一、Flume的安装配置
去Flume官网下载Flume安装包,我下载的版本为apache-flume-1.9.0-bin.tar.gz,解压。
(1)修改flume-env.sh。Flume运行在JVM之上,因此安装之前要确保系统安装了JDK,编辑环境配置文件,执行命令如下:
mv flume-env.sh.template ./flume-env.sh
vim flume-env.sh
export JAVA_HOME=/opt/java/jdk1.8.0_144
(2)设置系统环境变量。将flume安装路径加入到系统环境变量中,只需在/etc/profile 文件中假如Flume 的安装路径,然后将Flume的bin目录添加到系统的Path中,执行以下命令:
vim /etc/profile
export FLUME_HOME=/opt/flume/apache-flume-1.9.0-bin
export PATH=$PATH:$JAVA_HOME/bin:$KAFKA_HOME/bin:$ZooKeeper/bin:$FLUME_HOME/bin
:wq
source /etc/profile
(3)验证。在$FLUME_HOME/conf目录下有一个Flume采集数据的Source及Sink配置模板文件flume-conf-properties.template,Flume自带了一个用于生成测试数据的Source,通道为内存,接收器为Logger,即将数据以日志形式输出。运行以下命令启动Flume:
flume-ng agent --conf /opt/flume/apache-flume-1.9.0-bin/conf/ --conf-file /opt/flume/apache-flume-1.9.0-bin/conf/flume-conf.properties.template --name agent -Dflume.root.logger=INFO,console
- agent:指定以agent角色启动,另外一个角色为avro-client。
- conf或c:指定指定配置源和接收器配置文件的绝对路径,不包括配置文件名。
- config-file或f:指定配置源和接收器配置文件的相对路径,相对于执行该命令的目录。
- name或n:指定agent的名称。
- D:用-D后接健值对,指定Java相关的配置,如本例中指定将等级为info的日志信息输出到控制台。
二、Flume采集日志写入Kafka集群
创建一个flume-kafka.properties文件,写入相关配置如下。
首先指定源、接收器和通道的名称,配置如下:
agent.sources = sc #指定源名称
agent.sinks = sk #指定接收器名称
agent.channels = chl #指定通道名称
以上配置,agent表示代理的名称,代理名称可以为任意字符串,当有多个代理时要保证代理名称唯一。
接着配置源,本例是Flume监听 tail 命令打开的 /opt/flume/test.log 文件内容,主要配置信息如下:
agent.sources.sc.type = exec #指定源类型为linux命令
agent.sources.sc.channels = chl #绑定通道,指定源将事件传递的通道,可以指定多个通道
agent.sources.sc.command = tail -f /opt/flume/test.log #以tail命令打开文件输出流
agent.sources.sc.fileHeader = false #指定事件不包括头信息
然后配置通道信息,实例采用内存通道,内存通道配置信息如下:
agent.channels.chl.type = memory #指定通道类型
agent.channels.chl.capacity = 1000 #在通道中停留的最大事件数
agent.channels.chl.transactionCapacity = 1000 #每次从源拉取的事件数及给接收器的事件数
最后配置接收器,接收器从通道获取信息写入到Kafka,配置信息如下:
#接收器类型
agent.sinks.sk.type = org.apache.flume.sink.kafka.KafkaSink
#绑定通道,指定接收器读取数据的通道
agent.sinks.sk.channel = chl
agent.sinks.sk.kafka.bootstrap.servers = 172.20.10.3:9092,172.20.10.4:9092:172.20.10.5:9092
#指定写入Kafka的主题
agent.sinks.sk.kafka.topic=flume-kafka
#指定序列化类
agent.sinks.sk.serializer.class=kafka.serializer.StringEncoder
#生产者acks方式
agent.sinks.sk.producer.acks = 1
#指定字符编码
agent.sinks.sk.custom.encoding = UTF-8
配置信息之所以能指定KafkaSink,是因为在$FLUME_HOME/lib 目录自带了与Kafka集成的 flume-ng-kafka-sink-1.9.0.jar文件。同时,还可以指定生产者相关的其他配置,在生产者相关的配置属性名前加上“kafka.properties.”前缀即可。在启动agent之前,先启动kafka集群的消费者,命令如下:
kafka-console-consumer.sh --bootstrap-server 172.20.10.3:9092,172.20.10.4:9092,172.20.10.5:9092 --topic flume-kafka
启动Flume,为了在控制台打印启动日志,启动命令增加了 -Dflume.root.logger=INFO,console配置,启动本例配置的Flume agent命令如下:
flume-ng agent --conf /opt/flume/apache-flume-1.9.0-bin/conf/ --conf-file /opt/flume/apache-flume-1.9.0-bin/conf/flume-kafka.properties --name agent -Dflume.root.logger=INFO,console
为了验证日志是否成功写入到Kafka集群,我们在控制台执行echo指令写入数据到/opt/flume/test.log文件,命令如下:
echo 'flume实时从文件采集数据写入到Kafka集群' >>/opt/flume/test.log
在控制台可以看到消费者及时收到Flume采集的数据,示意图如下:
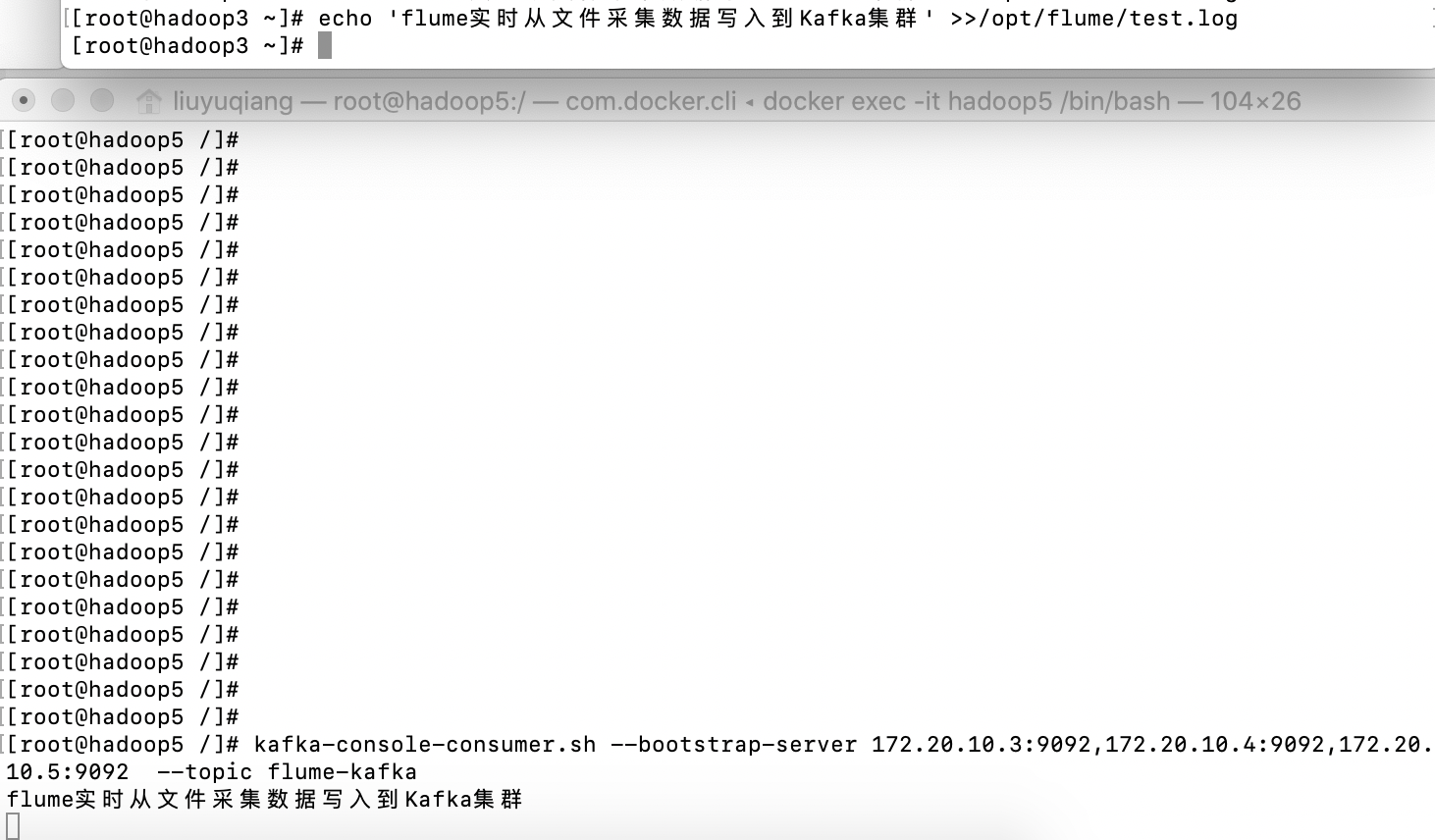
最后
以上就是柔弱含羞草最近收集整理的关于Kafka集群与Flume整合应用实战--Flume采集日志写入Kafka的全部内容,更多相关Kafka集群与Flume整合应用实战--Flume采集日志写入Kafka内容请搜索靠谱客的其他文章。








发表评论 取消回复