Quartz定时任务框架
Quartz是一个任务调度框架。总结起来就是在某一个有规律的时间点干某件事。并且时间的触发的条件可以非常复杂(比如每月最后一个工作日的17:50),复杂到需要一个专门的框架来干这个事。 Quartz就是来干这样的事,你给它一个触发条件的定义,它负责到了时间点,触发相应的Job起来干活。
核心元素
- Scheduler:调度容器,一个调度容器可以注册多个jobDetail和Trigger 当jobDetail与trigger组合了就可以被Scheduler容器调度。
- Trigger: 定义触发的条件。代表一个调度参数的配置,什么时候去调。
- JobDetail & Job: JobDetail 定义的是一个可执行的调度程序,而真正的执行逻辑是在Job中, 为什么设计成JobDetail + Job,不直接使用Job?这是因为任务是有可能并发执行,如果Scheduler直接使用Job,就会存在对同一个Job实例并发访问的问题。而JobDetail & Job 方式,sheduler每次执行,都会根据JobDetail创建一个新的Job实例,这样就可以规避并发访问的问题。
关系图如下: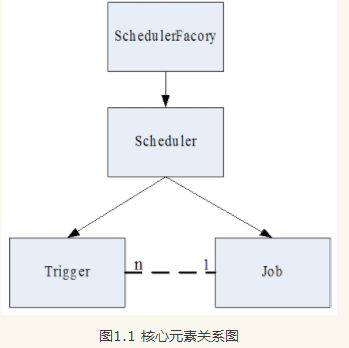
作业调度的实现
1:项目导入quartz的jar包
2:定义一个类继承QuartzJobBean 重写executeInternal方法,获取一个作业调度(schedual)

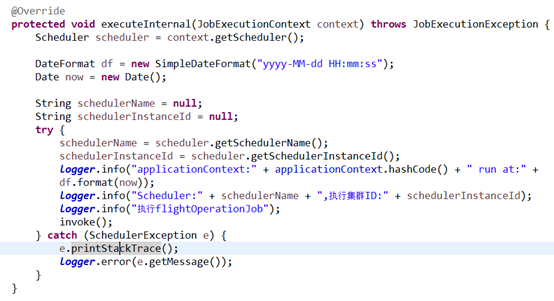
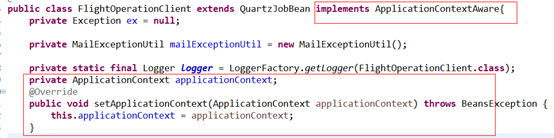
这里实现了ApplicationContextAware的接口,是因为定时任务job是在quartz中实例化出来的,不受spring容器的管理。所以这里用注解注入服务类是注入不了的
ApplicationContextAware接口
在Web应用中,Spring容器通常采用声明式方式配置产生:开发者只要在web.xml中配置一个Listener,该Listener将会负责初始化Spring容器,MVC框架可以直接调用Spring容器中的Bean,无需访问Spring容器本身。在这种情况下,容器中的Bean处于容器管理下,无需主动访问容器,只需接受容器的依赖注入即可。

ContextLoaderListener监听器的作用就是启动Web容器时,自动装配(Spring容器)ApplicationContext的配置信息。如果在web.xml中不写任何参数配置信息,默认的路径是/WEB-INF/applicationContext.xml,在WEB-INF目录下创建的xml文件的名称必须是applicationContext.xml;如果是要自定义文件名可以在web.xml里加入contextConfigLocation这个context参数:
但在某些特殊的情况下 ,Bean需要实现某个功能,但该功能必须借助于Spring容器才能实现,此时就必须让该Bean先获取Spring容器,然后借助于Spring容器实现该功能。为了让Bean获取它所在的Spring容器,可以让该Bean实现ApplicationContextAware接口。
Spring容器会检测容器中的所有Bean,如果发现某个Bean实现了ApplicationContextAware接口,Spring容器会在创建该Bean之后,自动调用该Bean的setApplicationContextAware()方法,调用该方法时,会将容器本身作为参数传给该方法——该方法中的实现部分将Spring传入的参数(容器本身)赋给该类对象的applicationContext实例变量,因此接下来可以通过该applicationContext实例变量来访问容器本身。就可以获取容器中其他的bean了

Quartz Job数据存储
Quartz中的trigger和job需要存储下来才能被使用。Quartz中有两种存储方式:RAMJobStore,JobStoreSupport,其中RAMJobStore是将trigger和job存储在内存中,而JobStoreSupport是基于jdbc将trigger和job存储到数据库中。RAMJobStore的存取速度非常快,但是由于其在系统被停止后所有的数据都会丢失,所以在集群应用中,必须使用JobStoreSupport。
将定时任务持久化到数据库
![]()
创建定时任务数据库表
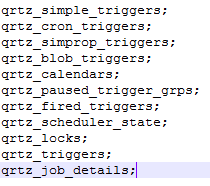
这些表都是以QRTZ_为前缀的,这是默认的前缀。如果你需要用到其他前缀(个性化需求,或需要配置多个quartz实例),可以在以下项配置(在quartz.properties中)。
![]()
quartz集群
一个Quartz集群中的每个节点是一个独立的Quartz应用,必须对每个节点分别启动或停止,节点与节点之间通过共享数据库信息感知。
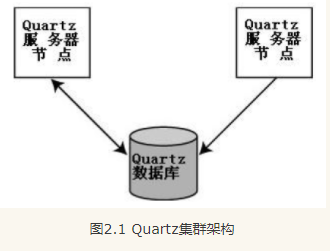
Scheduler在集群中的启动流程
Quartz Scheduler自身是察觉不到被集群的,只有配置给Scheduler的JDBC JobStore才知道。当Quartz Scheduler启动时,它调用JobStore的schedulerStarted()方法,它告诉JobStore Scheduler已经启动了。schedulerStarted() 方法是在JobStoreSupport类中实现的。JobStoreSupport类会根据quartz.properties文件中的设置来确定Scheduler实例是否参与到集群中。

假如配置了集群,一个新的ClusterManager类的实例就被创建、初始化并启动。ClusterManager是在JobStoreSupport类中的一个内嵌类,继承了java.lang.Thread,它会定期运行,并对Scheduler实例执行检入的功能。Scheduler也要查看是否有任何一个别的集群节点失败了。检入操作执行周期在quartz.properties中配置。
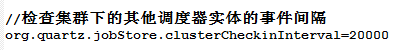
重要配置
默认文件名称quartz.properties,通过设置"org.quartz.jobStore.isClustered"属性为"true"来激活集群特性。在集群中的每一个实例都必须有一个唯一的"instance id" ("org.quartz.scheduler.instanceId" 属性), 但是应该有相同的"scheduler instance name" ("org.quartz.scheduler.instanceName"),也就是说集群中的每一个实例都必须使用相同的quartz.properties 配置文件。除了以下几种例外,配置文件的内容其他都必须相同:
a.线程池大小。
b.不同的"org.quartz.scheduler.instanceId"属性值(通过设定为"AUTO"即可)。

注意事项
时间同步问题
Quartz实际并不关心你是在相同还是不同的机器上运行节点。当集群放置在不同的机器上时,称之为水平集群。节点跑在同一台机器上时,称之为垂直集群。对于垂直集群,存在着单点故障的问题。这对高可用性的应用来说是无法接受的,因为一旦机器崩溃了,所有的节点也就被终止了。对于水平集群,存在着时间同步问题。
节点用时间戳来通知其他实例它自己的最后检入时间。假如节点的时钟被设置为将来的时间,那么运行中的Scheduler将再也意识不到那个结点已经宕掉了。另一方面,如果某个节点的时钟被设置为过去的时间,也许另一节点就会认定那个节点已宕掉并试图接过它的Job重运行。最简单的同步计算机时钟的方式是使用某一个Internet时间服务器(Internet Time Server ITS)。
节点争抢Job问题
因为Quartz使用了一个随机的负载均衡算法, Job以随机的方式由不同的实例执行。Quartz官网上提到当前,还不存在一个方法来指派(钉住) 一个 Job 到集群中特定的节点
quartz线程
负责任务调度的几个线程:
(1)任务执行线程:通常使用一个线程池(SimpleThreadPool)维护一组线程,负责实际每个job的执行。
(2)Scheduler调度线程QuartzSchedulerThread :轮询存储的所有 trigger,如果有需要触发的 trigger,即到达了下一次触发的时间,则从任务执行线程池获取一个空闲线程,执行与该 trigger 关联的任务。
(3)处理misfire job的线程MisfireHandler:轮训所有misfire的trigger,原理就是从数据库中查询所有下次触发时间小于当前时间的trigger,按照每个trigger设定的misfire策略处理这些trigger。
misfire job(没有正常触发的任务)
没有在正常触发时间点触发的任务。主要由一下几种情况导致:
触发时间在应用不可用的时间内,
- 重启
- 上次的执行时间过长,超过了下次触发的时间
- 任务被暂停一段时间后,重新被调度的时间在下次触发时间之后
处理misfire job的策略,需要在创建trigger的时候配置,每种trigger对应的枚举值都不同,具体在接口里面有定义。CronTrigger有2种处理misfire的策略:

quartz常用注解
@SuppressWarnings
@SuppressWarnings作用:用于抑制编译器产生警告信息。
@SuppressWarnings(all):抑制所有类型的警告(感叹号)
@DisallowConcurrentExecution
Quartz定时任务默认都是并发执行的,不会等待上一次任务执行完毕,只要间隔时间到就会执行, 如果定时任执行太长,会长时间占用资源,导致其它任务堵塞。
可以在Spring配置中设置concurrent的值为false, 禁止并发执行。
<property name="concurrent" value="false" />
也可以在job类 上面加上@DisallowConcurrentExecution注解。
此标记用在实现Job的类上面,意思是Job(任务)的执行时间[比如需要10秒]大于任务的时间间隔[Interval(5秒)],那么默认情况下,调度框架为了能让 任务按照我们预定的时间间隔执行,会马上启用新的线程执行任务。否则的话会等待任务执行完毕以后 再重新执行!(这样会导致任务的执行不是按照我们预先定义的时间间隔执行)
设定的时间间隔为3秒,但job执行时间是5秒,设置@DisallowConcurrentExecution以后程序会等任务执行完毕以后再去执行,否则会在3秒时再启用新的线程执行
@PersistJobDataAfterExecution
在默认情况下 也就是没有设置 @PersistJobDataAfterExecution的时候 每个job都拥有独立JobDataMap,否则该任务在重复执行的时候具有相同的JobDataMap,也就是说,如果你在任务里修改了里面的值,会对其他Job实例(并发的或者后续的)造成影响
@JsonIgnoreProperties
@JsonIgnoreProperties(ignoreUnknown = true),将这个注解写在类上之后,就会忽略类中不存在的字段,可以满足当前的需要。这个注解还可以指定要忽略的字段。使用方法如下:
@JsonIgnoreProperties({ "legId", "lastModifyTime" })
quartz集群是如何防止并发的。
利用集群共同的数据库信息实现悲观锁,防止同一个job并发执行。
QRTZ_LOCKS就是Quartz集群实现同步机制的行锁表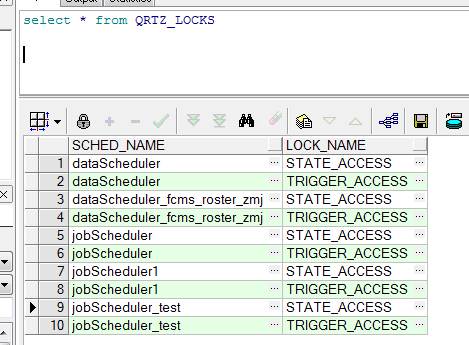
这个sched_name 相对于集群的名字,同一个集群所有节点的sched_name一样。
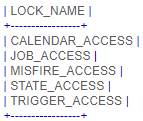
有五种类型的锁。
调度器状态表(QRTZ_SCHEDULER_STATE)
说明:集群中节点实例信息,Quartz定时读取该表的信息判断集群中每个实例的当前状态。
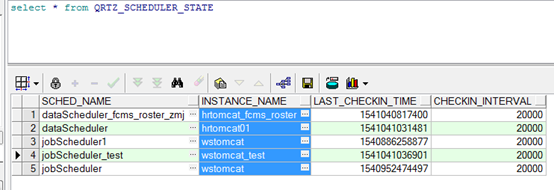
instance_name:配置文件中org.quartz.scheduler.instanceId配置的名字,如果设置为AUTO,quartz会根据物理机名和当前时间产生一个名字。
last_checkin_time:上次检入时间
checkin_interval:检入间隔时间
如何侦测失败的Scheduler节点
当一个Scheduler实例执行检入时,它会查看是否有其他的Scheduler实例在到达他们所预期的时间还未检入。这是通过检查SCHEDULER_STATE表中Scheduler记录在LAST_CHEDK_TIME列的值是否早于org.quartz.jobStore.clusterCheckinInterval来确定的。如果一个或多个节点到了预定时间还没有检入,那么运行中的Scheduler就假定它(们) 失败了。
从故障实例中恢复Job
当一个Sheduler实例在执行某个Job时失败了,有可能由另一正常工作的Scheduler实例接过这个Job重新运行。要实现这种行为,配置给JobDetail对象的Job可恢复属性必须设置为true(job.setRequestsRecovery(true))。如果可恢复属性被设置为false(默认为false),当某个Scheduler在运行该job失败时,它将不会重新运行;而是由另一个Scheduler实例在下一次触发时间触发。Scheduler实例出现故障后多快能被侦测到取决于每个Scheduler的检入间隔(org.quartz.jobStore.clusterCheckinInterval)。
最后
以上就是优雅发箍最近收集整理的关于quartz定时任务实现与运用重要配置注意事项的全部内容,更多相关quartz定时任务实现与运用重要配置注意事项内容请搜索靠谱客的其他文章。








发表评论 取消回复