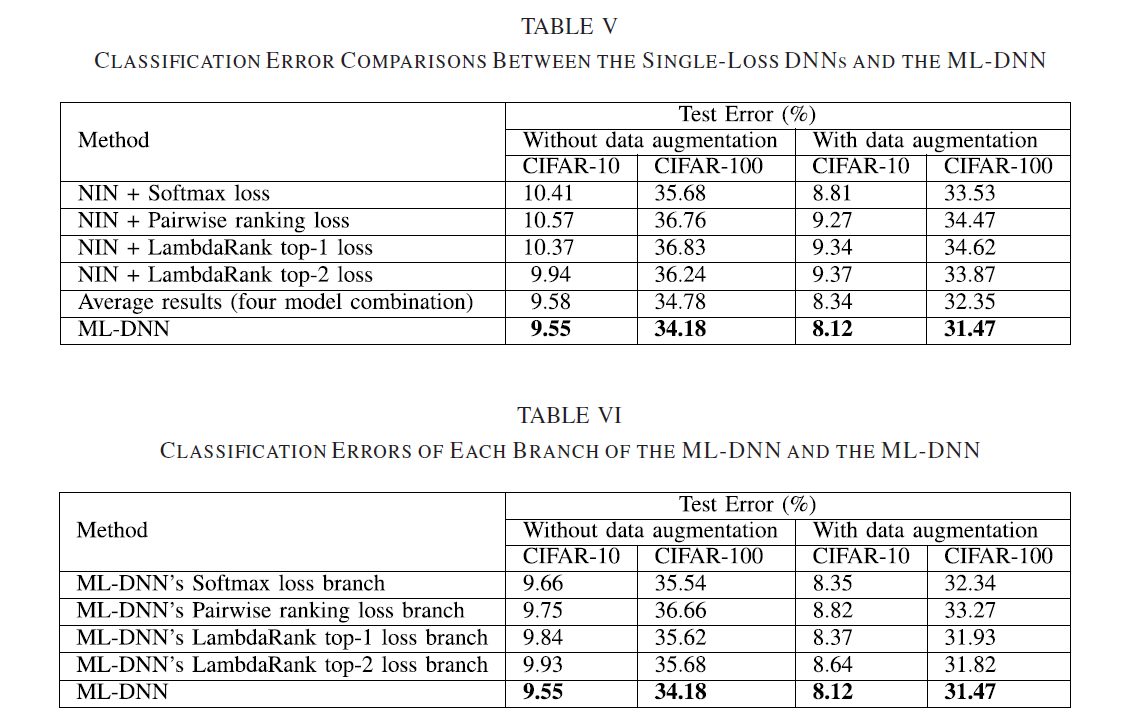
实验二:与单损失函数相比
二、Network in network
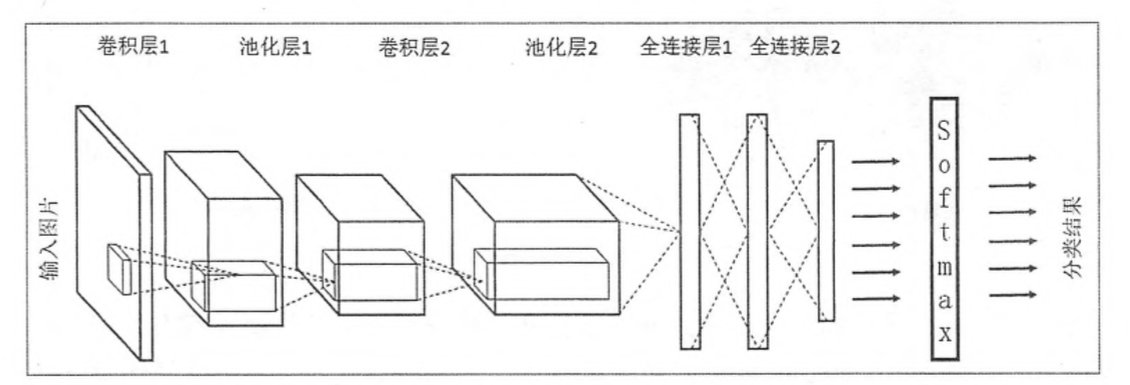
传统CNN:
NIN:
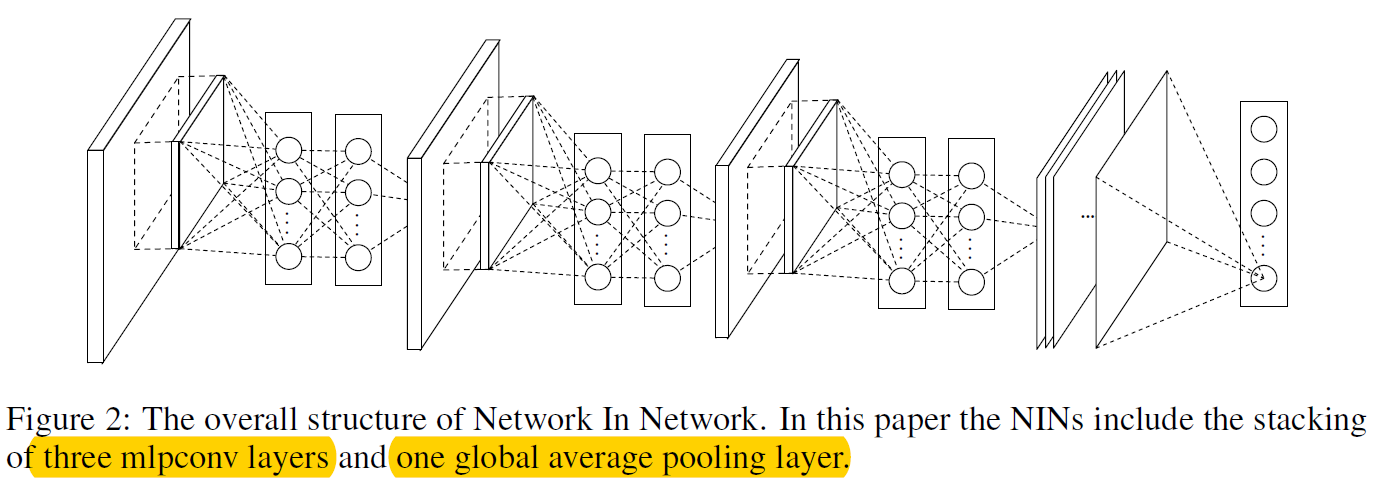
传统的卷积层只是将前一层的特征进行了线性组合,然后经过一个非线性激活。而在文章中,作者提出了使用一个微小的神经网络(主要是多层感知器)。作者之所以进行这样的改进,主要是因为,传统的卷积层只是一个线性的过程,而且,层次比较深的网络层是对于浅层网络层学习到的特征的整合,因此,在对特征进行高层次整合之前,进行进一步的抽象是必要的,因此,使用微网络进行进一步的抽象。(使特征更加抽象)。
1. MLP Convolution Layers:
跨通道mlpconv层:
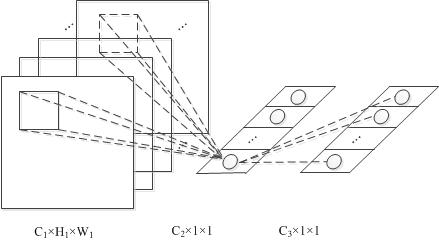
由图可知,mlpconv=convolution+mlp(图中为2层的mlp)
- 提取的特征更加抽象
2. Global Average Pooling:
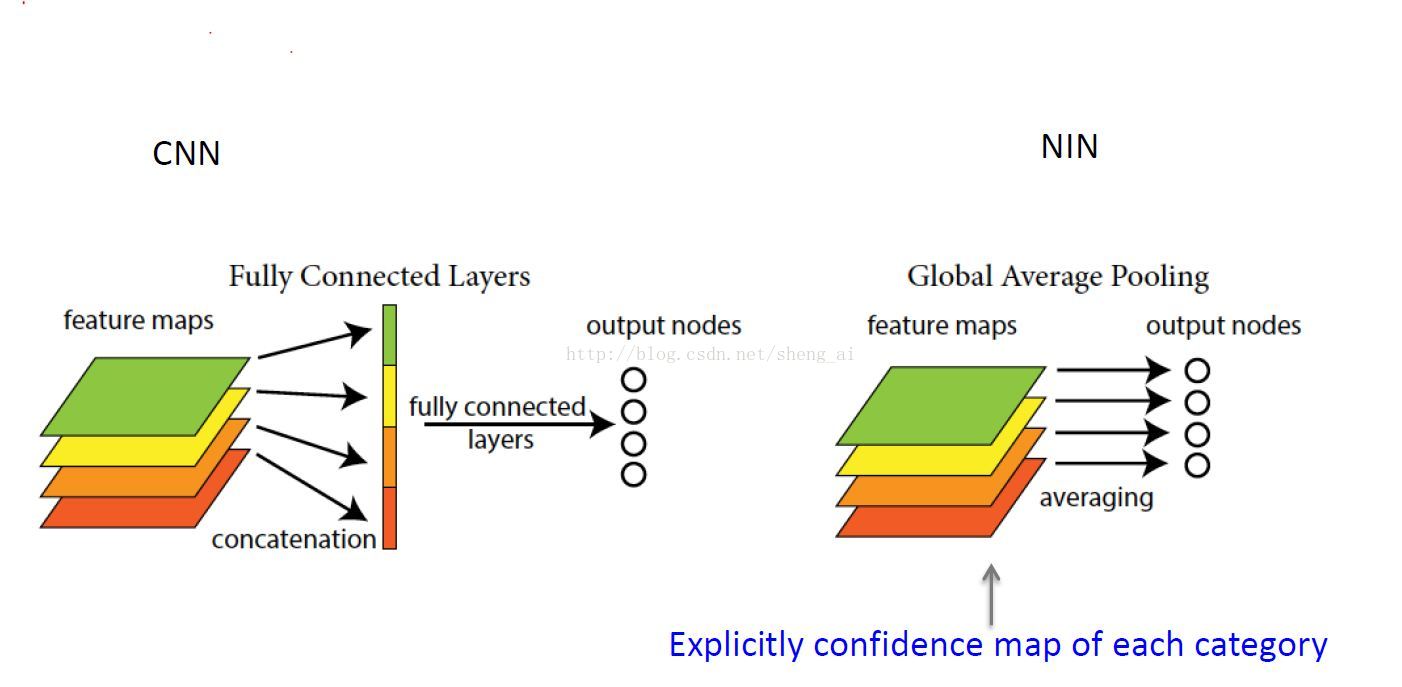
这个想法是为最后一个mlpconv层中的分类任务的每个对应类别生成一个feature map,我们取每个feature map的平均值,然后将所得向量直接馈入softmax层。
- 使用全局平均pooling能够强化特征图与类别的关系;
- 全局平均pooling没有参数需要进行优化,因此,可以避免在这一层出现Overfitting。
- 更少的参数。
实验:
在CIFAR-10, CIFAR-100, SVHN and MNIST数据集上,均获得不错的效果。
三、Artificial Intelligence-aided OFDM Receiver:Design and Experimental Results
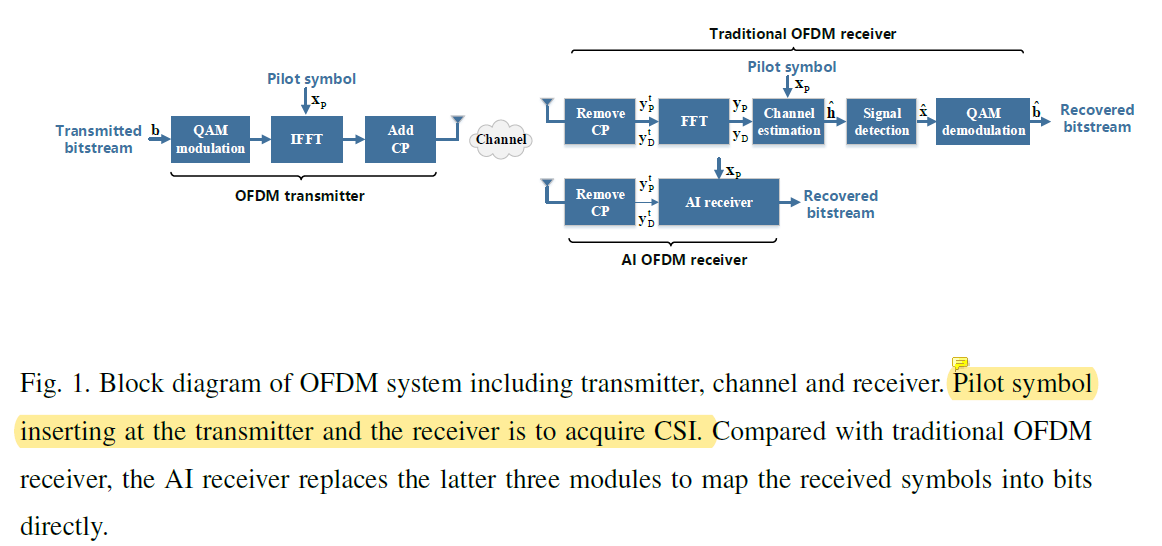
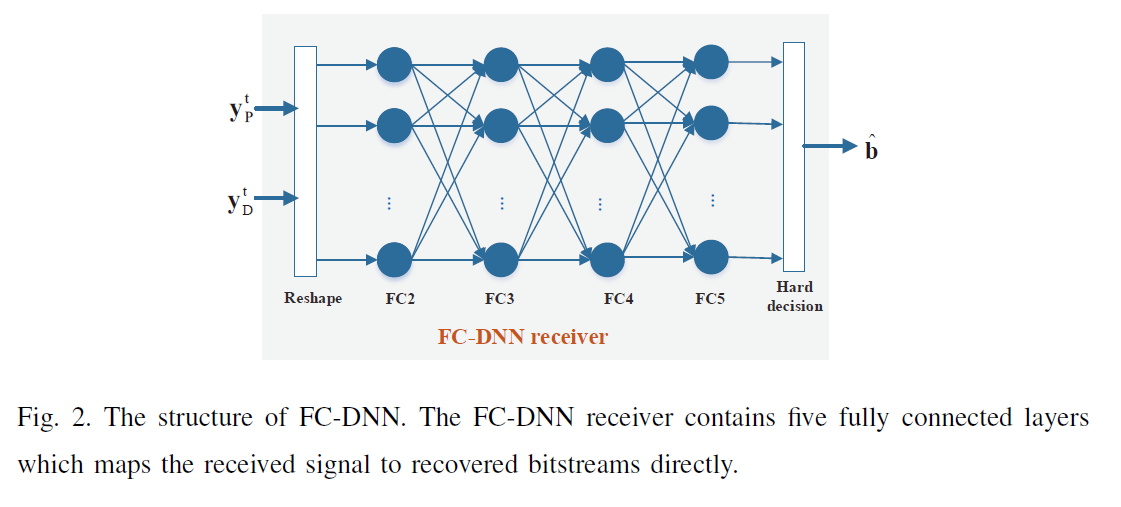
FC-DNN receiver:
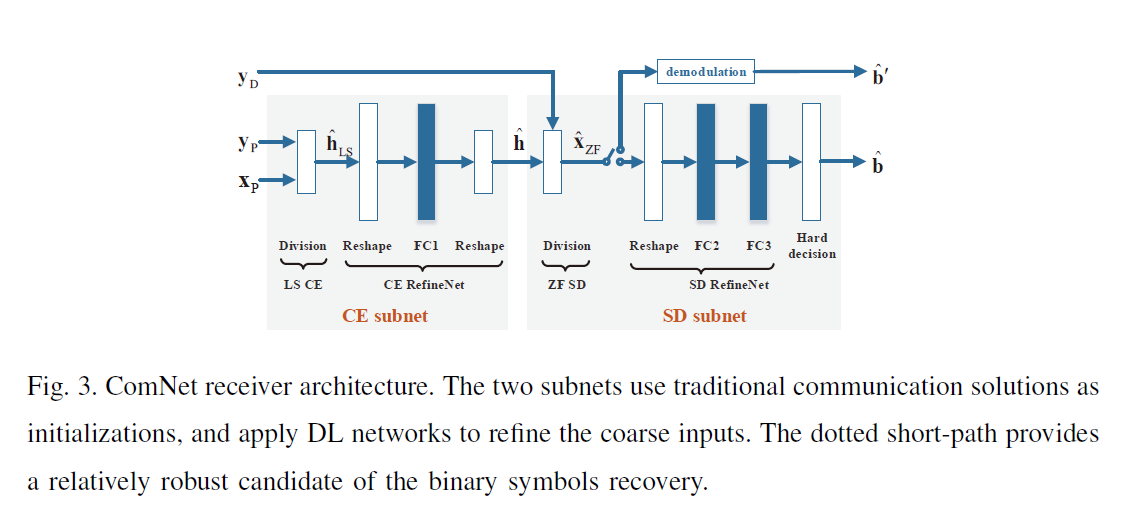
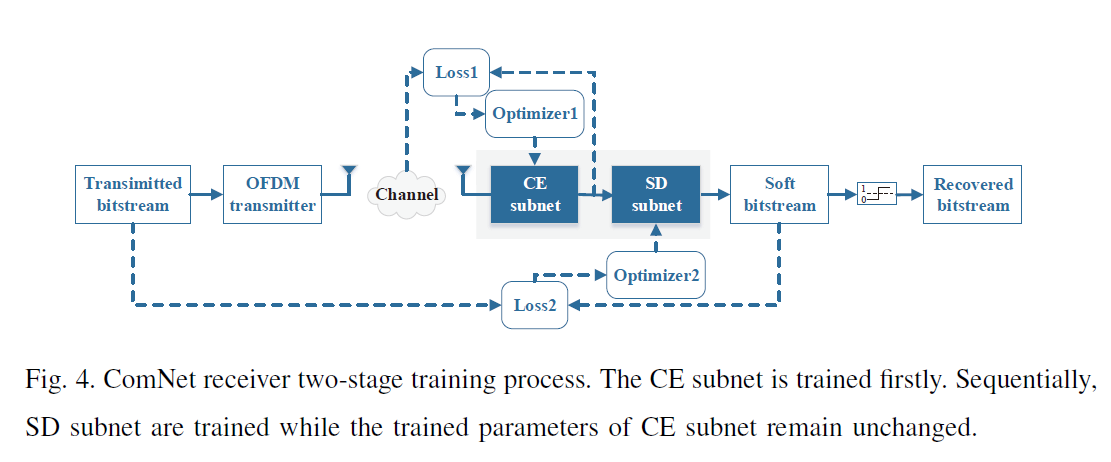
ComNet receive:
SwitchNet receiver:
LTIwMjAwNTI0MTAyNzI3NzQ3LnBuZw?x-oss-process=image/format,png)
SwitchNet receiver:
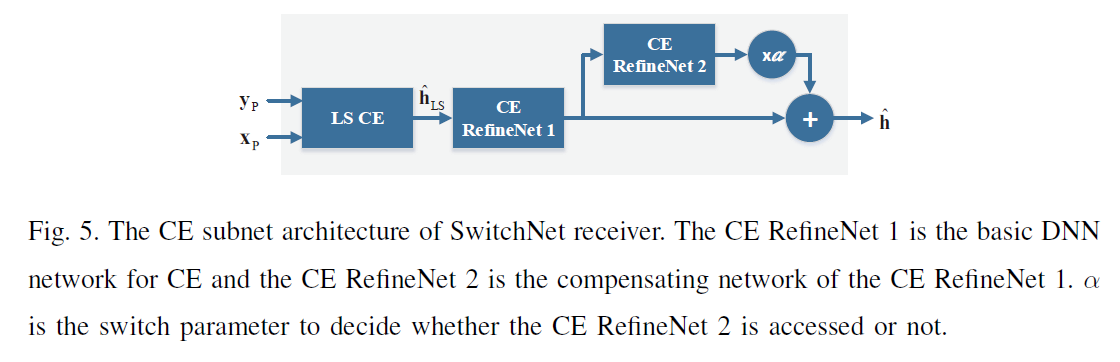
最后
以上就是碧蓝小蝴蝶最近收集整理的关于Multi-loss Regularized Deep Neural Network一、Multi-loss Regularized Deep Neural Network二、Network in network三、Artificial Intelligence-aided OFDM Receiver:Design and Experimental Results的全部内容,更多相关Multi-loss内容请搜索靠谱客的其他文章。








发表评论 取消回复