写在前文
本文是我自己经过实践记录的,环境搭建简单快速,适合于前期学习(如果想深入了解Kafka、Redis、MySQL集群同步等相关知识本文不适用)。使用canal同步有两种方案,一种是使用canal原始的tcp方式,一种是使用canal+kafka类型;
Canal原理
Canal的服务端伪装成MySQL的从服务器,订阅MySQL的主服务器的binlog日志,实现增量同步数据,保持最终一致性。
1、搭建MySQL环境(Docker安装MySQL)
docker搭建MySQL可以参考其他文章。
配置:my.cnf文件
开启mysql的binlog同步文件,
# 方法一:
log-bin=mysql-bin #添加这一行就ok
binlog-format=ROW #选择row模式
server_id=1 #配置mysql replaction需要定义,不能和canal的slaveId重复
# 方法二:
docker exec mysql bash -c "echo 'log-bin=/var/lib/mysql/mysql-bin' >> /etc/mysql/mysql.conf.d/mysqld.cnf"
docker exec mysql bash -c "echo 'server-id=123454' >> /etc/mysql/mysql.conf.d/mysqld.cnf"
docker restart mysql重启MySQL:docker restart mysql
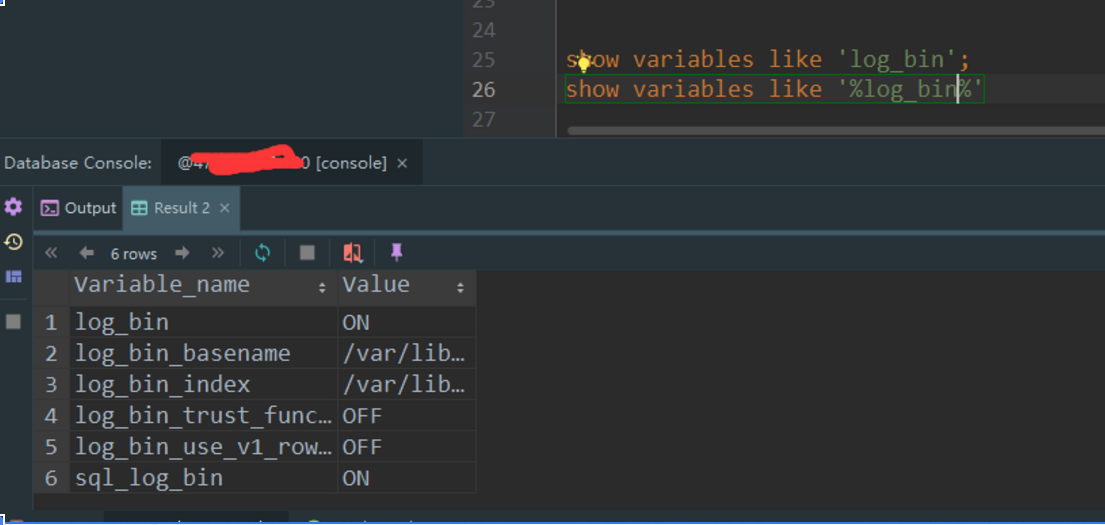
如果没有开启binlog的话,我们在console中执行:show variables like 'log_bin';的值就是OFF(开启后就为ON)。
在MySQL中创建canal账号(可以直接用root,也可以创建一个新的账号)
执行创建用户我的SQL语句:
drop user 'canal'@'%';
CREATE USER 'canal'@'%' IDENTIFIED BY 'canal';
grant all privileges on *.* to 'canal'@'%' identified by 'canal';
flush privileges;注意:如果我们的权限不足的话,如下图。我们在执行程序的时候系统时连接不上MySQL的主节点的,会报权限不足。

2、基于canal的tcp方式同步
架构图
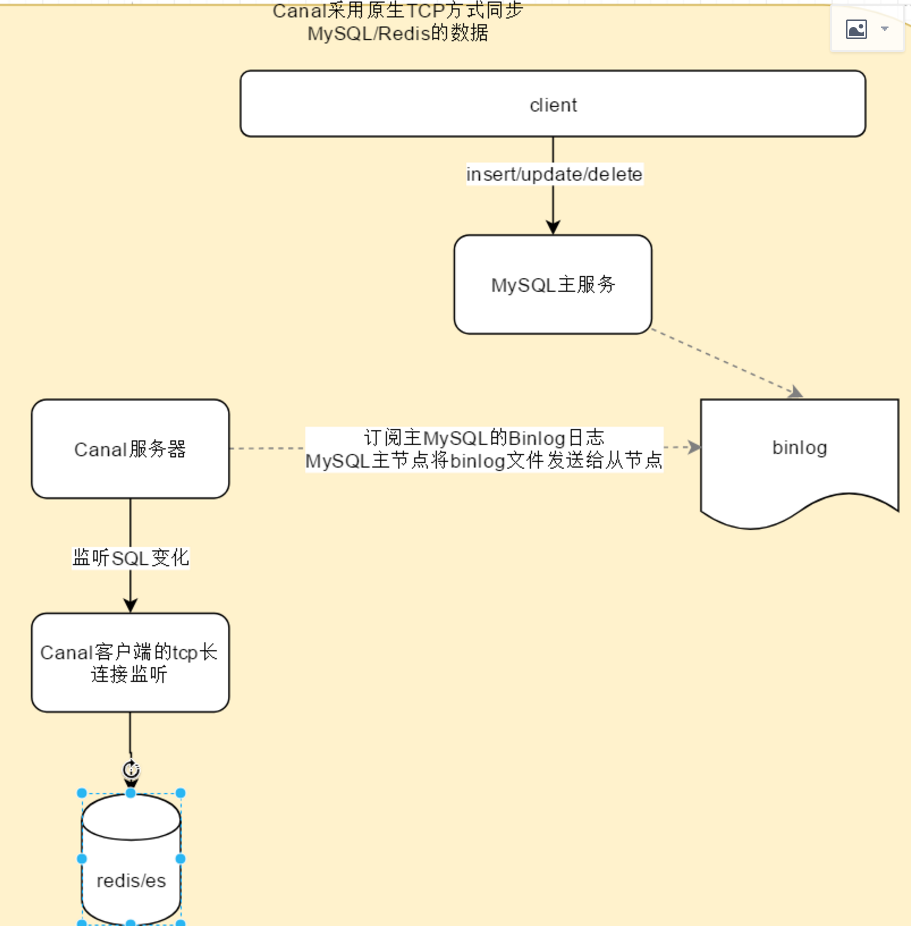
Canal环境搭建
直接解压“canal.deployer-1.1.5-SNAPSHOT.tar.gz”,然后修改 confexample下的
instance.propertie·ce.master.address=127.0.0.1:3306
canal.instance.dbUsername=root
canal.instance.dbPassword=123456
-- 配置需要同步那些数据库(33行)
canal.instance.filter.regex=.*\..*
启动canal:启动bin目录下面的startup.sh/startup.bat代码演示
构建客户端CanalClient
package com.ulting.canal.client;
import com.alibaba.fastjson.JSONObject;
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.protocol.CanalEntry.*;
import com.alibaba.otter.canal.protocol.Message;
import java.net.InetSocketAddress;
import java.util.List;
public class CanalClient {
public static void main(String args[]) {
CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress("127.0.0.1",
11111), "example", "", "");
int batchSize = 100;
try {
connector.connect();
//数据库.表名称
connector.subscribe("ulting_member.user");
connector.rollback();
while (true) {
/* 获取指定数量的数据 */
Message message = connector.getWithoutAck(batchSize);
long batchId = message.getId();
int size = message.getEntries().size();
System.out.println("batchId = " + batchId);
System.out.println("size = " + size);
if (batchId == -1 || size == 0) {
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
} else {
printEntry(message.getEntries());
}
// 提交确认
connector.ack(batchId);
// connector.rollback(batchId); // 处理失败, 回滚数据
}
} finally {
connector.disconnect();
}
}
private static void printEntry(List<Entry> entrys) {
for (Entry entry : entrys) {
if (entry.getEntryType() == EntryType.TRANSACTIONBEGIN || entry.getEntryType() == EntryType.TRANSACTIONEND) {
continue;
}
RowChange rowChage = null;
try {
rowChage = RowChange.parseFrom(entry.getStoreValue());
} catch (Exception e) {
throw new RuntimeException("ERROR ## parser of eromanga-event has an error , data:" + entry.toString(),
e);
}
EventType eventType = rowChage.getEventType();
System.out.println(String.format("================> binlog[%s:%s] , name[%s,%s] , eventType : %s",
entry.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(),
entry.getHeader().getSchemaName(), entry.getHeader().getTableName(),
eventType));
for (RowData rowData : rowChage.getRowDatasList()) {
if (eventType == EventType.DELETE) {
redisDelete(rowData.getBeforeColumnsList());
} else if (eventType == EventType.INSERT) {
redisInsert(rowData.getAfterColumnsList());
} else {
System.out.println("-------> before");
printColumn(rowData.getBeforeColumnsList());
System.out.println("-------> after");
redisUpdate(rowData.getAfterColumnsList());
}
}
}
}
private static void printColumn(List<Column> columns) {
for (Column column : columns) {
System.out.println(column.getName() + " : " + column.getValue() + " update=" + column.getUpdated());
}
}
private static void redisInsert(List<Column> columns) {
JSONObject json = new JSONObject();
for (Column column : columns) {
json.put(column.getName(), column.getValue());
}
if (columns.size() > 0) {
RedisUtil.stringSet(columns.get(0).getValue(), json.toJSONString());
}
}
private static void redisUpdate(List<Column> columns) {
JSONObject json = new JSONObject();
for (Column column : columns) {
json.put(column.getName(), column.getValue());
}
if (columns.size() > 0) {
RedisUtil.stringSet(columns.get(0).getValue(), json.toJSONString());
}
}
private static void redisDelete(List<Column> columns) {
JSONObject json = new JSONObject();
for (Column column : columns) {
json.put(column.getName(), column.getValue());
}
if (columns.size() > 0) {
RedisUtil.delKey(columns.get(0).getValue());
}
}
}
启动redisClient
package com.ulting.canal.client;
import redis.clients.jedis.Jedis;
public class RedisUtil {
private static Jedis jedis = null;
public static synchronized Jedis getJedis() {
if (jedis == null) {
jedis = new Jedis("redis ip", 6379);
}
return jedis;
}
public static boolean existKey(String key) {
return getJedis().exists(key);
}
public static void delKey(String key) {
getJedis().del(key);
}
public static String stringGet(String key) {
return getJedis().get(key);
}
public static String stringSet(String key, String value) {
return getJedis().set(key, value);
}
public static void hashSet(String key, String field, String value) {
getJedis().hset(key, field, value);
}
}3、构建Canal Service(采用kafka方式监听)
架构图
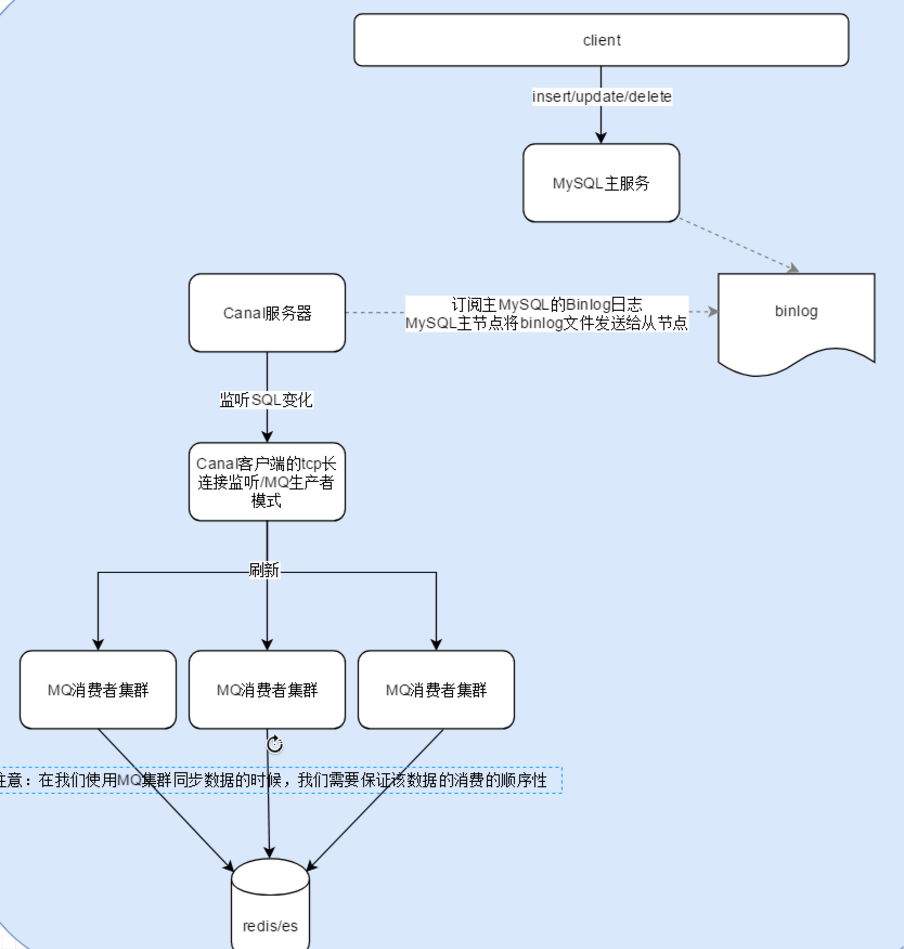
Canal环境搭建
修改canal.properties配置文件
# tcp、kafka、RocketMQ
canal.serviceMode=kafka
# kafka的连接地址
canal.mq.servers = ip:9092
修改instance.properties配置文件
canal.mq.topic=topic名称代码演示
引入依赖
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.1.11.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
</dependencies>application.yml
server:
port: 7270
spring:
application:
name: ulting-member-canal
profiles:
active: dev
kafka:
# kafka服务器地址(可以多个)
bootstrap-servers: kafka ip(公网IP):9092
# listener:
# concurrency: 10
# ack-mode: MANUAL_IMMEDIATE
# poll-timeout: 1500
consumer:
# 指定一个默认的组名
group-id: test-consumer-group1
# earliest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
# latest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据
# none:topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常
# auto-offset-reset: earliest
# key/value的反序列化
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
producer:
# key/value的序列化
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
# 批量抓取
batch-size: 65536
# 缓存容量
buffer-memory: 524288kafka消费端
package com.ulting.canal.member.client;
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
import com.ulting.common.utils.RedisUtils;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
@Component
public class MembetKafkaConsumer {
@Autowired
private RedisUtils redisUtils;
@KafkaListener(topics = "kafka_canal_20200413")
public void receive(ConsumerRecord<?, ?> consumer) {
System.out.println("topic名称:" + consumer.topic() + ",key:" +
consumer.key() + "," +
"分区位置:" + consumer.partition()
+ ", 下标" + consumer.offset() + "," + consumer.value());
String json = (String) consumer.value();
JSONObject jsonObject = JSONObject.parseObject(json);
String type = jsonObject.getString("type");
String pkNames = jsonObject.getJSONArray("pkNames").getString(0);
JSONArray data = jsonObject.getJSONArray("data");
String table = jsonObject.getString("table");
String database = jsonObject.getString("database");
for (int i = 0; i < data.size(); i++) {
JSONObject dataObject = data.getJSONObject(i);
// 分割key名称.
String key = database + ":" + table + ":" + dataObject.getString(pkNames);
switch (type) {
case "UPDATE":
case "INSERT":
redisUtils.setString(key, dataObject.toJSONString());
break;
case "DELETE":
redisUtils.delKey(key);
break;
default: break;
}
}
}
}
写在文章末尾
注意:本人kafka版本为:kafka_2.13-2.4.0;
快速搭建Kafka、MySQL、Redis、ES的单机/集群的环境搭建暂时不演示...待后续更新;如果有需要配套的环境搭建笔记可以给我留言/给我一个邮箱,我可以把我的笔记分享出来。本文呢,我也是自己一点一点踩坑踩出来的。所有的环境均可直接拷贝在Linux用.
最后
以上就是含糊小鸭子最近收集整理的关于大忙人系列_如何使用Canal和kafka解决MySQL与Redis的同步问题?写在前文Canal原理1、搭建MySQL环境(Docker安装MySQL)2、基于canal的tcp方式同步代码演示3、构建Canal Service(采用kafka方式监听)写在文章末尾的全部内容,更多相关大忙人系列_如何使用Canal和kafka解决MySQL与Redis的同步问题?写在前文Canal原理1、搭建MySQL环境(Docker安装MySQL)2、基于canal的tcp方式同步代码演示3、构建Canal内容请搜索靠谱客的其他文章。








发表评论 取消回复