2.9 列表
列表是一个有序的集合。
- 创建列表对象
integer_list = [1, 2, 3]
heterogeneous_list = ["string", 0.1, True, 1]
list_of_lists = [integer_list, heterogeneous_list, []]
- 列表运算
list_length = len(integer_list) # is 3
list_sum = sum(integer_list) # is 1+2+3=6
- 访问列表元素
- 下标索引可以为负数,表示从列表末尾数起
x = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
# 取数
zero = x[0]
one = x[1]
nine = x[-1]
eight = x[-2]
# 存数
x[0] = -1
- 切片
语法格式:list[start:end:step]
- 从start(包括)到end(不包括),start和index都是下标索引
- step为步长,可以为负数
- start为空->从列表头开始切片
- end为空 -> 从列表尾开始切片
x = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
# 0 1 2 3 4 5 6 7 8 9
# -10 -9 -8 -7 -6 -5 -4 -3 -2 -1
first_three = x[:3] # [0, 1, 2]
three_to_end = x[3:] # [3, 4, 5, 6, 7, 8, 9]
one_to_four = x[1: 5] # [1, 2, 3, 4]
last_three = x[-3:] # [7, 8, 9]
without_first_and_last = x[1: -1] # [1, 2, ..., 8]
shallow_copy_of_x = x[:]
every_third = x[::3] # [0, 3, 6, 9]
three_to_five = x[3:6:1] # equals to x[3:6], step默认为1
# [3, 4, 5]
five_to_three = x[5:2:-1] # [5, 4, 3]
- 使用
in运算符来检查某值是否存在于列表中时,比如:1 in [1, 2, 3],这种检查每次都会遍历整个列表元素,这意味着除非列表很短(或者你不在乎检查需要多长时间),否则就不应该进行这样的检查。 - 向列表中追加元素
# 写法1
x = [1, 2, 3]
x.extend([4, 5, 6]) # x is [1, 2, 3, 4, 5, 6]
# 写法2
x = [1, 2, 3]
x = x + [4, 5, 6] # x is [1, 2, 3, 4, 5, 6]
# 写法3
x = [1, 2, 3]
x.append(4)
x.append(5)
x.append(6) # x is [1, 2, 3, 4, 5, 6]
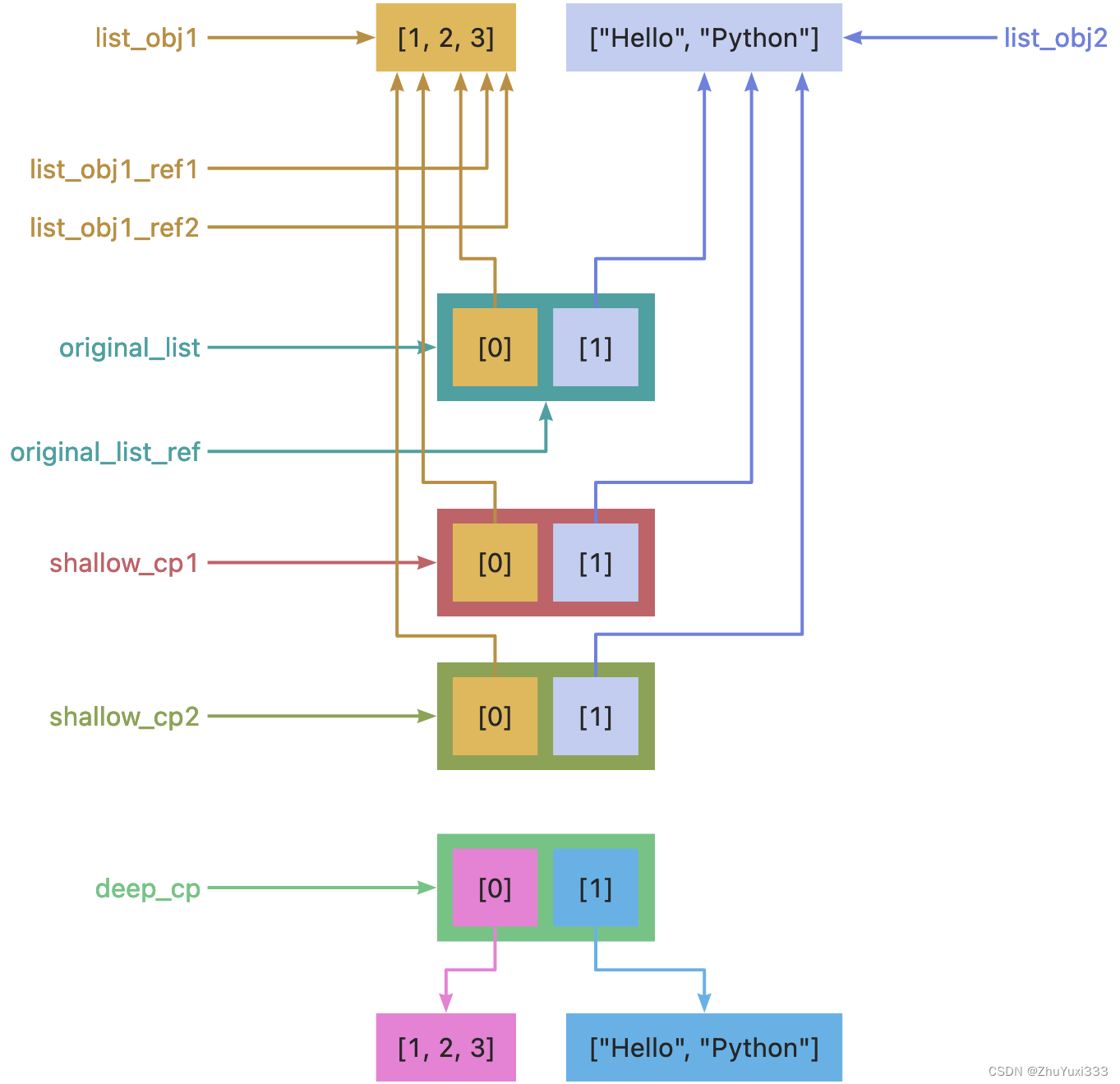
- 赋值、深拷贝与浅拷贝
- 赋值就是创建引用
- 列表中存储的是元素对象的引用
- 浅拷贝新建列表对象,但列表中的元素还是指向原来元素对象的引用
- 深拷贝不仅新建列表对象,而且新建所有的元素对象,新列表中的元素指向新的元素对象
import copy
list_obj1 = [1, 2, 3]
list_obj2 = ["Hello", "Python"]
list_obj1_ref1 = list_obj1
list_obj1_ref2 = list_obj1
print("list_obj1_ref1 is list_obj1: ", list_obj1_ref1 is list_obj1)
print("list_obj1_ref2 is list_obj1: ", list_obj1_ref2 is list_obj1)
print("list_obj1_ref1 is list_obj1_ref2: ", list_obj1_ref1 is list_obj1_ref2)
original_list = [list_obj1, list_obj2]
original_list_ref = original_list
print("original_list is original_list_ref: ", original_list is original_list_ref)
shallow_cp1 = original_list.copy()
shallow_cp2 = original_list[:]
print("shallow_cp1 is original_list: ", shallow_cp1 is original_list)
print("shallow_cp2 is original_list: ", shallow_cp2 is original_list)
print("shallow_cp1[0] is list_obj1: ", shallow_cp1[0] is list_obj1)
print("shallow_cp2[0] is list_obj1: ", shallow_cp2[0] is list_obj1)
deep_cp = copy.deepcopy(original_list)
print("deep_cp is original_list: ", deep_cp is original_list)
print("deep_cp[0] is original_list[0]: ", deep_cp[0] is original_list[0])

2.10 元组
元组是不可修改的有序集合,对列表的任何不涉及修改的操作都可以对元组进行。修改元组将引发错误并抛出TypeError异常。
- 创建元组
# 1. 用圆括号
tuple1 = (1, 2)
# 2. 什么也不用
tuple2 = 3, 4

- 元组是从函数返回多个值的便捷方式
def sum_and_product(x, y):
return (x+y), (x*y)
sp = sum_and_product(2, 3) # sp is (5, 6)
s, p = sum_and_product(2, 3) # s is 5, p is 6
- Python中允许这样的多重赋值操作:
x, y = [1, 2]或x, y = 1, 2或x, y = (1, 2)- 现在x是1,y是2
- 当等号两边元素个数不同时,就会报 ValueError 错误
_, y = [1, 2] # 丢弃x值,现在y是2x, y = y, x # Python风格的变量交换
2.11 字典
2.11.1 dict
- 创建字典
empty_dict = {}
grades = {"Joel": 80, "Tim": 95}
- 按照Key在字典中检索
# 方式一:dict[key]
joels_grade = grades["Joel"]
## 如果找的Key不在字典中则会报KeyError错误
# 方式二:dict.get(key, default_val) 如果找的Key不在字典中则返回default_val
joels_grade = grades.get("Joel", 0)
kates_grade = grades.get("Kate", 0) # kates_grade is 0
- 字典操作
- 检查Key是否在字典中:
in
joel_has_grade = "Joel" in grades # joel_has_grade is True
- 使用方括号指定某个Key对应的Value,如果Key不存在则将<Key, Value>对加入字典中
grades["Joel"] = 90 # 将Joel的成绩重置为90
grades["Kate"] = 100 # 向字典grades中添加一个新的键值对:<"Kate", 100>
- 获取字典项的个数:
len(grades) - 获取字典中的键/值:
grades_keys = grades.keys() # key的列表
grades_values = grades.values() # value的列表
grades_items = grades.items() # (key, value)列表
- 多维的Key:
- 使用元组(注:只能使用元组,不能用列表)
- 将Key转为字符串
2.11.2 defultdict
defaultdict类似于标准的字典,除了当你尝试查找不包含它的键时:
- 标准的字典会报
KeyError错误; - 而
defaultdict会首先使用你在创建它时提供的零参数函数为该键生成值、将之一键值对添加到字典中,然后再进行访问
- 导入
defaultdict:from collections import defaultdict - 例:
from collections import defaultdict
# Example 1
dd_int = defaultdict(int)
dd_int["one"] = 1
## 字典中不存在键"one"
## --> 根据内置函数int()为键"one"生成值 -> 0
## --> 将 <"one", 0> 添加到字典中
## --> 现在 dd_int 是 {"one":1}
# Example 2
dd_list = defaultdict(list)
dd_list["list1"].append(1)
## 字典中不存在键"list1"
## --> 根据内置函数list()为键"list1"生成值 -> 空列表[]
## --> 将 <"list1", []> 添加到字典中
## --> dd_list["list1"].append(1)
## --> 现在 dd_list["list1"] 是 [1]
## --> 现在 dd_list 是 {"list1":[1]}
# Example 3
dd_dict = defaultdict(dict)
dd_dict["Joel"]["City"] = "Seattle"
## 字典中不存在键"Joel"
## --> 根据内置函数dict()为键"Joel"生成值 -> 空字典{}
## --> 将 <"Joel", {}> 添加到字典中
## --> dd_dict["Joel"]["City"] = "Seattle"
## --> 现在 dd_dict["Joel"] 是 {"City":"Seattle"}
## --> 现在 dd_dict 是 {"Joel":{"City":"Seattle"}}
# Example 4
dd_pair = defaultdict(lambda : [0,0])
dd_pair[2][1] = 1
## 字典中不存在键 2
## --> 根据匿名函数 lambda : [0,0] 生成值 -> [0,0]
## --> 将 <2, [0,0]> 添加到字典中
## --> dd_pair[2][1] = 1
## --> 现在 dd_pair[2] 是 [0,1]
## --> 现在 dd_pair 是 {2:[0,1]}
2.11.3 WordCount —— 字典如何处理不存在的key值?
- 要求:统计某个文档中每一个单词出现的次数
- 思路:创建一个字典
word_counts,其字典项为<word, word_count>。遍历document中的每一个word:如果该word已经存在于word_counts中,则将其对应的word_count加一;如果该word不在字典中,则将其添加到字典中,并将word_count置1。
写法一:标准字典 + if-else处理缺失键
word_counts = {}
for word in document:
if word in word_counts:
word_counts[word] += 1
else:
word_counts[word] = 1
写法二:标准字典 + “异常处理机制”处理缺失键
word_counts = {}
for word in document:
try:
word_counts[word] += 1
except KeyError:
word_counts[word] = 1
写法三:标准字典 + get()处理缺失键
word_counts = {}
for word in document:
previous_count = word_counts.get(word, 0)
word_counts[word] = previous_count + 1
写法四:defaultdict(推荐)
from collections import defaultdict
word_counts = defaultdict(int)
for word in document:
word_counts[word] += 1
最后
以上就是发嗲小笼包最近收集整理的关于【Data Science from Scratch 学习笔记】第2章 Python速成(中)的全部内容,更多相关【Data内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复