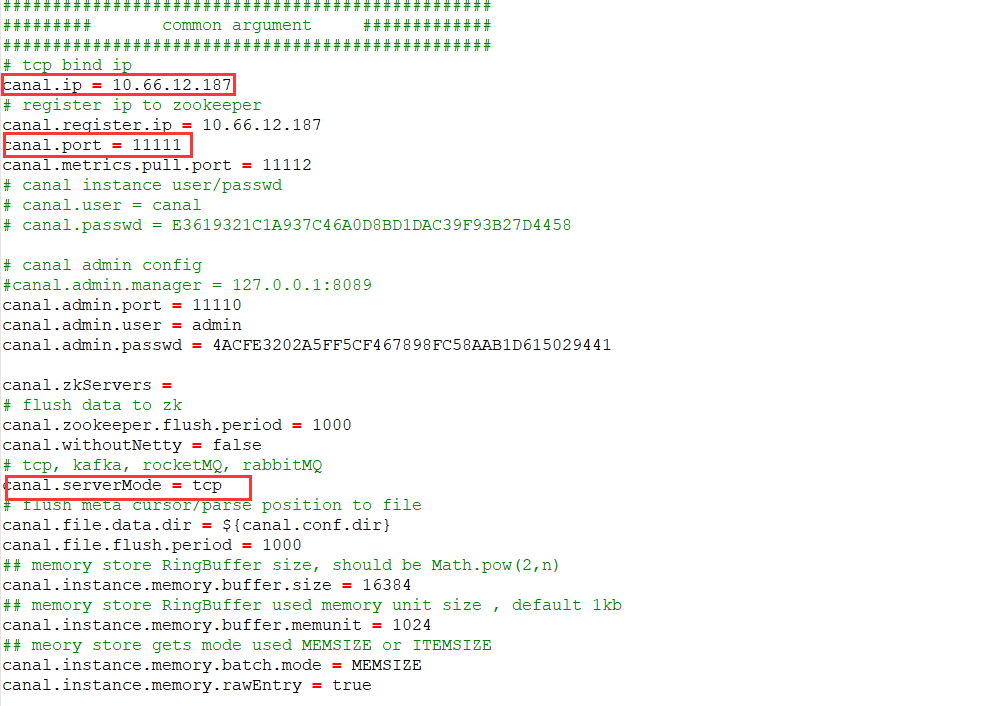
canal.properties 配置
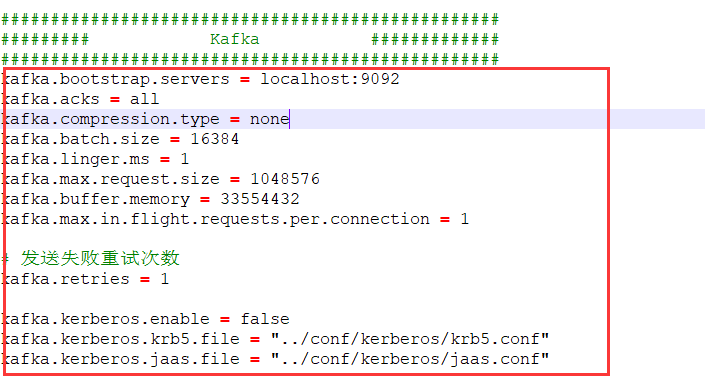
instance.properties 配置
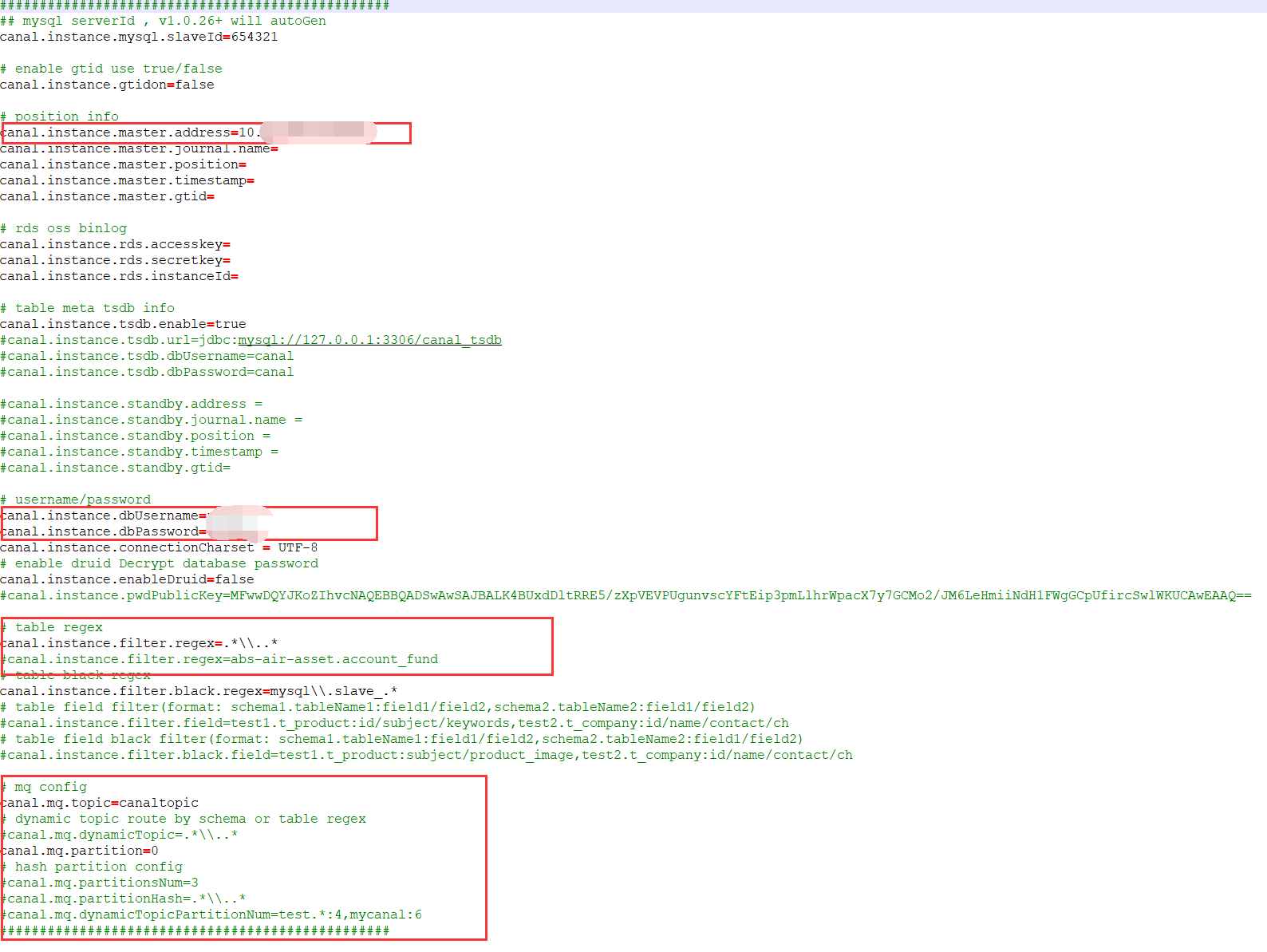
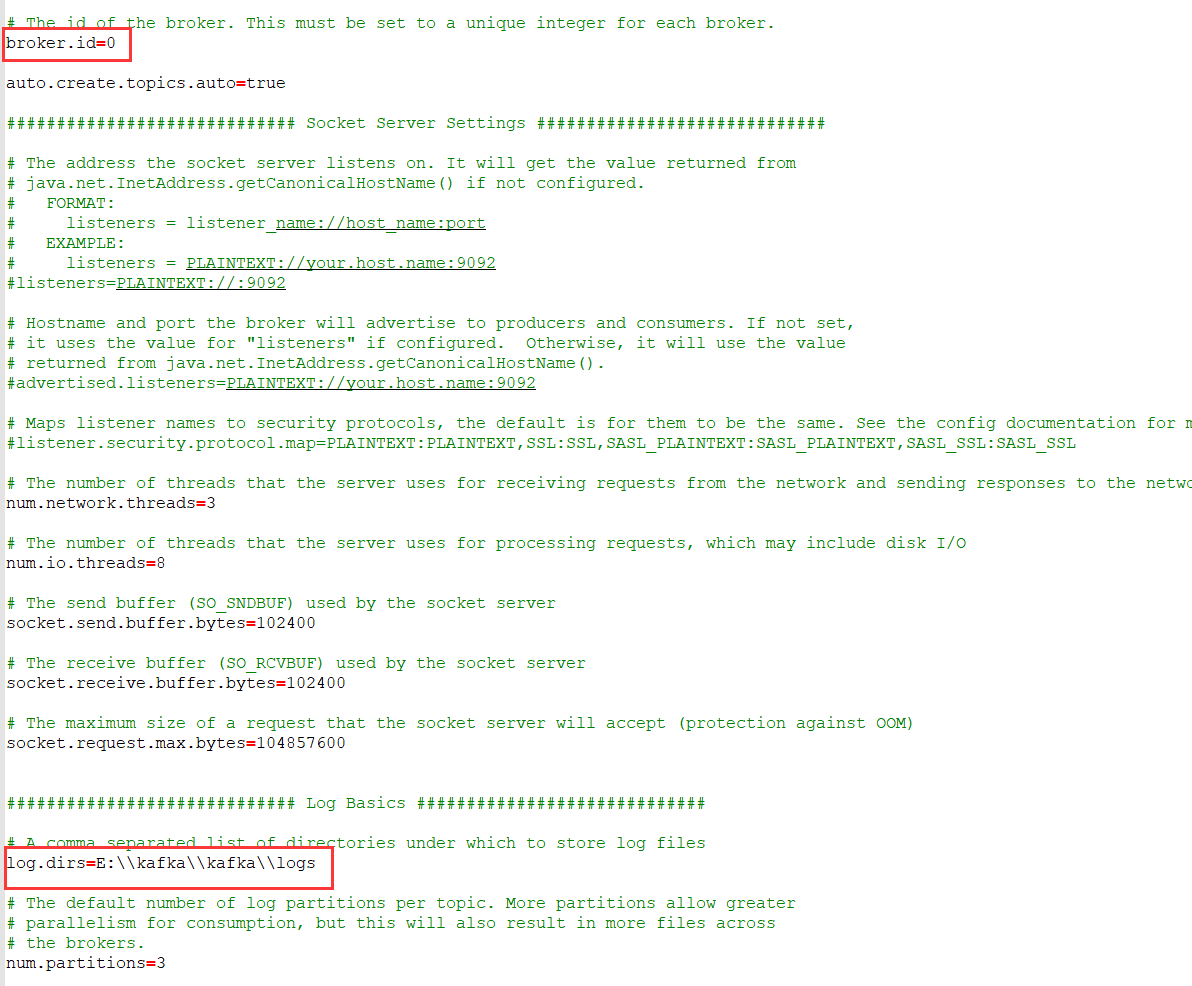
kafka的 server.properties 配置
canal客户端代码
import com.alibaba.fastjson.JSONObject;
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.protocol.CanalEntry;
import com.alibaba.otter.canal.protocol.Message;
import com.example.demo.kafka.KafkaClient;
import org.springframework.stereotype.Component;
import java.net.InetSocketAddress;
import java.util.List;
@Component
public class CannalClient {
private final static int BATCH_SIZE = 1000;
public void canalService() {
// 创建连接
CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress("localhost", 11111), "example", "", "");
try {
// 打开连接
connector.connect();
// 订阅数据库表,全部表
connector.subscribe(".*\..*");
// 回滚到未进行 ack 的地方,下次 fetch 的时候,可以从最后一个没有 ack 的地方开始拿
connector.rollback();
while (true) {
// 获取指定数量的数据
Message message = connector.getWithoutAck(BATCH_SIZE);
// 获取批量 ID
long batchId = message.getId();
// 获取批量的数量
int size = message.getEntries().size();
// 如果没有数据
if (batchId == -1 || size == 0) {
try {
// 线程休眠 2 秒
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
} else {
List entries = message.getEntries();
for (CanalEntry.Entry entry : entries) {
if (entry.getEntryType().equals(CanalEntry.EntryType.ROWDATA)){
if (entry.getEntryType() == CanalEntry.EntryType.TRANSACTIONBEGIN || entry.getEntryType() == CanalEntry.EntryType.TRANSACTIONEND){
continue;
}
// 获取 storevalue,并反序列化
CanalEntry.RowChange rowChage;
try{
rowChage = CanalEntry.RowChange.parseFrom(entry.getStoreValue());
}catch (Exception e){
throw new RuntimeException("ERROR ## parser of eromanga-event has an error , data:" + entry.toString(), e);
}
// 获取当前entry是对哪个表的操作结果
String tableName = entry.getHeader().getTableName();
handle(tableName, rowChage);
}
}
}
connector.ack(batchId);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
connector.disconnect();
}
}
private static void handle(String tableName, CanalEntry.RowChange rowChange){
String canaltopic = "canaltopic";
String partition = "partition10";
//获取操作类型:insert/update/delete类型
CanalEntry.EventType eventType = rowChange.getEventType();
if (eventType.equals(CanalEntry.EventType.INSERT)){
List rowDataList = rowChange.getRowDatasList();
for (CanalEntry.RowData rowData : rowDataList){
JSONObject jsonObject = new JSONObject();
List afterColumnList = rowData.getAfterColumnsList();
for (CanalEntry.Column column : afterColumnList){
jsonObject.put(column.getName(), column.getValue());
}
// 将数据发送到 kafka
KafkaClient.send(canaltopic, partition, jsonObject.toString());
}
}
}
}
kafka 生产者代码
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.springframework.stereotype.Component;
import java.util.*;
@Component
public class KafkaClient {
private static Producer producer;
static {
producer = createProducer();
}
//创建Producer
public static Producer createProducer(){
//kafka连接的配置信息
Properties properties = new Properties();
properties.put("bootstrap.servers","localhost:9092");
properties.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer kafkaProducer = new KafkaProducer<>(properties);
return kafkaProducer;
}
//将数据写入到kafka
public static void send(String topic, String partition, String value){
producer.send(new ProducerRecord<>(topic, partition, value));
}
}
kafka 消费者代码
import java.time.Duration;
import java.util.*;
import java.util.function.Function;
import java.util.stream.Collectors;
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.PartitionInfo;
import org.apache.kafka.common.TopicPartition;
import org.springframework.stereotype.Component;
@Component
public class KafkaConsumerOps{
private static Consumer consumer;
static {
consumer = createConsumer();
}
//创建Producer
public static Consumer createConsumer() {
//kafka连接的配置信息
Properties properties = new Properties();
properties.put("bootstrap.servers","localhost:9092");
properties.put("group.id", "logGroup");
properties.put("enable.auto.commit", "false");
properties.put("session.timeout.ms", "30000");
properties.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
Consumer consu = new KafkaConsumer(properties);
return consu;
}
// 数据从kafka中进行消费
public static void consumerOps(){
//消费者订阅topic
consumer.subscribe(Collections.singletonList("canaltopic")); // 指定 topic 进行消费
try {
while (true) {
ConsumerRecords records = consumer.poll(Duration.ofMillis(300));
for (ConsumerRecord record : records) {
System.out.println("topic ==>> " + record.topic() + ", partition ==>> " + record.partition()
+ ", offset ==>>" + record.offset() + ", key ==>>" + record.key() + ", value ==>>" + record.value());
try{
consumer.commitAsync();
}catch (Exception e){
e.printStackTrace();
}finally {
try {
consumer.commitSync();
}catch (Exception e){
e.printStackTrace();
}
}
}
}
} finally {
consumer.close();
}
}
}
最后
以上就是清秀未来最近收集整理的关于canal同步mysql到kafka,canal同步数据到kafka配置及源码的全部内容,更多相关canal同步mysql到kafka内容请搜索靠谱客的其他文章。








发表评论 取消回复