文章目录
- 基本方案
- 数据处理流程
- 数据清洗
- 二次清洗
- 视频访问
- 按照省份
- 按照流量
- 优化
- 数据可视化
- echarts
基本方案
用户行为日志:用户每次访问网站时所有的行为数据(访问、浏览、搜索、点击…)
用户行为轨迹、流量日志
日志数据内容:
- 1)访问的系统属性: 操作系统、浏览器等等
- 2)访问特征:点击的url、从哪个url跳转过来的(referer)、页面上的停留时间等
- 3)访问信息:session_id、访问ip(访问城市)等
2013-05-19 13:00:00 http://www.taobao.com/17/?tracker_u=1624169&type=1 B58W48U4WKZCJ5D1T3Z9ZY88RU7QA7B1 http://hao.360.cn/ 1.196.34.243
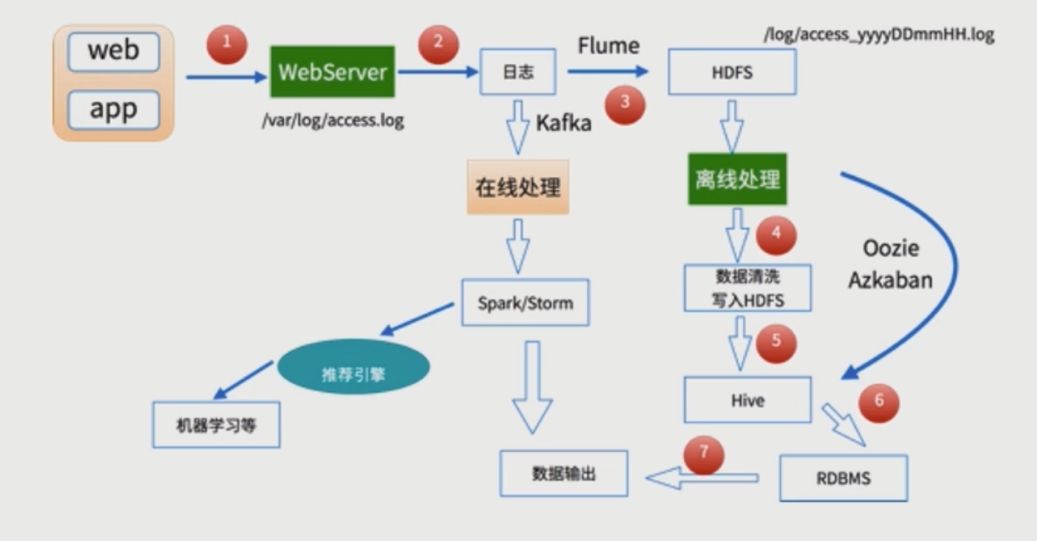
数据处理流程
-
1) 数据采集
Flume: web日志写入到HDFS -
2)数据清洗
脏数据
Spark、Hive、MapReduce 或者是其他的一些分布式计算框架
清洗完之后的数据可以存放在HDFS(Hive/Spark SQL) -
3)数据处理
按照我们的需要进行相应业务的统计和分析
Spark、Hive、MapReduce 或者是其他的一些分布式计算框架 -
4)处理结果入库
结果可以存放到RDBMS、NoSQL -
5)数据的可视化
通过图形化展示的方式展现出来:饼图、柱状图、地图、折线图
ECharts、HUE、Zeppelin
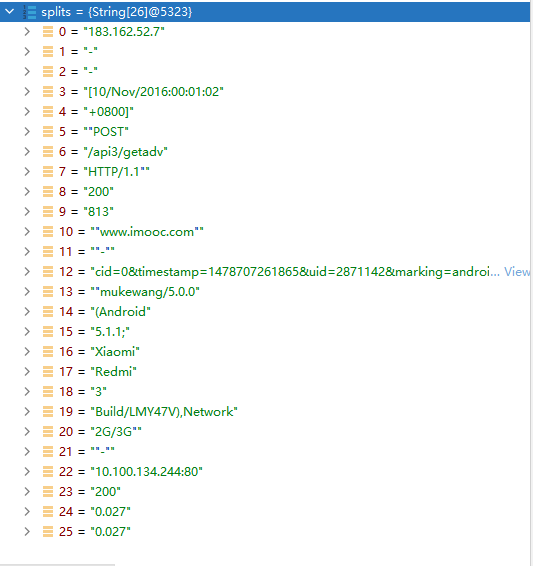
数据清洗
首先通过debug 找到分割后各个字段的对应的
- 报错
java.io.IOException: Could not locate executable nullbinwinutils.exe in the Hadoop binaries.
执行第一步数据清洗时候,数据能打印出来,但是不能写入本地文件,这是因为本地没有hadoop伪分布式系统
装一个插件即可
https://hiszm.lanzous.com/iWyqmhrgk0f
下载上述插件,然后,新建目录并且放入到目录里面
C:Datahadoopbin
然后再系统环境变量添加
HADOOP_HOME
C:Datahadoop
package org.sparksql
import org.apache.spark.sql.SparkSession
object SparkFormatApp {
def main(args: Array[String]): Unit = {
//SparkSession是spark的入口类
val spark = SparkSession.builder().appName("SparkFormatApp")
.master("local[2]").getOrCreate()
val access = spark.sparkContext.textFile("10000_access.log")
//access.take(10).foreach(println)
access.map(line=>{
val splits = line.split(" ")
val ip = splits(0)
val time = splits(3) + " " + splits(4)
val traffic = splits(9)
val url = splits(11).replace(""","")
//(ip,DateUtils.parse(time),traffic,traffic,url)
DateUtils.parse(time) + "t" + url + "t" + traffic + "t" + ip
}).saveAsTextFile("output")
//.take(10).foreach(println)
//.saveAsTextFile("output")
spark.stop()
}
}
一般的日志处理方式,我们是需要进行分区的,
按照日志中的访问时间进行相应的分区,比如:d,h,m5(每5分钟一个分区)
二次清洗
- 输入:
访问时间、访问URL、耗费的流量、访问IP地址信息 - 输出:
URL、cmsType(video/article)、cmsId(编号)、流量、ip、城市信息、访问时间、天
package org.sparksql
import org.apache.spark.sql.Row
import org.apache.spark.sql.types.{LongType, StringType, StructField, StructType}
//访问日志工具转换类
object AccessConvertUtils {
val struct=StructType(
Array(
StructField("url",StringType),
StructField("cmsType",StringType),
StructField("cmsId",LongType),
StructField("traffic",LongType),
StructField("ip",StringType),
StructField("city",StringType),
StructField("time",StringType),
StructField("day",StringType)
)
)
//根据输入的每一行信息转化成输出的样式
def parseLog(log:String)={
try{
val splits=log.split("t")
val url =splits(1)
val traffic = splits(2).toLong
val ip = splits(3)
val domain="http://www.imooc.com/"
val cms=url.substring(url.indexOf(domain) + domain.length)
val cmsTypeId = cms.split("/")
var cmsType = ""
var cmsId = 0l
if(cmsTypeId.length > 1){
cmsType = cmsTypeId(0)
cmsId = cmsTypeId(1).toLong
}
val city = IpUtils.getCity(ip)
val time = splits(0)
val day = time.substring(0,10).replaceAll("-","")
Row(url,cmsType,cmsId,traffic,ip,city,time,day)
}catch {
case e : Exception => Row(0)
}
}
}
- IP=>省份
使用github上已有的开源项目
1)git clone https://github.com/wzhe06/ipdatabase.git
2)编译下载的项目:mvn clean package -DskipTests

3)安装jar包到自己的maven仓库
mvn install:install-file -Dfile=C:Dataipdatabasetargetipdatabase-1.0-SNAPSHOT.jar -DgroupId=com.ggstar -DartifactId=ipdatabase -Dversion=1.0 -Dpackaging=jar

- 拷贝相关文件不然会报错
java.io.FileNotFoundException: file:/Users/rocky/maven_repos/com/ggstar/ipdatabase/1.0/ipdatabase-1.0.jar!/ipRegion.xlsx (No such file or directory)
- 测试
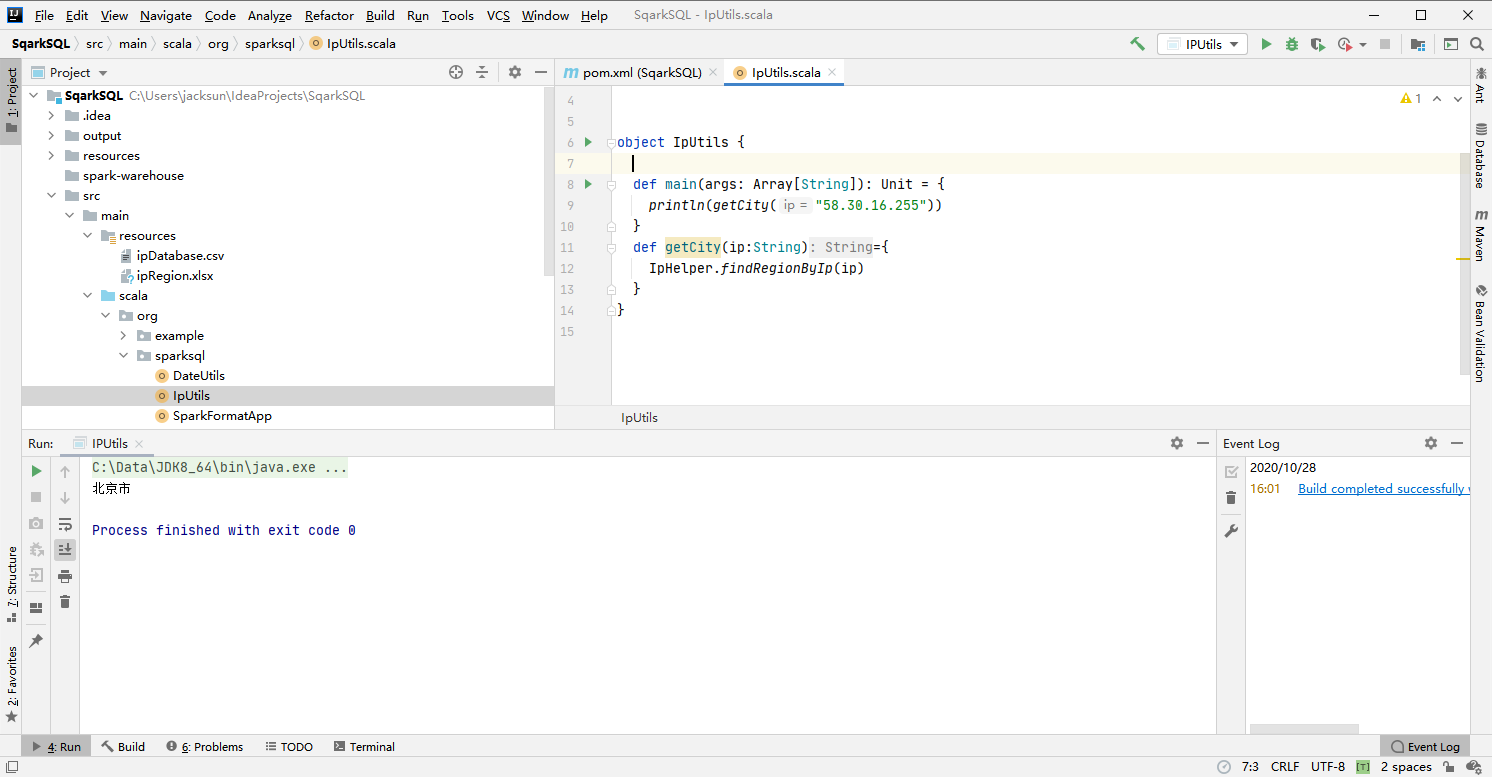
package org.sparksql
import org.apache.spark.sql.SparkSession
object SparkCleanApp {
def main(args: Array[String]): Unit = {
//SparkSession是spark的入口类
val spark = SparkSession.builder().appName("SparkFormatApp")
.master("local[2]").getOrCreate()
val accessRDD = spark.sparkContext.textFile("access.log")
//accessRDD.take(10).foreach(println)
val accessDF = spark.createDataFrame(accessRDD.map(x=>AccessConvertUtils.parseLog(x)),AccessConvertUtils.struct)
accessDF.printSchema()
accessDF.show()
spark.stop
}
}
root
|-- url: string (nullable = true)
|-- cmsType: string (nullable = true)
|-- cmsId: long (nullable = true)
|-- traffic: long (nullable = true)
|-- ip: string (nullable = true)
|-- city: string (nullable = true)
|-- time: string (nullable = true)
|-- day: string (nullable = true)
+--------------------+-------+-----+-------+---------------+----+-------------------+--------+
| url|cmsType|cmsId|traffic| ip|city| time| day|
+--------------------+-------+-----+-------+---------------+----+-------------------+--------+
|http://www.imooc....| video| 4500| 304| 218.75.35.226| 浙江省|2017-05-11 14:09:14|20170511|
|http://www.imooc....| video|14623| 69| 202.96.134.133| 广东省|2017-05-11 15:25:05|20170511|
|http://www.imooc....|article|17894| 115| 202.96.134.133| 广东省|2017-05-11 07:50:01|20170511|
|http://www.imooc....|article|17896| 804| 218.75.35.226| 浙江省|2017-05-11 02:46:43|20170511|
|http://www.imooc....|article|17893| 893|222.129.235.182| 北京市|2017-05-11 09:30:25|20170511|
|http://www.imooc....|article|17891| 407| 218.75.35.226| 浙江省|2017-05-11 08:07:35|20170511|
|http://www.imooc....|article|17897| 78| 202.96.134.133| 广东省|2017-05-11 19:08:13|20170511|
|http://www.imooc....|article|17894| 658|222.129.235.182| 北京市|2017-05-11 04:18:47|20170511|
|http://www.imooc....|article|17893| 161| 58.32.19.255| 上海市|2017-05-11 01:25:21|20170511|
|http://www.imooc....|article|17895| 701| 218.22.9.56| 安徽省|2017-05-11 13:37:22|20170511|
|http://www.imooc....|article|17892| 986| 218.75.35.226| 浙江省|2017-05-11 05:53:47|20170511|
|http://www.imooc....| video|14540| 987| 58.32.19.255| 上海市|2017-05-11 18:44:56|20170511|
|http://www.imooc....|article|17892| 610| 218.75.35.226| 浙江省|2017-05-11 17:48:51|20170511|
|http://www.imooc....|article|17893| 0| 218.22.9.56| 安徽省|2017-05-11 16:20:03|20170511|
|http://www.imooc....|article|17891| 262| 58.32.19.255| 上海市|2017-05-11 00:38:01|20170511|
|http://www.imooc....| video| 4600| 465| 218.75.35.226| 浙江省|2017-05-11 17:38:16|20170511|
|http://www.imooc....| video| 4600| 833|222.129.235.182| 北京市|2017-05-11 07:11:36|20170511|
|http://www.imooc....|article|17895| 320|222.129.235.182| 北京市|2017-05-11 19:25:04|20170511|
|http://www.imooc....|article|17898| 460| 202.96.134.133| 广东省|2017-05-11 15:14:28|20170511|
|http://www.imooc....|article|17899| 389|222.129.235.182| 北京市|2017-05-11 02:43:15|20170511|
+--------------------+-------+-----+-------+---------------+----+-------------------+--------+
调优点:
- 控制文件输出的大小: coalesce
- 分区字段的数据类型调整:spark.sql.sources.partitionColumnTypeInference.enabled
- 批量插入数据库数据,提交使用batch操作
package org.sparksql
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.apache.spark.sql.functions._
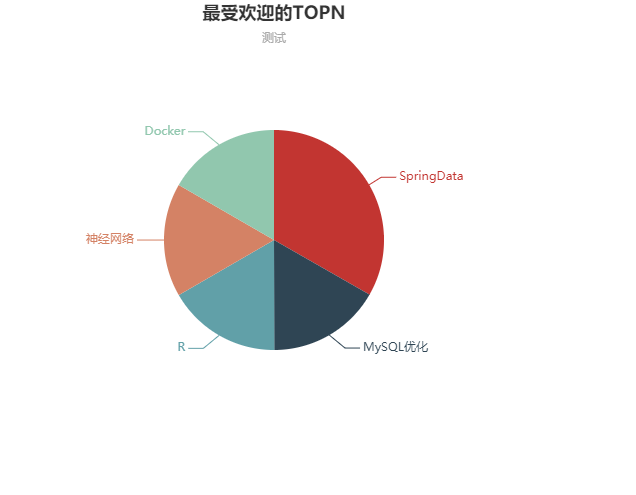
object TopNApp {
//最受欢迎
def videoAccessTopN(spark: SparkSession, accessDF: DataFrame) = {
import spark.implicits._
val videoTopNDF = accessDF.filter($"day"==="20170511"&& $"cmsType" === "video")
.groupBy("day","cmsId").agg(count("cmsId")
.as("times")).orderBy($"times".desc)
videoTopNDF.show()
accessDF.createOrReplaceTempView("access_log")
val videoTopNDF1 = spark.sql("select day,cmsId,count(1) as times from access_log where day='20170511' and cmsType = 'video' group by day,cmsId order by times desc")
videoTopNDF1.show()
}
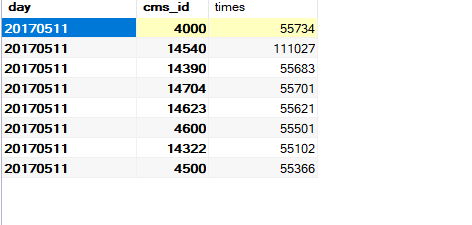
def main(args: Array[String]): Unit = {
//SparkSession是spark的入口类
val spark = SparkSession.builder().appName("SparkFormatApp")
.config("spark.sql.sources.partitionColumnTypeInference.enabled","false")
.master("local[2]").getOrCreate()
val accessDF= spark.read.format("parquet").load("output2/")
accessDF.printSchema()
accessDF.show(false)
videoAccessTopN(spark,accessDF)
spark.stop()
}
}
+--------+-----+------+
| day|cmsId| times|
+--------+-----+------+
|20170511|14540|111027|
|20170511| 4000| 55734|
|20170511|14704| 55701|
|20170511|14390| 55683|
|20170511|14623| 55621|
|20170511| 4600| 55501|
|20170511| 4500| 55366|
|20170511|14322| 55102|
+--------+-----+------+
视频访问
package org.sparksql
import java.sql.{Connection, DriverManager, PreparedStatement}
object MySqlUtils {
def getConnection() ={
// if (!conn.isClosed) System.out.println("已连接上数据库!")
// else System.out.println("没有连接到数据库!")
DriverManager.getConnection("jdbc:mysql://localhost:3306/imooc_user?user=root&password=root")
}
//释放数据库连接资源
def release(connection:Connection,pstmt:PreparedStatement): Unit ={
try{
if(pstmt != null){
pstmt.close()
}
}catch{
case e:Exception => e.printStackTrace()
}finally {
if(connection!=null){
connection.close()
}
}
}
def main(args: Array[String]): Unit = {
println(getConnection())
}
}
create table day_video_access_topn_stat (
day varchar(8) not null,
cms_id bigint(10) not null,
times bigint(10) not null,
primary key (day, cms_id)
);
package org.sparksql
import java.sql.{Connection, PreparedStatement}
import scala.collection.mutable.ListBuffer
object StatisticsDAO {
def insertDayVideoAccessTopN(list:ListBuffer[DayVideoAccessStatistics]): Unit ={
var connection:Connection = null
var pstmt:PreparedStatement = null
try{
connection= MySqlUtils.getConnection()
//取消自动提交
connection.setAutoCommit(false)
val sql = "insert into day_video_access_topn_stat(day,cms_id,times) value (? ,? ,? )"
pstmt = connection.prepareStatement(sql)
for(i<-list){
pstmt.setString(1,i.day)
pstmt.setLong(2,i.cmsId)
pstmt.setLong(3,i.times)
pstmt.addBatch()
}
pstmt.executeBatch()//批量处理
//手动提交
connection.commit()
}catch {
case e:Exception=>e.printStackTrace()
}finally {
MySqlUtils.release(connection,pstmt)
}
}
}
package org.sparksql
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.apache.spark.sql.functions._
import scala.collection.mutable.ListBuffer
object TopNApp {
//最受欢迎
def videoAccessTopN(spark: SparkSession, accessDF: DataFrame) = {
import spark.implicits._
val videoTopNDF = accessDF.filter($"day"==="20170511"&& $"cmsType" === "video")
.groupBy("day","cmsId").agg(count("cmsId")
.as("times")).orderBy($"times".desc)
videoTopNDF.show()
try{
videoTopNDF.foreachPartition(partitionOfRecords =>{
val list = new ListBuffer[DayVideoAccessStatistics]
partitionOfRecords.foreach(info =>{
val day = info.getAs[String]("day")
val cmsId = info.getAs[Long]("cmsId")
val times = info.getAs[Long]("times")
list.append(DayVideoAccessStatistics(day,cmsId,times))
})
StatisticsDAO.insertDayVideoAccessTopN(list)
})
}catch {
case e:Exception =>e.printStackTrace()
}
}
java.sql.SQLException: No value specified for parameter 2
检查插入参数和类型是否一直
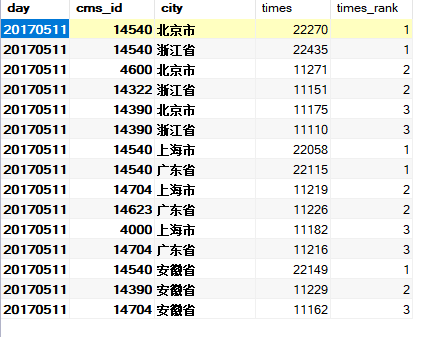
按照省份
create table day_video_city_access_topn_stat (
day varchar(8) not null,
cms_id bigint(10) not null,
city varchar(20) not null,
times bigint(10) not null,
times_rank int not null,
primary key (day, cms_id, city)
);
def cityAccessTopN(spark: SparkSession, accessDF: DataFrame) = {
import spark.implicits._
val cityTopNDF = accessDF.filter($"day"==="20170511"&& $"cmsType" === "video")
.groupBy("day","city","cmsId").agg(count("cmsId")
.as("times")).orderBy($"times".desc)
cityTopNDF.show()
val top3DF = cityTopNDF.select(
cityTopNDF("day"),
cityTopNDF("city"),
cityTopNDF("cmsId"),
cityTopNDF("times"),
row_number().over(Window.partitionBy(cityTopNDF("city"))
.orderBy(cityTopNDF("times").desc)).as("times_rank")
).filter("times_rank <=3")//.show()
try{
top3DF.foreachPartition(partitionOfRecords =>{
val list = new ListBuffer[DayCityAccessStatistics]
partitionOfRecords.foreach(info =>{
val day = info.getAs[String]("day")
val cmsId = info.getAs[Long]("cmsId")
val city = info.getAs[String]("city")
val times = info.getAs[Long]("times")
val timesRank = info.getAs[Int]("times_rank")
list.append(DayCityAccessStatistics(day,cmsId,city,times,timesRank))
})
StatisticsDAO.insertCityVideoAccessTopN(list)
})
}catch {
case e:Exception =>e.printStackTrace()
}
}
按照流量
create table day_video_traffics_topn_stat (
day varchar(8) not null,
cms_id bigint(10) not null,
traffics bigint(20) not null,
primary key (day, cms_id)
);
def trafficAccessTopN(spark: SparkSession, accessDF: DataFrame) = {
import spark.implicits._
val trafficTopNDF = accessDF.filter($"day"==="20170511"&& $"cmsType" === "video")
.groupBy("day","cmsId").agg(sum("traffic").as("traffics"))
.orderBy($"traffics".desc)
trafficTopNDF.show()
try{
trafficTopNDF.foreachPartition(partitionOfRecords =>{
val list = new ListBuffer[DayTrafficAccessStatistics]
partitionOfRecords.foreach(info =>{
val day = info.getAs[String]("day")
val cmsId = info.getAs[Long]("cmsId")
val traffics = info.getAs[Long]("traffics")
list.append(DayTrafficAccessStatistics(day,cmsId,traffics))
})
StatisticsDAO.insertTrafficVideoAccessTopN(list)
})
}catch {
case e:Exception =>e.printStackTrace()
}
}
优化
- 每次更新删除前面的数据
def deleteData(day:String)={
val tables= Array("day_video_traffics_topn_stat","day_video_city_access_topn_stat","day_video_access_topn_stat")
var connection:Connection = null
var pstmt:PreparedStatement = null
try{
connection = MySqlUtils.getConnection()
for(table<- tables){
val deleteSQL = s"delete from $table where day = ?"
pstmt = connection.prepareStatement(deleteSQL)
pstmt.setString(1,day)
pstmt.executeUpdate()
}
}catch {
case e:Exception => e.printStackTrace()
}finally {
MySqlUtils.release(connection, pstmt)
}
}
数据可视化
数据可视化:一副图片最伟大的价值莫过于它能够使得我们实际看到的比我们期望看到的内容更加丰富
常见的可视化框架
1)echarts
2)highcharts
3)D3.js
4)HUE
5)Zeppelin
echarts
package org.sparkSQL.Utils;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
public class MySqlUtils {
private static final String USERNAME = "root";
private static final String PASSWORD = "root";
private static final String DRIVERCLASS = "com.mysql.jdbc.Driver";
private static final String URL = "jdbc:mysql://localhost:3306/imooc_user";
public static Connection getConnection(){
Connection connection = null;
try {
Class.forName(DRIVERCLASS);
connection = DriverManager.getConnection(URL,USERNAME,PASSWORD);
}catch (Exception e){
e.printStackTrace();
}
return connection;
}
public static void release(Connection connection, PreparedStatement pstmt , ResultSet rs){
if(rs != null){
try{
rs.close();
}catch (Exception e){
e.printStackTrace();
}
}
if(connection != null){
try{
connection.close();
}catch (Exception e){
e.printStackTrace();
}
}
if(pstmt != null){
try{
pstmt.close();
}catch (Exception e){
e.printStackTrace();
}
}
}
public static void main(String[] args) {
System.out.println(getConnection());
}
}
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>ECharts</title>
<!-- 引入 echarts.js -->
<script src="https://cdn.bootcss.com/echarts/3.7.1/echarts.min.js"></script>
<script src="https://s3.pstatp.com/cdn/expire-1-M/jquery/3.1.1/jquery.min.js"></script>
</head>
<body>
<!-- 为ECharts准备一个具备大小(宽高)的Dom -->
<div id="main" style="width: 600px;height:400px;"></div>
<script type="text/javascript">
// 基于准备好的dom,初始化echarts实例
var myChart = echarts.init(document.getElementById('main'));
// 指定图表的配置项和数据
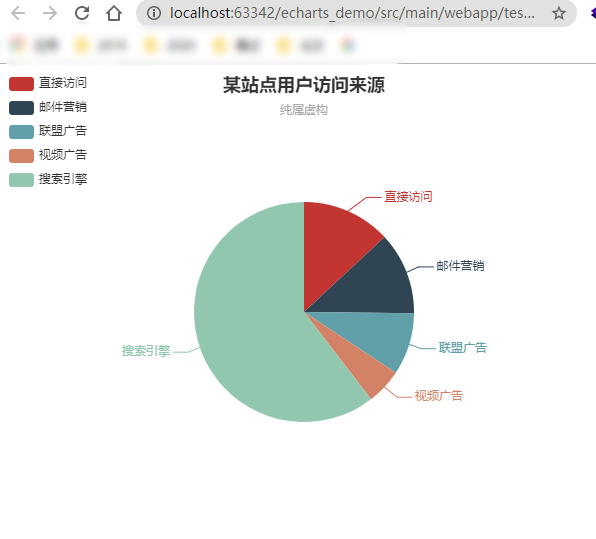
var option = {
title: {
text: '最受欢迎的TOPN',
subtext: '测试',
left: 'center'
},
tooltip: {
trigger: 'item',
formatter: '{a} <br/>{b} : {c} ({d}%)'
},
legend: {
orient: 'vertical',
left: 'left',
data: ['直接访问', '邮件营销', '联盟广告', '视频广告', '搜索引擎']
},
series: [
{
name: '访问次数',
type: 'pie',
radius: '55%',
center: ['50%', '60%'],
data: (function(){
var courses= [];
$.ajax({
type:"GET",
url:"stat?day=20170511",
dataType:'json',
async:false,
success:function (result){
for(var i=0;i<result.length;i++){
courses.push({"value":result[i].value,"name":result[i].name})
}
}
})
return courses;
})(),
emphasis: {
itemStyle: {
shadowBlur: 10,
shadowOffsetX: 0,
shadowColor: 'rgba(0, 0, 0, 0.5)'
}
}
}
]
};
// 使用刚指定的配置项和数据显示图表。
myChart.setOption(option);
</script>
</body>
</html>
[hadoop@hadoop001 software]$ tar -zxvf zeppelin-0.7.1-bin-all.tgz -C ~/app/
[hadoop@hadoop001 bin]$ ./zeppelin-daemon.sh start
Log dir doesn't exist, create /home/hadoop/app/zeppelin-0.7.1-bin-all/logs
Pid dir doesn't exist, create /home/hadoop/app/zeppelin-0.7.1-bin-all/run
Zeppelin start
最后
以上就是顺利大白最近收集整理的关于大数据进阶之路——Spark SQL日志分析的全部内容,更多相关大数据进阶之路——Spark内容请搜索靠谱客的其他文章。








发表评论 取消回复