据我目前所知道的,写入HDFS文件,不支持并发操作同一个文件,但是支持同时操作不同的文件
下面代码是消费多个kafka 同时写入到HDFS
注意:这个方法我已经放弃使用,仅供参考,在大量数据写入一段时间后,会发生租约问题,导致数据不再写入关于本文最后有提到过租约的解决办法,但是没有亲测是否成功,大家如果使用了我的方法,并且解决了这个问题,麻烦告知一下,互相学习,谢谢了。
package com.tvm;
import com.alibaba.fastjson.JSONObject;
import kafka.consumer.ConsumerConfig;
import kafka.consumer.ConsumerIterator;
import kafka.consumer.KafkaStream;
import kafka.message.MessageAndMetadata;
import kafka.serializer.StringDecoder;
import kafka.utils.VerifiableProperties;
import org.apache.curator.framework.recipes.locks.Lease;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import org.apache.hadoop.hdfs.DFSClient;
import org.apache.hadoop.hdfs.server.namenode.LeaseManager;
import org.apache.hadoop.io.IOUtils;
import java.io.*;
import java.net.URI;
import java.net.URISyntaxException;
import java.text.SimpleDateFormat;
import java.util.*;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* Created by zhangx on 2017/3/21.
*/
public class KafkaConsumer{
public static Properties properties() throws IOException {
Properties properties_kafkainfo=new Properties();
InputStream in = new FileInputStream("/data2/kafkalocal/hdfs/kafkainfo.properties");
properties_kafkainfo.load(in);
return properties_kafkainfo;
}
public static Properties properties_topic() throws IOException {
Properties properties_kafkatopic=new Properties();
InputStream in = new FileInputStream("/data2/kafkalocal/hdfs/topic.properties");
properties_kafkatopic.load(in);
return properties_kafkatopic;
}
private final kafka.javaapi.consumer.ConsumerConnector consumer;
public KafkaConsumer() throws IOException {
Properties props = new Properties();
//props.put("zookeeper.connect", "10.20.30.91:2181,10.20.30.92:2181,10.20.30.93:2181");
props.put("zookeeper.connect", properties().getProperty("zookeeper_connect"));
props.put("group.id", properties().getProperty("group"));
props.put("zookeeper.session.timeout.ms", properties().getProperty("session_timeout_ms"));
props.put("zookeeper.sync.time.ms", properties().getProperty("zookeeper_sync_time_ms"));
props.put("auto.commit.interval.ms", properties().getProperty("auto_commit_interval_ms"));
props.put("auto.commit.enable",properties().getProperty("auto_commit_enable"));
props.put("auto.offset.reset", properties().getProperty("auto_offset_reset")); //largest smallest
props.put("serializer.class", properties().getProperty("serializer_class"));
ConsumerConfig config = new ConsumerConfig(props);
consumer = kafka.consumer.Consumer.createJavaConsumerConnector(config);
}
public static
FileSystem fs;
public static Configuration conf;
public
static void init(){
conf = new Configuration();
conf .set("dfs.client.block.write.replace-datanode-on-failure.policy" ,"DEFAULT" );
conf .set("dfs.client.block.write.replace-datanode-on-failure.enable" ,"true" );
conf.set("fs.hdfs.impl", org.apache.hadoop.hdfs.DistributedFileSystem.class.getName());
conf.set("fs.file.impl",org.apache.hadoop.fs.LocalFileSystem.class.getName());
conf.setBoolean("dfs.support.append",true);
try {
fs = FileSystem.newInstance(new URI("hdfs://10.20.30.91:8020"), conf);
} catch (IOException e) {
e.printStackTrace();
System.out.println("1");
} catch (URISyntaxException e) {
e.printStackTrace();
System.out.println("2");
}
}
//public static FileSystem fs ;
void consume() {
final int numThreads = 6;
final Iterator<String> topic;
try {
final Properties properties = properties_topic();
topic = properties.stringPropertyNames().iterator();
Map<String, Integer> topicCountMap = new HashMap<String, Integer>();
List<String> topicList = new ArrayList<String>();
while(topic.hasNext()){
final String key_topic = topic.next();
topicList.add(key_topic);
topicCountMap.put(key_topic, new Integer(1));
}
StringDecoder keyDecoder = new StringDecoder(new VerifiableProperties());
StringDecoder valueDecoder = new StringDecoder(new VerifiableProperties());
final Map<String, List<KafkaStream<String, String>>> consumerMap =
consumer.createMessageStreams(topicCountMap,keyDecoder,valueDecoder);
for(int i=0;i<topicList.size();i++) {
final String key_topic1 = topicList.get(i);
new Thread(
new Runnable() {
@Override
public void run() {
//List<KafkaStream<String, String>> streams = consumerMap.get(key_topic1);
KafkaStream<String, String> stream = consumerMap.get(key_topic1).get(0);
ConsumerIterator<String, String> it = stream.iterator();
StringBuilder messagesum = new StringBuilder();
int min = 0;
while (it.hasNext()) {
String message = it.next().message();
JSONObject jsStr = JSONObject.parseObject(message);
//System.out.println("一条长度:"+jsStr.toString().getBytes().length);
try {
if (properties.getProperty(key_topic1).equals("null")) {
String dateTime = new SimpleDateFormat("yyyyMMddHH").format(new Date());
String hdfspath = "hdfs://10.20.30.91:8020/kafka/";
String name = dateTime + ".log";
String filename = hdfspath + key_topic1 + name;
min++;
messagesum.append(message).append("n");
if (min>1000){
min = 0;
setFSDataOutputStream(filename, messagesum);
messagesum.delete(0,messagesum.length());
}
//WriteFile(getFSDataOutputStream(),message);
} else {
String time = properties.getProperty(key_topic1);
String dateTime = new SimpleDateFormat("yyyyMMddHH").format(jsStr.get(time));
String hdfspath = "hdfs://10.20.30.91:8020/kafka/";
String name = dateTime + ".log";
String filename = hdfspath + key_topic1 + name;
min++;
messagesum.append(message).append("n");
if (min>1000){
min = 0;
setFSDataOutputStream(filename, messagesum);
messagesum.delete(0,messagesum.length());
}
}
} catch (IOException e) {
e.printStackTrace();
System.out.println("3");
}
}
}
}).start();
}
} catch (IOException e) {
e.printStackTrace();
}
}
private SortedMap<String, Lease> sortedLeasesByPath = new TreeMap<String, Lease>();
private SortedMap<String, Lease> leases = new TreeMap<String, Lease>();
public static void setFSDataOutputStream(String filename,StringBuilder message) throws IOException {
FSDataOutputStream
hdfsOutStream;
//FileSystem fs ;
Path path = new Path(filename);
/*conf = new Configuration();
conf .set("dfs.client.block.write.replace-datanode-on-failure.policy" ,"DEFAULT" );
conf .set("dfs.client.block.write.replace-datanode-on-failure.enable" ,"true" );
conf.set("fs.hdfs.impl", org.apache.hadoop.hdfs.DistributedFileSystem.class.getName());
conf.set("fs.file.impl",org.apache.hadoop.fs.LocalFileSystem.class.getName());
conf.setBoolean("dfs.support.append",true);*/
//fs = FileSystem.get(URI.create(filename), conf);
if(fs.exists(path)){
//ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(message.toString().getBytes());
hdfsOutStream = fs.append(path);
hdfsOutStream.write(message.toString().getBytes());
//IOUtils.copyBytes(byteArrayInputStream, hdfsOutStream, 4096,true);
//byteArrayInputStream.close();
hdfsOutStream.hflush();
hdfsOutStream.close();
//fs.close();
//hdfsOutStream.hsync();
//hdfsOutStream.close();
System.out.println("path:==="+path);
}else{
//long starttime=new Date().getTime();
hdfsOutStream = fs.create(path);
hdfsOutStream.write(message.toString().getBytes());
hdfsOutStream.hflush();
hdfsOutStream.close();
//fs.close();
//hdfsOutStream.hsync();
//hdfsOutStream.close();
System.out.println("creatpath:"+path);
}
}
public static void main(String[] args) {
init();
try {
new KafkaConsumer().consume();
} catch (IOException e) {
e.printStackTrace();
}
}
}gradle.build
/*buildscript {
repositories {
maven {
url "https://plugins.gradle.org/m2/"
}
}
dependencies {
classpath "com.github.jengelman.gradle.plugins:shadow:1.2.4"
}
}*/
group 'kafkatohdfs'
version '1.0-SNAPSHOT'
/*apply plugin: 'com.github.johnrengelman.shadow'*/
apply plugin: 'java'
apply plugin: 'idea'
apply plugin:'application'
[compileJava, compileTestJava, javadoc]*.options*.encoding = 'UTF-8'
sourceCompatibility = 1.7
targetCompatibility=1.7
mainClassName = "com.tvm.KafkaConsumer"
repositories {
mavenLocal()
mavenCentral()
jcenter()
maven {
url = 'http://115.159.154.56:8081/nexus/content/groups/public'
}
}
dependencies {
testCompile group: 'junit', name: 'junit', version: '4.11'
compile "org.apache.kafka:kafka_2.10:0.8.2.2"
compile group: 'com.alibaba', name: 'fastjson', version: '1.2.21'
compile "org.projectlombok:lombok:1.16.6"
compile "org.apache.logging.log4j:log4j-api:2.3"
compile "org.apache.logging.log4j:log4j-core:2.3"
//hadoop
compile group: 'org.apache.hadoop', name: 'hadoop-hdfs', version: '2.7.3'
compile group: 'org.apache.hadoop', name: 'hadoop-common', version: '2.7.3'
compile group: 'org.apache.hadoop', name: 'hadoop-client', version: '2.7.3'
fileTree(dir: 'lib', include: '*.jar')
}
jar {
String someString = ''
configurations.runtime.each {someString = someString + " lib//"+it.name}//遍历项目的所有依赖的jar包赋值给变量someString
manifest {
attributes 'Main-Class': 'com.tvm.KafkaConsumer'
attributes 'Class-Path': someString
}
}
//清除上次的编译过的文件
task clearPj(type:Delete){
delete 'build','target'
}
task copyJar(type:Copy){
from configurations.runtime
into ('build/libs/lib')
}
//把JAR复制到目标目录
task release(type: Copy,dependsOn: [build,copyJar]) {
// from 'conf'
// into ('build/libs/eachend/conf') // 目标位置
}配置文件topic信息
app_send_welfare_ana=createTime
app_balance_welfare_ana=createTime
tvm_ua_user_action=null配置文件kafka信息
zookeeper_connect=ttye_kafka-001:2181,ttye_kafka-002:2181,ttye_kafka-003:2181
group=hdfs_new
session_timeout_ms=4000
zookeeper_sync_time_ms=200
auto_commit_interval_ms=1000
auto_commit_enable=true
auto_offset_reset=largest
serializer_class=kafka.serializer.StringEncoder==============================================================================================================================
所遇到的问题:
1. hdfs java.io.FileNotFoundException: (打开的文件过多)
这个问题先检查linux 并发最多打开的文件数是多少
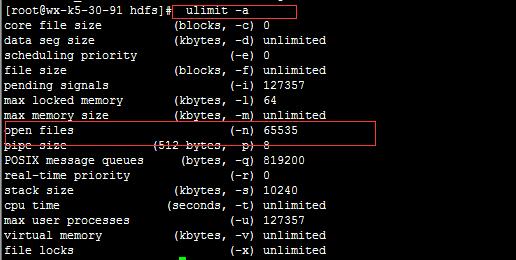
通过
vi /etc/security/limits.conf
打开添加参数
* soft nofile 65535
* hard nofile 65535
来改变系统打开文件最大的并发数
我所遇到的问题是:
下面这两句话(可以从上面代码中找到),这两句在每次接受到一条消息都要打开配置文件进行判断,导致多次打开文件
if (properties.getProperty(key_topic1).equals("null")) {
String time = properties.getProperty(key_topic1);
解决办法,将配置文件内容持久化(或者是从配置文件读取到内容放到map中,从map 中去数据,而不是直接从配置文件中去数据)
final Properties properties = properties_topic();
topic = properties.stringPropertyNames().iterator();2.租约问题
“客户端在每次读写HDFS文件的时候获取租约对文件进行读写,文件读取完毕了,然后再释放此租约”
每个客户端用户持有一个租约。每个租约内部包含有一个租约持有者信息,还有此租约对应的文件Id列表,表示当前租约持有者正在写这些文件Id对应的文件。
每个租约内包含有一个最新近更新时间,最近更新时间将会决定此租约是否已过期。
过期的租约会导致租约持有者无法继续执行写数据到文件中,除非进行租约的更新。
涉及到源码问题。
可参考:
http://www.cnblogs.com/foxmailed/p/4151735.html
http://blog.csdn.net/androidlushangderen/article/details/52850349
http://blog.csdn.net/wankunde/article/details/67632520?utm_source=itdadao&utm_medium=referral
最后
以上就是自由山水最近收集整理的关于单线程消费kafka存放到HDFS的全部内容,更多相关单线程消费kafka存放到HDFS内容请搜索靠谱客的其他文章。








发表评论 取消回复