目录
Goal:监听上传Hive日志文件到HDFS
How:
1.拷贝Hadoop相关jar到Flume的lib目录下:
2.创建flume-hive-hdfs.conf文件:
3.开启你的集群然后执行监控配置:
Done:
作为一个程序员,郁闷的事情是,面对一个代码块,却不敢去修改,更糟糕的是,这个代码块还是自己写的。--摘自前端入门到精通
Goal:监听上传Hive日志文件到HDFS
类似如下情景,hive产生的日志通过Flume上传到HDFS上。
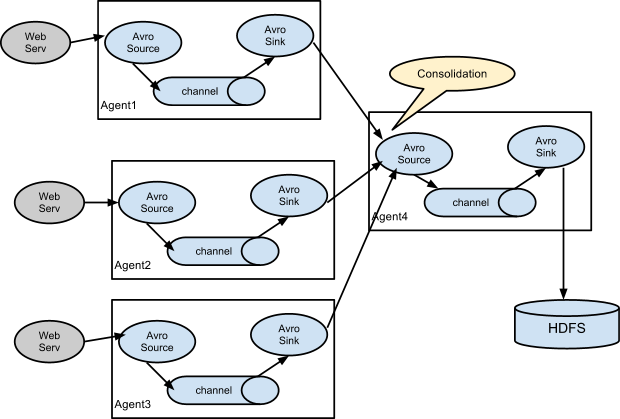
How:
1.拷贝Hadoop相关jar到Flume的lib目录下:
hadoop相关jar包目录在hadoop下:
share/hadoop/common/lib/hadoop-auth-2.5.0-cdh5.3.6.jar
share/hadoop/common/lib/commons-configuration-1.6.jar
share/hadoop/common/hadoop-common-2.5.0-cdh5.3.6.jar
share/hadoop/mapreduce1/lib/hadoop-hdfs-2.5.0-cdh5.3.6.jarFlume的lib目录:[你存放flume的根目录]/apache-flume-1.5.0-cdh5.3.6-bin/lib
2.创建flume-hive-hdfs.conf文件:
文件内容如下:
# Name the components on this agent
agent_hive.sources = exec-tail-hive-source
agent_hive.sinks = hdfs-mycluster-sink
agent_hive.channels = mem-channel-1
# properties of exec-tail-hive-source
agent_hive.sources.exec-tail-hive-source.type = exec
agent_hive.sources.exec-tail-hive-source.command = tail -f /opt/module/hive-0.13.1-cdh5.3.6/logs/hive.log
agent_hive.sources.exec-tail-hive-source.shell = /bin/bash -c
# properties of hdfs-mycluster-sink
agent_hive.sinks.hdfs-mycluster-sink.type = hdfs
agent_hive.sinks.hdfs-mycluster-sink.hdfs.path = hdfs://hadoop130:8020/flume/hivelogs/%Y%m%d/%H
#上传文件的前缀
agent_hive.sinks.hdfs-mycluster-sink.hdfs.filePrefix = events-hive-
#是否按照时间滚动文件夹
agent_hive.sinks.hdfs-mycluster-sink.hdfs.round = true
#多少时间单位创建一个新的文件夹
agent_hive.sinks.hdfs-mycluster-sink.hdfs.roundValue = 1
#重新定义时间单位
agent_hive.sinks.hdfs-mycluster-sink.hdfs.roundUnit = hour
#是否使用本地时间戳
agent_hive.sinks.hdfs-mycluster-sink.hdfs.useLocalTimeStamp = true
#积攒多少个Event才flush到HDFS一次
agent_hive.sinks.hdfs-mycluster-sink.hdfs.batchSize = 1000
#设置文件类型,可支持压缩
agent_hive.sinks.hdfs-mycluster-sink.hdfs.fileType = DataStream
#多久生成一个新的文件
agent_hive.sinks.hdfs-mycluster-sink.hdfs.rollInterval = 600
#设置每个文件的滚动大小
agent_hive.sinks.hdfs-mycluster-sink.hdfs.rollSize = 134217700
#文件的滚动与Event数量无关
agent_hive.sinks.hdfs-mycluster-sink.hdfs.rollCount = 0
#最小冗余数
agent_hive.sinks.hdfs-mycluster-sink.hdfs.minBlockReplicas = 1
# Bind the source and sink to the channel
agent_hive.sources.exec-tail-hive-source.channels = mem-channel-1
agent_hive.sinks.hdfs-mycluster-sink.channel = mem-channel-1 3.开启你的集群然后执行监控配置:
[feng@hadoop129 apache-flume-1.5.0-cdh5.3.6-bin]$ bin/flume-ng agent --conf conf/ --conf-file conf/flume-hive-hdfs.conf --name agent_hive 
Done:
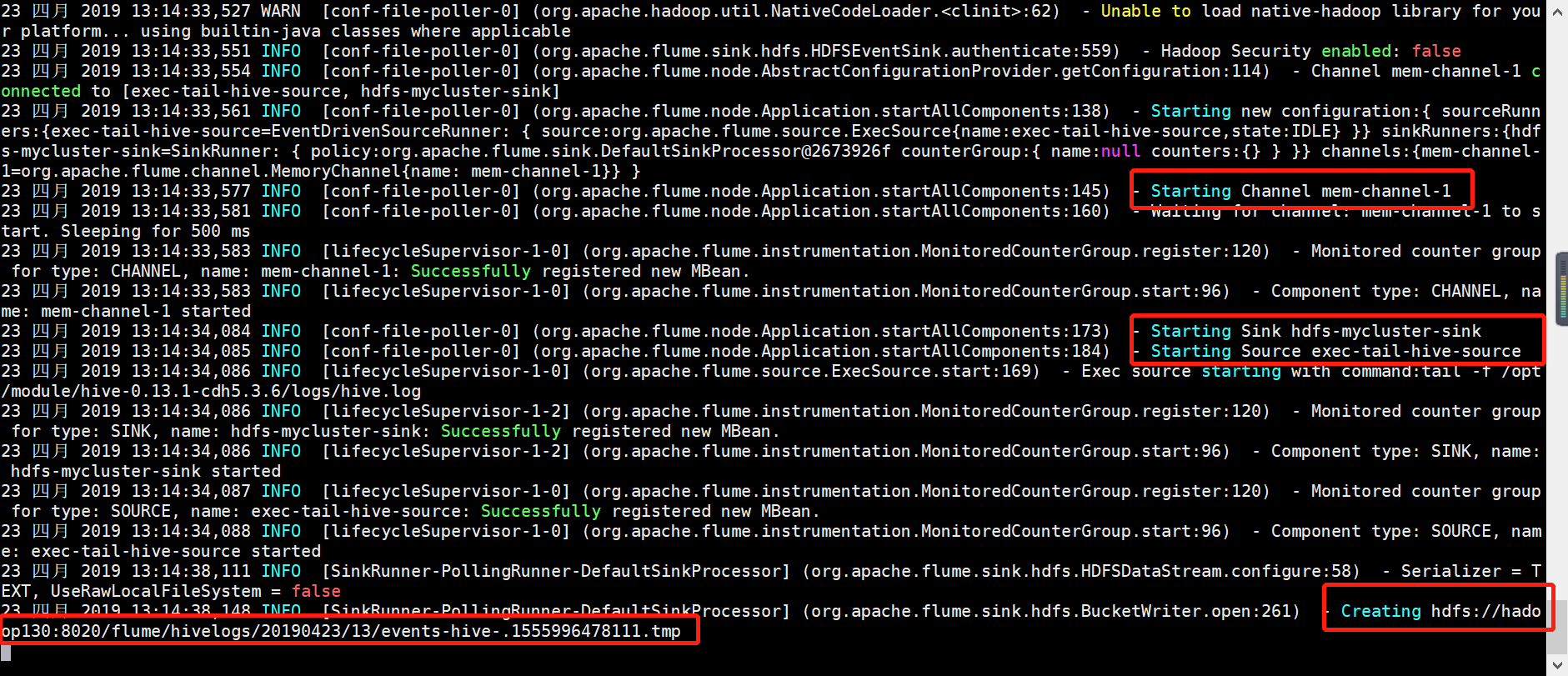
如果tail flume.log日志发现如下信息,恭喜你,,大功告成啦:
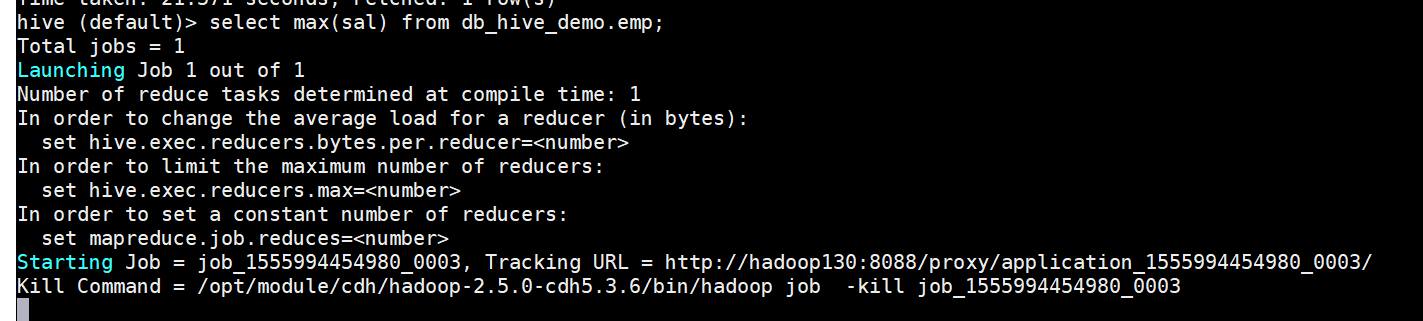
随便执行hive查询,产生日志:
登录hdfs web管理页面可以查看到如下
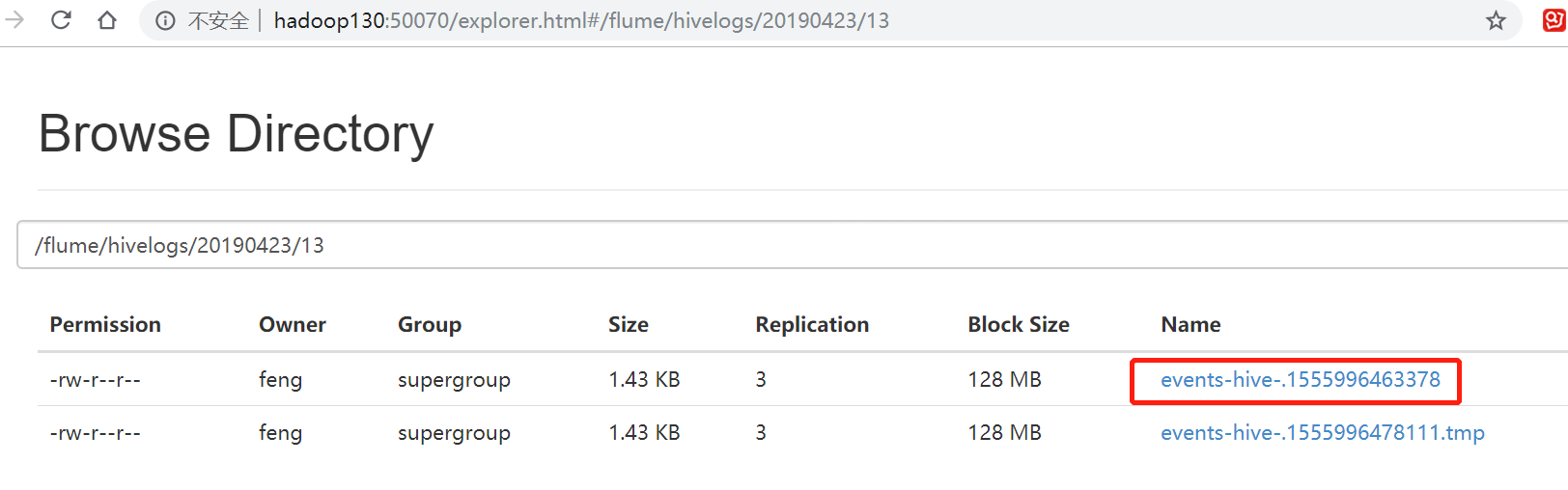
下载文件可以到结尾是0003的job:
参考:
尚学堂大数据视频教程
Flume官方文档
最后
以上就是生动向日葵最近收集整理的关于我的大数据之路 - Flume 案例:监听上传Hive日志文件到HDFS的全部内容,更多相关我的大数据之路内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复