写在开篇
想学习RocksDB的原因是,公司一个分布书KV存储框架的一次分享,发现他们的底层是用的RocksDB。这样就引起了我的好奇。后来发现公司的好几个框架底层都是使用的RocksDB,包括MySQL 也可以选择RocksDB,所以促使我去了解,为什么要用这个框架。
由于篇幅问题,这个topic会拆成几篇文章完成,本人也是零基础开始学习的,如果有想法可以一起讨论和研究哈。
Design
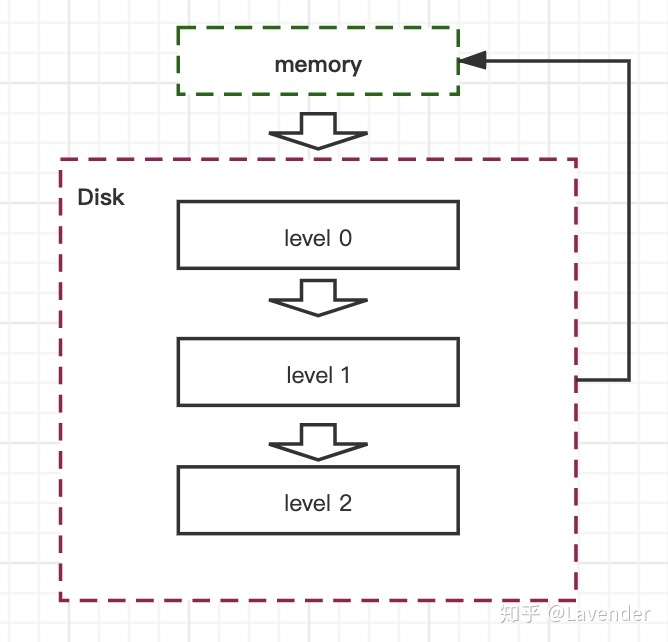
RocksDB的设计思想是数据冷热分离,怎样理解这个“冷热数据”分离呢?新写入的“热数据”会保存在内存中,如果一段时间没有更新,冷数据会“下沉”到磁盘底层的“表层文件”,如果继续没有更新过这个问题,冷数据继续“下沉”到更底层的文件中。如果磁盘底层的冷数据被修改了,它又会再次进入内存,一段时间后又会被持久化刷回到磁盘文件的浅层,然后再慢慢往下移动到底层。
RocksDB是基于LevelDB的思想开发的,想了解其中区别的,可以点击下方链接了解哈
Features not in LevelDBgithub.comPerformance
摘自 RocksDB wiki :
-
-
- it should be performant for fast storage and for server workloads
- It should support efficient point lookups as well as range scans.
- It should be configurable to support high random-read workloads, high update workloads or a combination of both.
- Its architecture should support easy tuning of trade-offs for different workloads and hardware.
-
B Tree & LSM Tree
谈RocksDB就不得不说这两个数据结构了,B tree是我们常见的数据结构,尤其是B+ tree, 学习MySQL 索引的同学应该都会或多或少了解过
B Tree
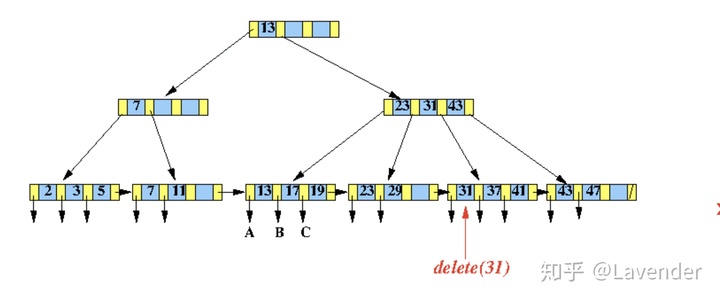
简单过一下B+tree 好处:
- 非叶子节点不存储数据,只记录索引,在相同内存下,可以存储更多的索引。
- 叶子节点存储实际记录行,磁盘上的位置相对紧密。
- 叶子之间增加链表,范围查询更加快,不用再进行中序遍历。
由于“数据预读”和“局部性原理”,每次磁盘读写都是一页一页来读,这种设计很适合范围查询,也就是“顺序读”。
如果遇到了“随机写”,会发生什么呢?
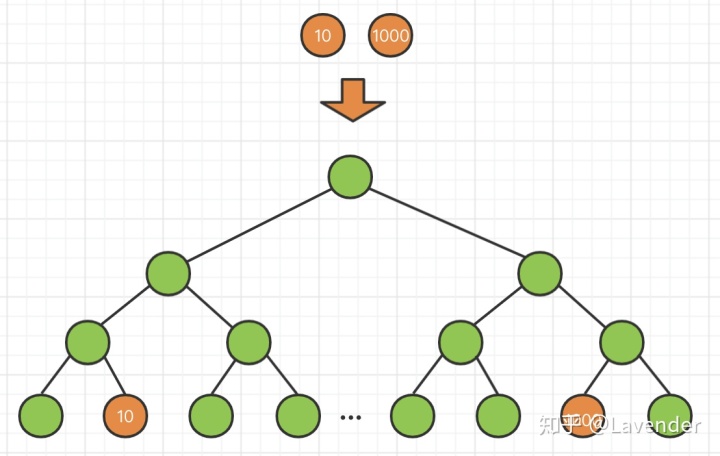
如上图所示,如果我们同时插入10和1000,这两个值在叶子节点的距离很远,这样会导致,我们存在磁盘的距离很远,也就是有可能不在同一页,那么我们就需要多次写IO,才能完成数据的插入,而写占用了大量的磁盘IO,那么读的性能也会受到影响。
为了解决这个问题LSM tree 应运而生,具体可参考
https://www.cs.umb.edu/~poneil/lsmtree.pdfwww.cs.umb.eduLSM
- 适合于高频写入的同时,提供快速地查找,通过牺牲了部分读性能,用来大幅提高写性能。这个设计思想的依据是:
- 内存的速度超磁盘1000倍以上。而读取的性能提升,主要还是依靠内存命中率而非磁盘读的次数
- 写入不占用磁盘的IO,读取就能获取更长时间的磁盘IO使用权,从而也可以提升读取效率。
- 数据随机写操作(包括插入、修改、删除也是写)都在内存中进行,这样也一定程度地提成了写的性能。
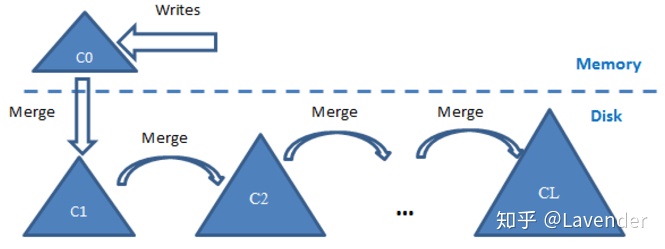
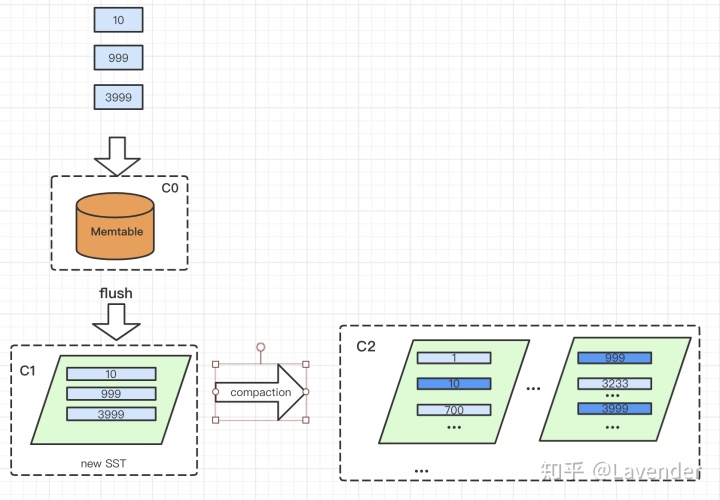
可以看到,LSM tree的“写”,并不强调一开始,就要将新数据放置进,全量active data中,合适的“位置”,假设图5中C2为全量active data。新写入的数据,会先存放在内存中,再一次性flush进disk 的C1处,再从C1 merge 到C2。
下面,我们将详细地介绍RocksDB 内部是如何来处理这个“flush"和"merge"的过程。
最后
以上就是单薄大象最近收集整理的关于rocksdb原理_RocksDB零基础学习(一) What's RocksDB的全部内容,更多相关rocksdb原理_RocksDB零基础学习(一)内容请搜索靠谱客的其他文章。








发表评论 取消回复