一丶了解什么是结构体,以及计算结构体成员的对其值以及总大小(类也是这样算)
结构体的特性
1.结构体(struct)是由一系列具有相同类型或不同类型的数据构成的数据集合
2.在C语言中,结构体(struct)指的是一种数据结构,是C语言中聚合数据类型(aggregate data type)的一类。
3. 结构体可以被声明为变量、指针或数组等,用以实现较复杂的数据结构。结构体同时也是一些元素的集合,这些元素称为结构体的成员(member),且这些成员可以为不同的类型,成员一般用名字访问。
高级代码:
struct TagList { char ch; int number1; short int number2; double dbl; float flt; };
上面就是一个简单的结构体,那么我们这个结构体在内存中的偏移要怎么计算.
公式:
下面是推理,如果不想看可以直接跳到总结去看总结.
成员偏移量的公式
alg 设alg是编译器的对其值,offset为结构体首地址的偏移,从0开始.
Member offset % min(alg,sizeof(member type) == 0; 这个公式是求成员位于结构体首地址的偏移
比如计算 成员 flt位与结构体首地址的偏移 ,要先从 第一个成员开始计算
设alg对齐值为4
offset % min(4,sizeof(ch)) == 0;
0 % min(4,1) == 0 得出ch变量位于结构体首地址为0的偏移处,占1个字节 +0 1
offset % min(4,sizeof(number1)) == 0
因为上面求出了ch占的大小,所以求出占1字节,所以偏移+1变为了1的位置
那么现在的offset = 1,继续代入公式
1 % min(4,4) == 0,不成立,偏移继续++
2%min(4,4) == 0,不成立,偏移继续++
.....
一直到偏移为4的时候满足,所以 偏移为4的地方,放number1 +4 4
计算 number2所在的偏移
offset % min(4,sizeof(member type)) == 0;
8 % min(4,2) == 0,成立 +8 2
计算dbl所在的位置
offset % min(4,sizeof(member type)) == 0;
10 % (4,8) == 0,不成立
11%(4,8) == 0,不成立
12%(4,8) == 0;成立,所以在 +12 8
计算float的位置
offset % min(4,sizeof(member type)) == 0;
20 % min(4,4) == 0; 成立 +20 4
那么各成员的偏移已经计算出来了.
其中float成员位与结构体的 +20偏移,占4个字节大小.
计算结构体总体大小
公式:
sizeof(struct) % min( Max type size,alg);
结构体的大小我们上面计算出来了,是 24个字节
MAX type,是结构体中最大成员的数据类型大小, 现在是double,也就是8个字节
alg是编译器对齐值,现在是4
所以代入公式得到
24 % 4 == 6...0
所以总体的大小是24个字节.
总结:
编译器对齐值,设置为 alg, MeMber offset 从0开始计算, 其中Member offset 要每次代入公式之后,加上自己成员所占的字节大小,继续参与下次运算.
设置或者查看编译器对其值, VC6.0版本 Project (工程) -> Settings(设置) -> C/C++ -> Category(种类) -> Code Generation(代码生成) -> Struct Member alignment(结构体对齐值)
结构体成员偏移计算公式: MeMber offset % min(alg,sizeof(Member type)) == 0
结构体总大小计算公式: sizeof(struct) % min(Max type size,alg) == 0;
程序内存查看.
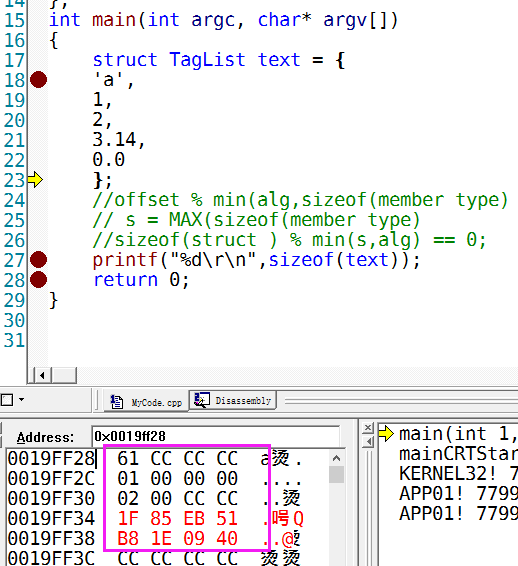
根据内存窗口赋值,可以得出结构体成语位与结构体的偏移是多少
第一个成员, +0 偏移位置, 占1个字节
第二个成员, +4 偏移位置, 占4个字节
第三个成员 +8 偏移位置, 占2个字节
第四个成员 +12偏移位置,占8个字节
PS: 其中成员的Member offset 从零开始,当计算完毕之后,需要加上自己所占的字节大小,然后继续参与运算,如果运算不成立,则偏移继续增加,一直到偏移成立
比如:
比如我们计算第二个成员位置的偏移
公式:
Member offset % min(alg,sizeof(member type size) == 0;
0 % 1 == 0 +0 放第一个成员
Member offset = Mmeber offset + 占的字节大小,(1)
求第二个成员位置
1 % 4 ==0; 偏移为1的时候,不成立,则偏移继续增加
2 % 4 == 0,不成立继续增加
3 % 4 ==0,不成立继续增加
4%4 == 0;成立,所以在 +4位置,方放4个字节,也就是第二个成员位置.
二丶结构体当做参数传递,为指针的情况下
void MyFun(struct TagList *pThis) { pThis->ch = 'b'; } int main(int argc, char* argv[]) { struct TagList text = { 'a', 1, 2, 3.14, 0.0 }; MyFun(&text); printf("%drn",text.number1); return 0; }
Debug下的汇编代码

产生了寻址公式其中eax是数组首地址,ebp +8则是参数,外面传入的是结构体首地址,所以ebp +8则是数组首
所以 ebp +8 则是结构体的首地址
mov byte ptr[eax],62h 这一句直接产生了 +0位置偏移,取内容赋值了字符
mov ecx,[ebp + 8]
mov dword ptr[ecx +4],2 这一句产生了 +4 偏移赋值为了2,所以可以确定
1.结构体首地址 ebp + 8 (参数1)
2.结构体第一个成员偏移 +0 赋值为字符
3.结构体第二个成员偏移 +4 赋值为2
Release下的汇编
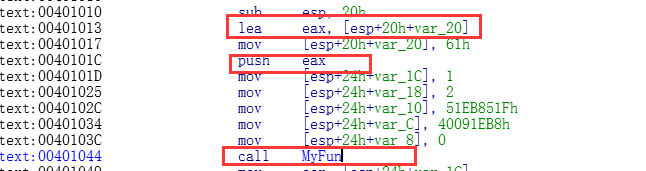
main函数调用传递结构体地址的时候,只需要三行汇编
lea eax,[esp + 20h + Var_20]
push eax
call MyFun
上面都是流水线优化的汇编
看下MyFun内部
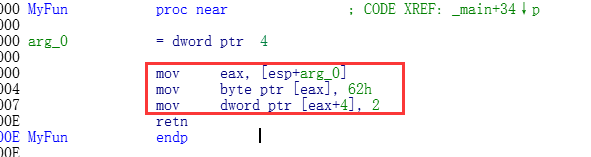
其结构和Debug差不多
1.获得结构体的首地址
2.+0偏移位置赋值字符
3.+4偏移位置,赋值为2
三丶结构体当做参数传递,为结构体本身的的情况下
高级代码:
void MyFun(struct TagList pThis) //这个地方变了.不是指针了 { pThis.ch = 'b'; pThis.number1 = 2; } int main(int argc, char* argv[]) { struct TagList text = { 'a', 1, 2, 3.14, 0.0 }; MyFun(text); //传参不用取地址了 printf("%drn",text.number1); return 0; }
Debug下的汇编

传参之前的操作
很明显
1.先抬栈
2.循环6次,每次4个字节4个字节的拷贝
3.获得结构体的首地址
4.将栈顶赋值给edi,意思就是说,从栈顶开始复制.
5.执行串操作指令,rep movsd 将 esi的内容复制到栈顶位置处,
因为要复制 24个字节,所以栈顶要+24所以这一段就是存储结构体成员的.
MyFun内部

1. 经过传参之后,esp的位置为数组首地址的,也就是+0位置偏移处
2.进入函数后压入返回地址,那么栈 esp -4, 然后push ebp,继续esp -4
3.mov ebp,esp,保存寻址,现在的ebp + 8正好是外面我们进行串拷贝的时候的结构体的首地址.
4.mov byte ptr[ebp +8],62h,相当于就是给我们结构体成员的 +0成员赋值
5.mov dword ptr[ebp + 0ch],2 则正好是我们的第二个成员.
所以为了解释这两句汇编代码,需要通过外面传参的栈环境来看.

Release下的汇编
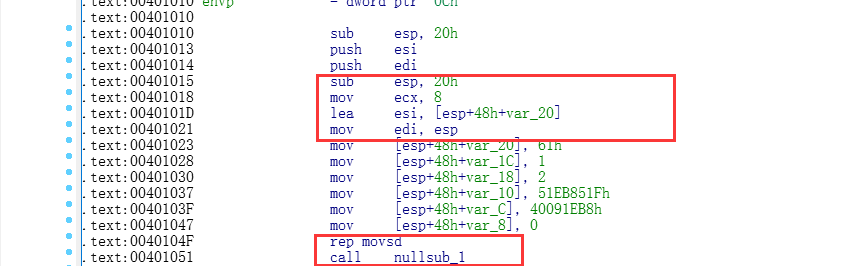
和Debug下一样,也是要进行串拷贝
MyFun函数内部

发现我们没有使用,所以直接给优化了.
三丶函数返回值为结构体的时候
1.返回为指针的时候,直接放到eax中
返回值,为结构体的情况
三种情况
1.当结构体大小小于(4这个数不确定)个字节,直接用eax返回
2.当结构大小小于(8这个数不确定)个字节,直接用 edx,eax返回
3.当结构体大小大于 8个字节以上(不确定,视编译器而决定).
最后一种的高级代码:
struct TagList MyFun() { struct TagList text = { 'a', 1, 2, 3.0, 4.0, }; return text; } int main(int argc, char* argv[]) { struct TagList text; text = MyFun(); printf("%crn",text.ch); return 0; }
Debug下的汇编代码

1.我们的函数没有参数,但是Debug会生成上面的代码,传入进入, 为什么? 因为返回值eax等等都装不下了,所以利用这块内存区域当做返回值
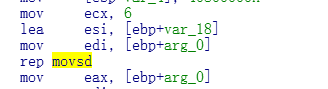
2.函数退出之前,也会对它进行串操作指令,因为要返回这块内存区域,所以写入内存.
3.返回值以前会把首地址给 eax保存
4.看外面是否使用eax,如果使用可以可以判断返回的是一个对象,(当然这一步可以省略,但是上面的三步少一步都不是返回对象)
参数问题:
它会默认给我们生成一个参数传入,那么我们有了参数,则会跟在后面.
Release汇编代码一样.
转载于:
作者:IBinary
出处:http://www.cnblogs.com/iBinary/
转载于:https://www.cnblogs.com/gd-luojialin/p/11219889.html
最后
以上就是无辜泥猴桃最近收集整理的关于逆向知识第十四讲,(C语言完结)结构体在汇编中的表现形式的全部内容,更多相关逆向知识第十四讲,(C语言完结)结构体在汇编中内容请搜索靠谱客的其他文章。








发表评论 取消回复