文章目录
- Metrics-Server
- Metrics-Server简介
- Metrics-Server部署
- 处理报错
- 解决报错一:443端口占用
- 解决报错二:x509证书问题
- dashboard
- dashboard简介
- dashboard部署
- 处理报错
- 测试
- HPA(Horizontal Pod Autoscaler)实例
- HPA简介
- 单度量指标CPU
- 解决虚拟机报错
- 解决报错二
- 多项度量指标CPU+memory
Metrics-Server
Metrics-Server简介
- Metrics-Server是集群核心监控数据的聚合器,用来替换之前的heapster。
- 容器相关的 Metrics 主要来自于 kubelet 内置的 cAdvisor 服务,有了Metrics-Server之后,用户就可以通过标准的 Kubernetes API 来访问到这些监控数据。
(1)Metrics API 只可以查询当前的度量数据,并不保存历史数据。
(2)Metrics API URI 为 /apis/metrics.k8s.io/,在 k8s.io/metrics 维护。
(3)必须部署 metrics-server 才能使用该 API,metrics-server 通过调用 Kubelet Summary API 获取数据。 - 示例:
(1)http://127.0.0.1:8001/apis/metrics.k8s.io/v1beta1/nodes
(2)http://127.0.0.1:8001/apis/metrics.k8s.io/v1beta1/nodes/< node-name >
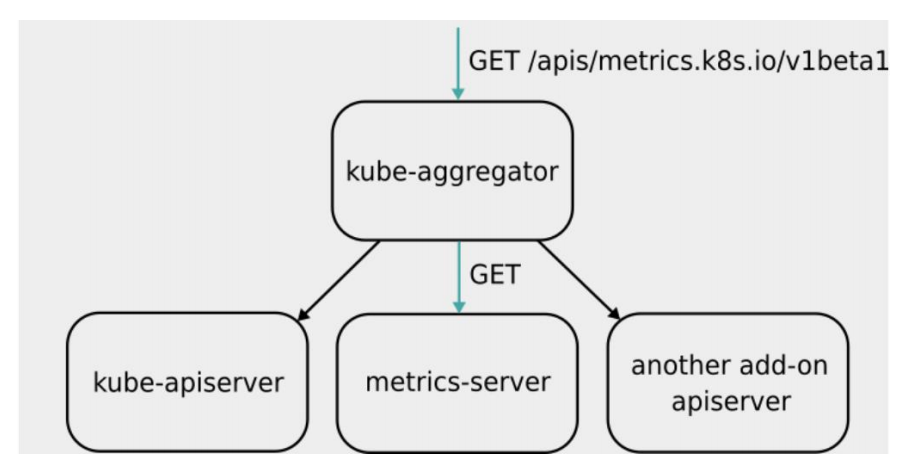
(3)http://127.0.0.1:8001/apis/metrics.k8s.io /v1beta1/namespace/< namespace-name >/pods/< pod-name > - Metrics Server 并不是 kube-apiserver 的一部分,而是通过 Aggregator 这种插件机制,在独立部署的情况下同 kube-apiserver 一起统一对外服务的。
- kube-aggregator 其实就是一个根据 URL 选择具体的 API 后端的代理服务器。
- Metrics-server属于Core metrics(核心指标),提供API metrics.k8s.io,仅提供Node和Pod的CPU和内存使用情况。而其他Custom Metrics(自定义指标)由Prometheus等组件来完成。
Metrics-Server部署
官网下载链接
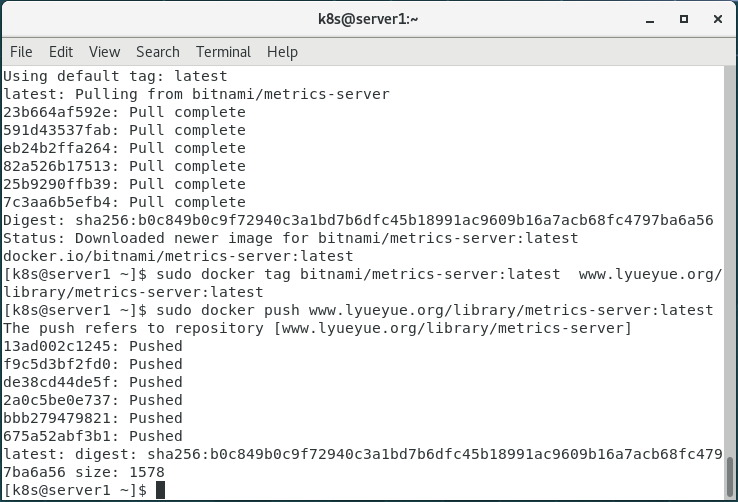
1.拉取镜像并上传到仓库
docker pull bitnami/metrics-server
docker tag bitnami/metrics-server:latest www.lyueyue.org/library/metrics-server:latest
docker push www.lyueyue.org/library/metrics-server:latest
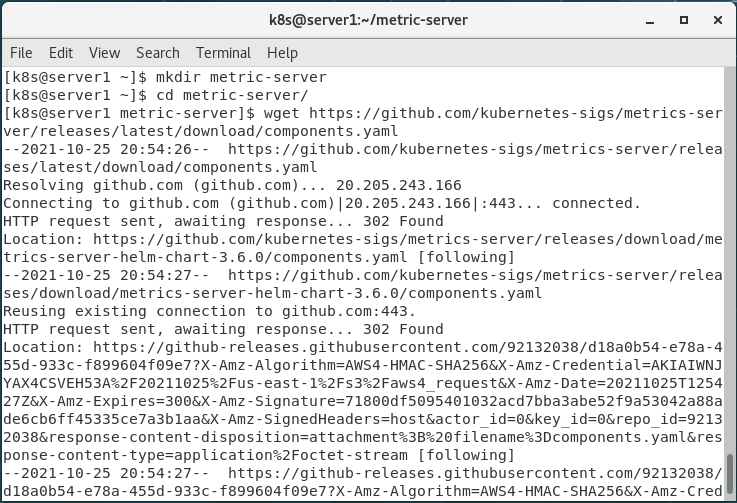
2.建立目录
mkdir metric-server
cd metric-server
3.获取清单文件
wget https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
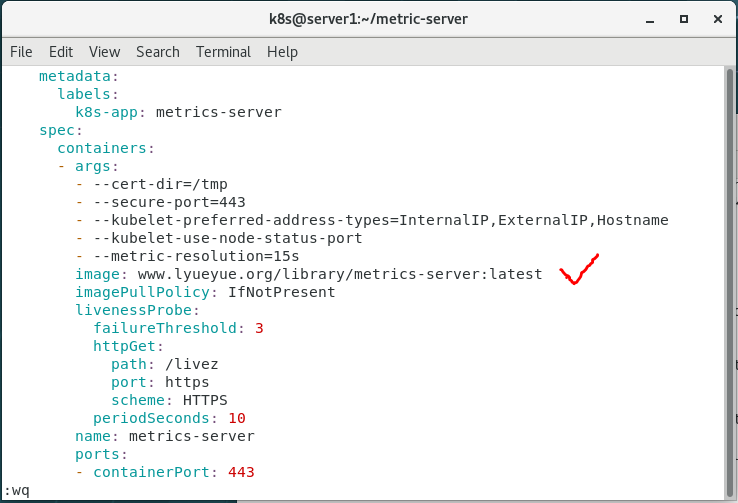
4.修改文件
修改镜像地址
5.解决报错
6.运行文件
kubectl apply -f components.yaml
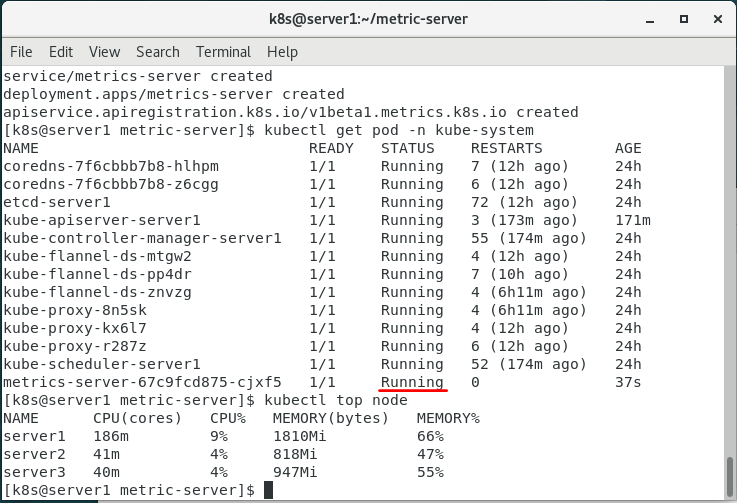
7.查看
kubectl -n kube-system get pod
kubectl top node
首先下载镜像并上传
处理报错
解决报错一:443端口占用
运行文件后报错
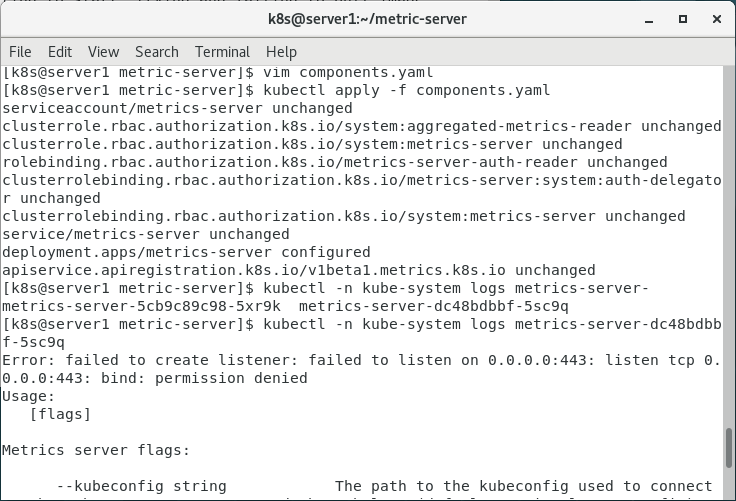
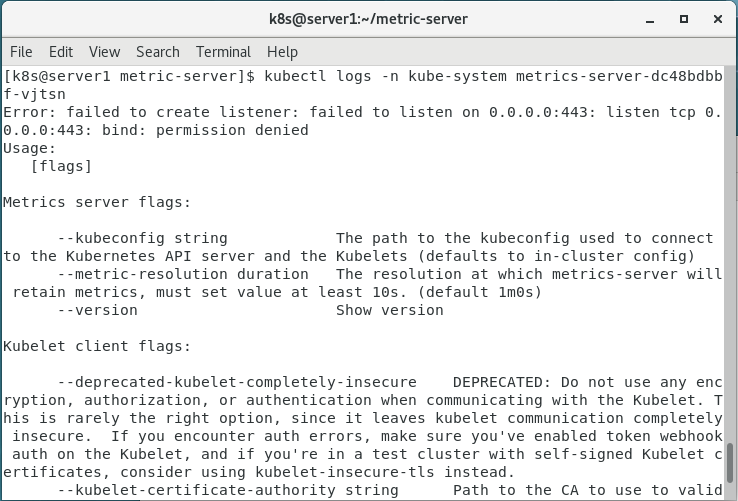
报错的意思是无法绑定443端口
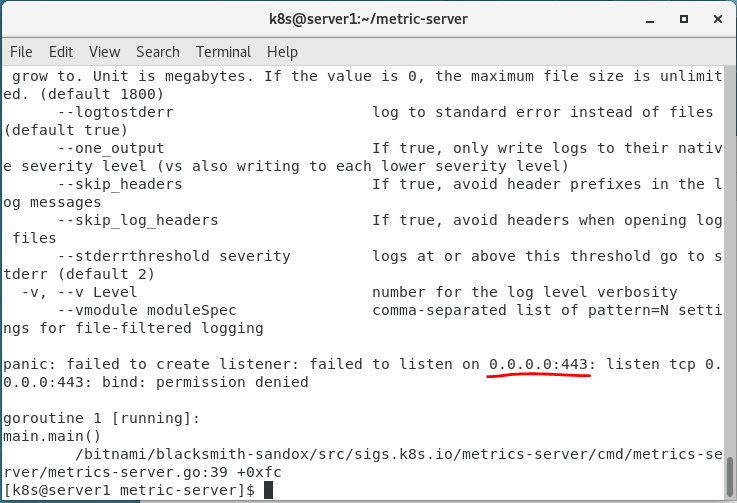
我查看了一下443端口占用情况,发现被进程占用,于是修改components.yaml文件中的相关端口,发现进程运行正常(弄了整整两天,终于成功了????)。参考了这篇文章:Kubernetes集群之Metrics Server资源指标监控
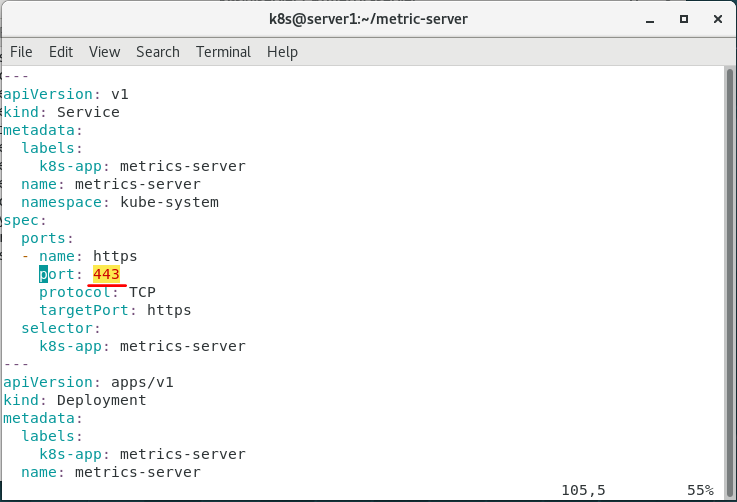
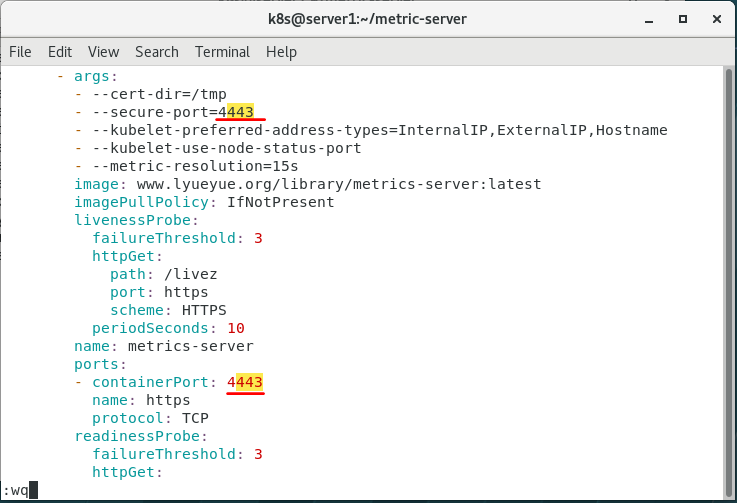
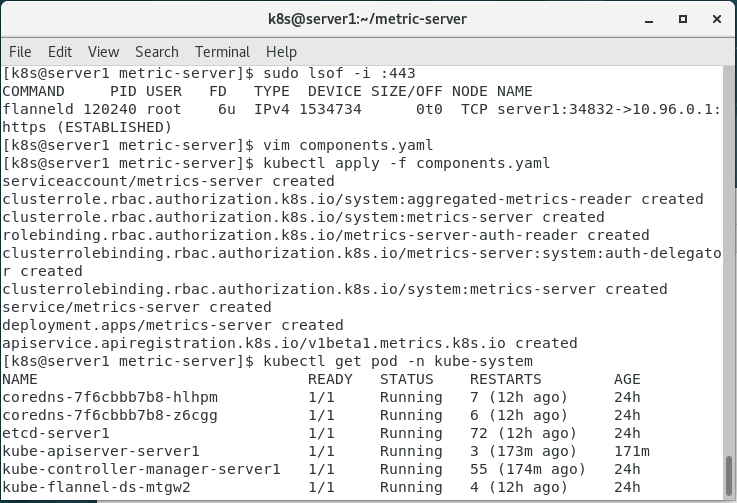
解决报错二:x509证书问题
1.vim /var/lib/kubelet/config.yaml
serverTLSBootstrap: true
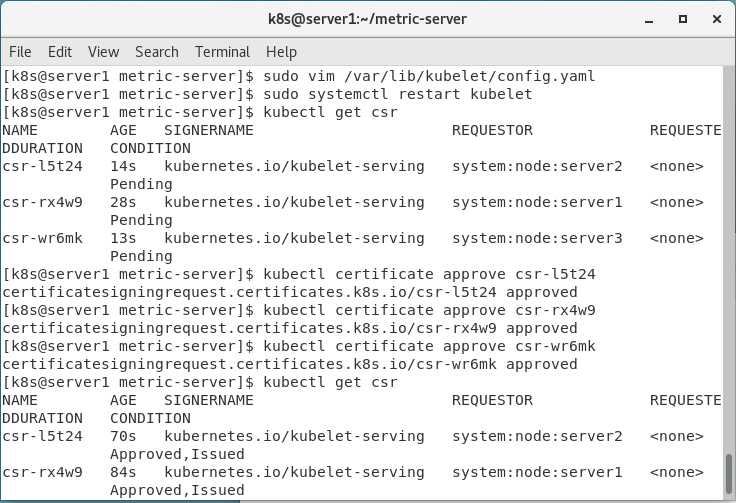
2.systemctl restart kubelet
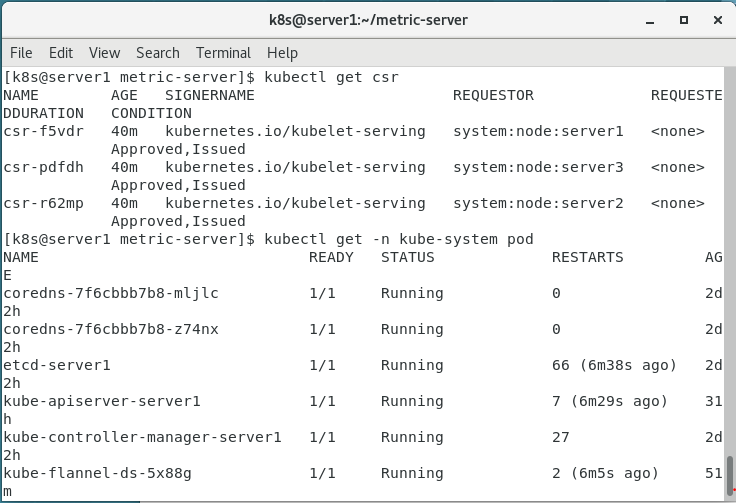
3.kubectl get csr
kubectl certificate approve csr-xxxxx csr-xxxxx csr-xxxxx
4.kubectl get csr
补充:如果发现报x509证书错误
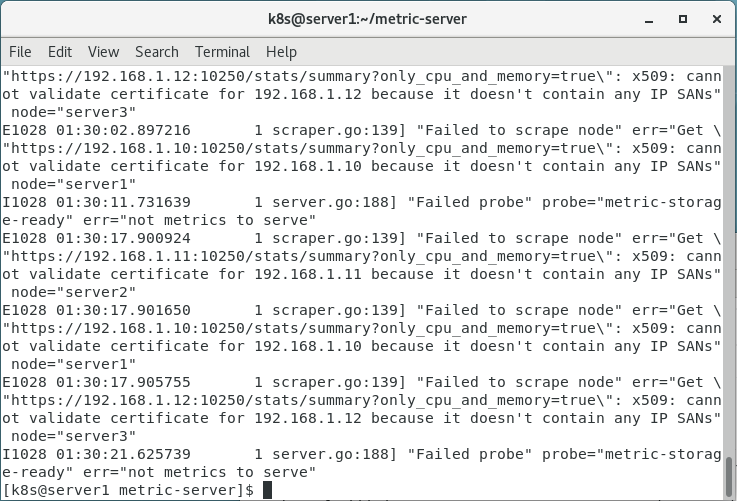
修改 /var/lib/kubelet/config.yaml 文件(注意每个节点都需要进行如下操作)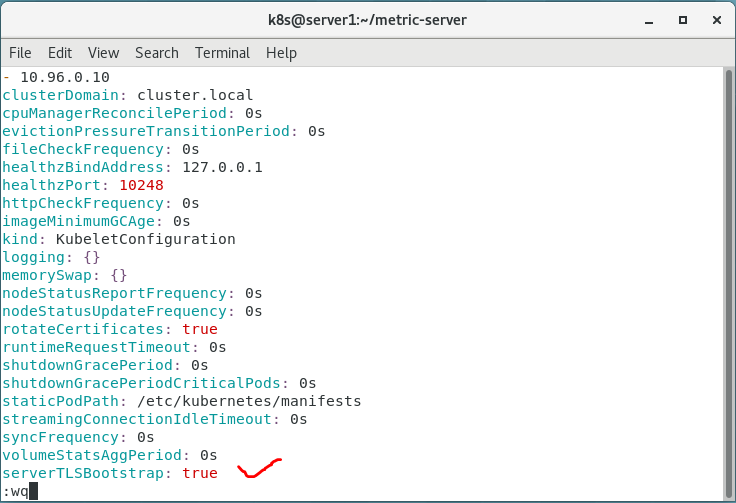
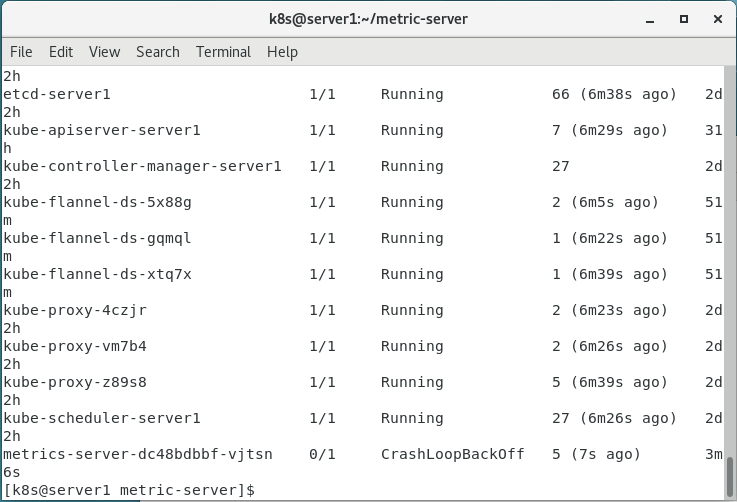
发现metrics-server进程运行成功!还可以使用top node。
dashboard
dashboard简介
Dashboard可以给用户提供一个可视化的 Web 界面来查看当前集群的各种信息。用户可以用 Kubernetes Dashboard 部署容器化的应用、监控应用的状态、执行故障排查任务以及管理 Kubernetes 各种资源。
dashboard部署
dashboard官网
1.建立目录
mkdir dashboard
cd dashboard
2.拉取清单
wget https://raw.githubusercontent.com/kubernetes/dashboard/v2.2.0/aio/deploy/recommended.yaml
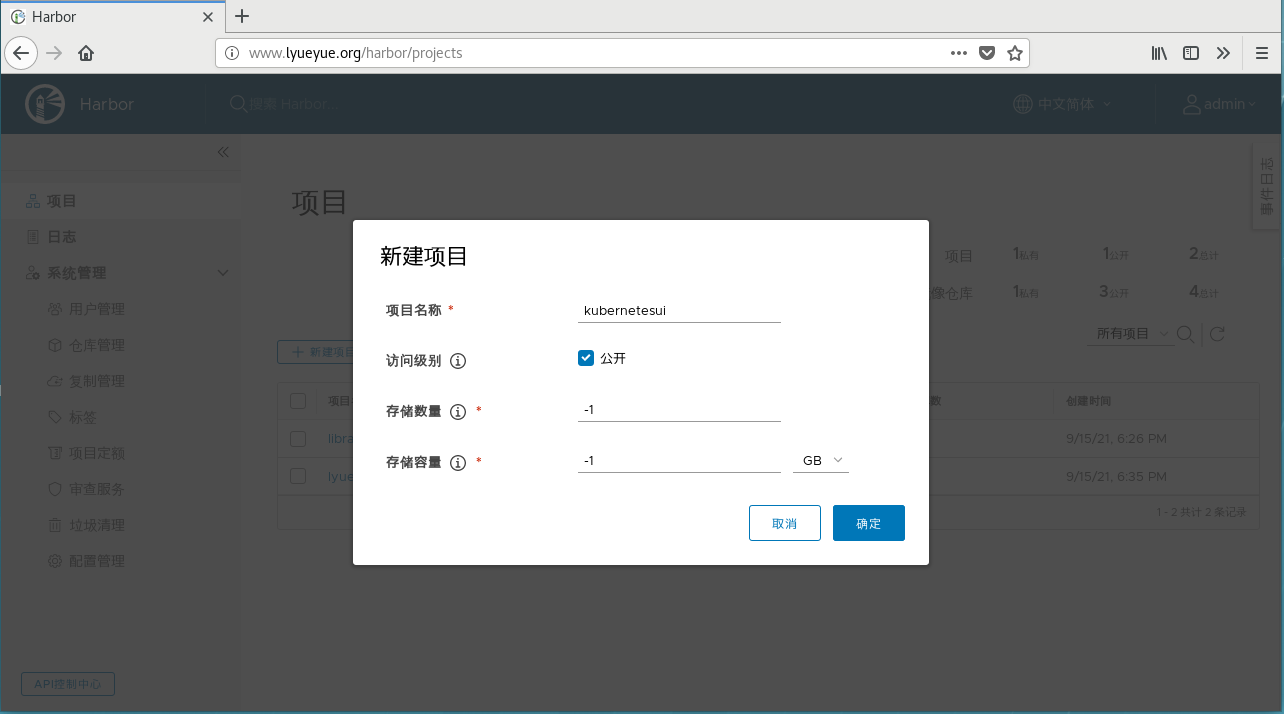
3.在harbor中新建项目
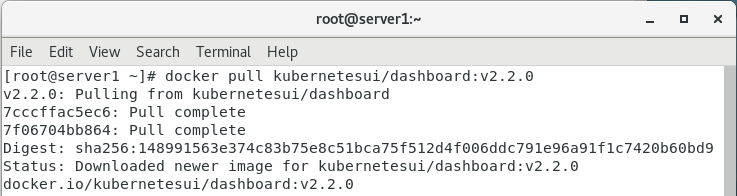
4.拉取相关镜像并上传至仓库
docker pull kubernetesui/dashboard:v2.2.0
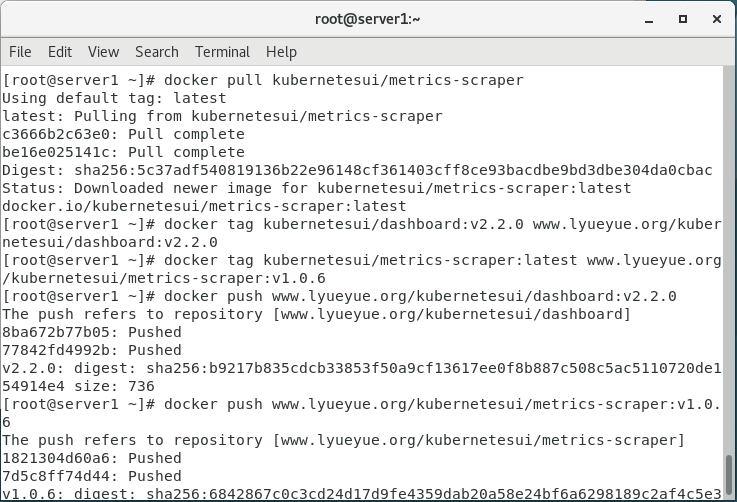
docker pull kubernetesui/metrics-scraper
docker tag kubernetesui/dashboard:v2.2.0 www.lyueyue.org/kubernetesui/dashboard:v2.2.0
docker tag kubernetesui/metrics-scraper:latest www.lyueyue.org/kubernetesui/metrics-scraper:v1.0.6
docker push www.lyueyue.org/kubernetesui/dashboard:v2.2.0
docker push www.lyueyue.org/kubernetesui/metrics-scraper:v1.0.6
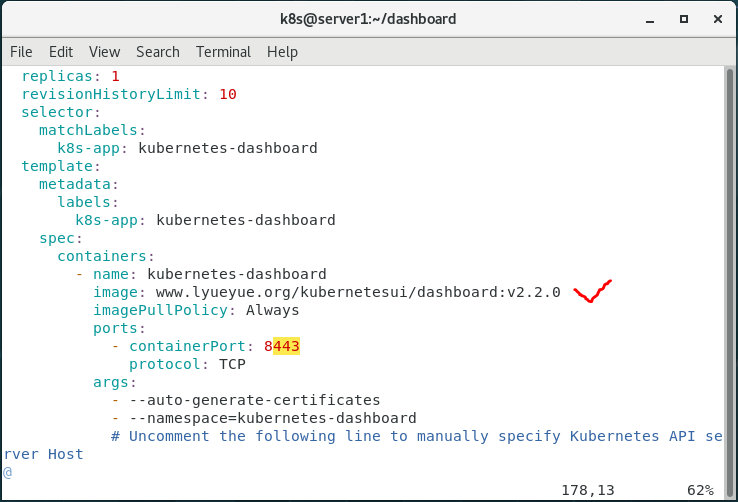
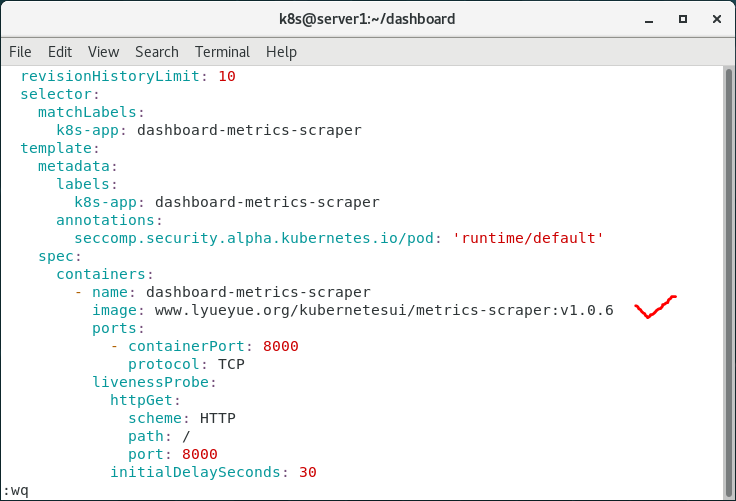
5.修改清单文件
更改镜像地址
6.运行文件
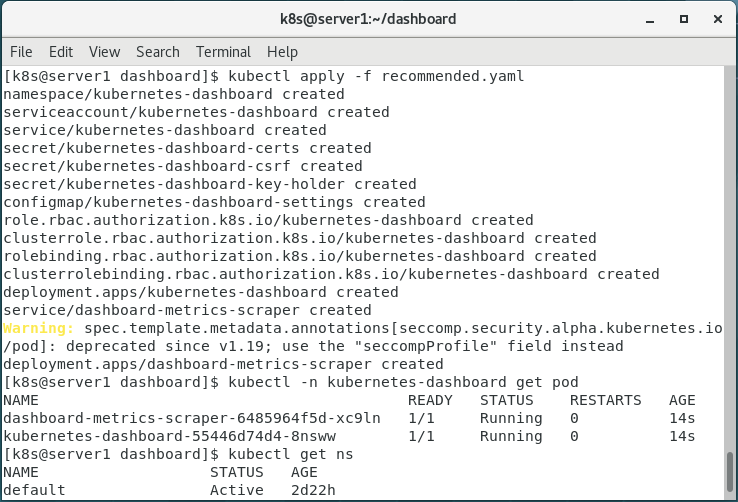
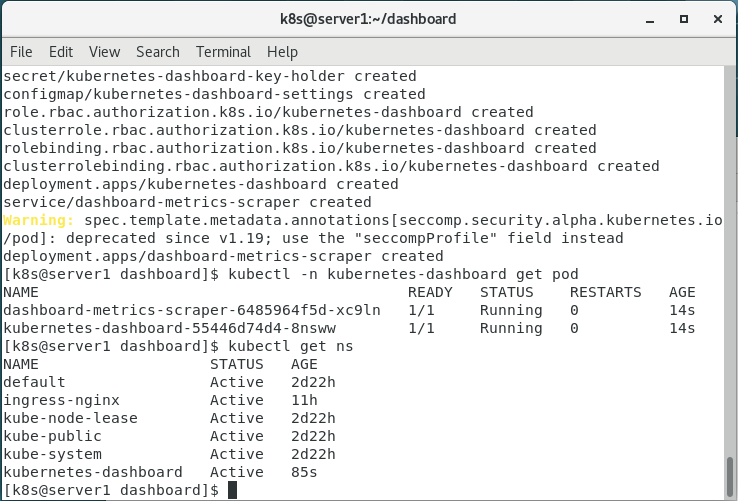
kubectl apply -f recommended.yaml
7.查看
kubectl -n kubernetes-dashboard get pod
kubectl get ns
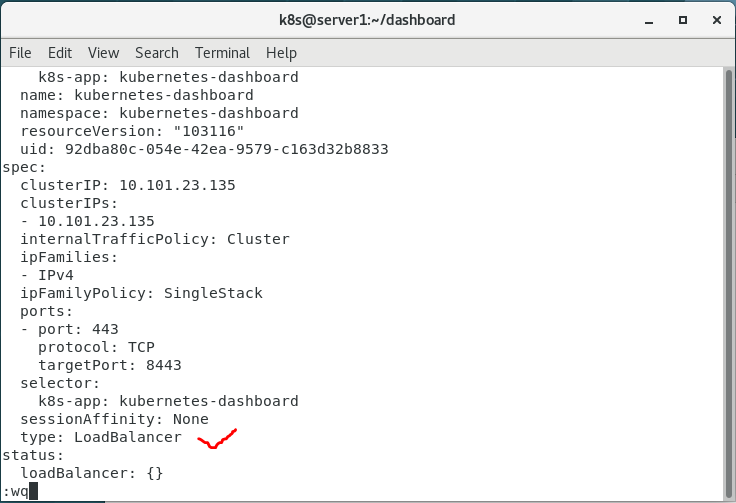
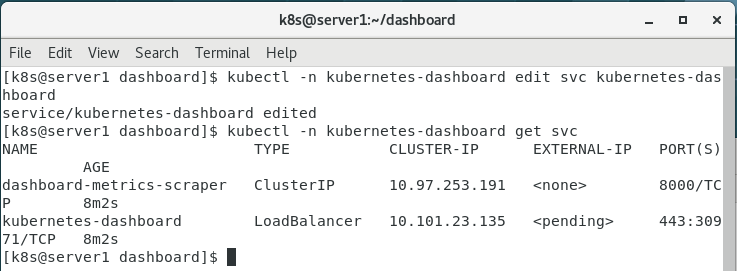
8.修改ClusterIP为LoadBalancer
kubectl -n kubernetes-dashboard edit svc kubernetes-dashboard
kubectl -n kubernetes-dashboard get svc
9.查看密钥token
kubectl -n kubernetes-dashboard describe sa kubernetes-dashboard
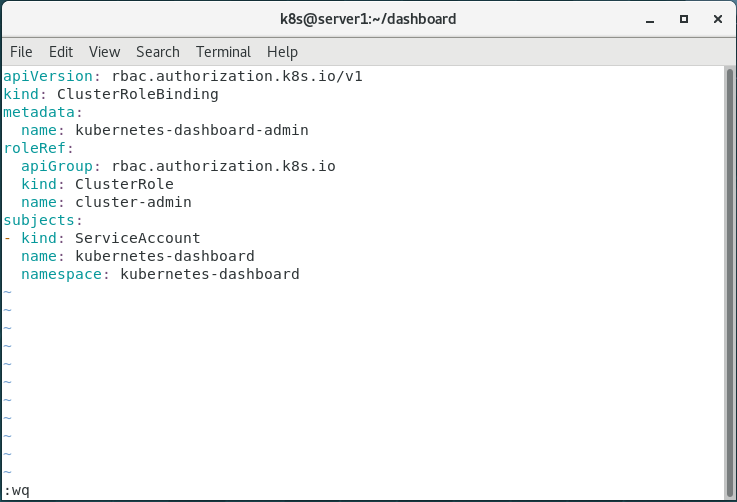
10.解决报错(进行授权)
默认dashboard对集群没有操作权限,需要授权.
vim rbac.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: kubernetes-dashboard-admin
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: kubernetes-dashboard
namespace: kubernetes-dashboard
kubectl apply -f rbac.yaml
11.登录dashboard
12.测试
下载文件的时候有时网络慢,可以多试几次。
在harbor里新建一个项目kubernetesui
拉取镜像
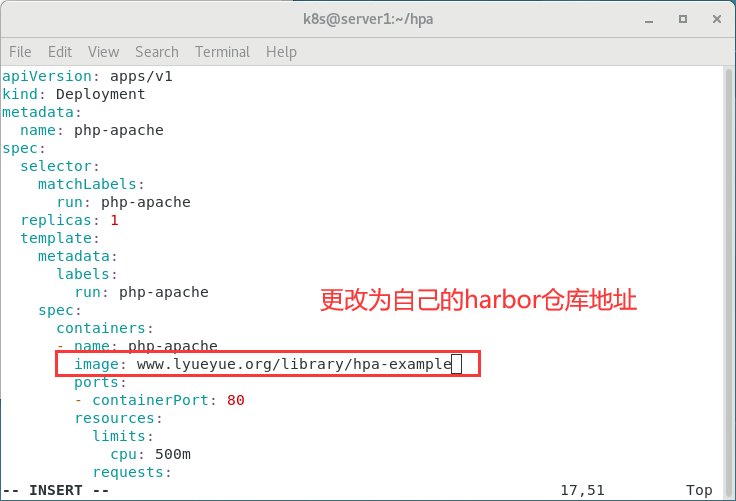
修改recommended.yaml文件
而kubernetes-dashboard是ClusterIP类型,不便于我们通过浏览器访问,因此需要改成NodePort型的。
登录dashboard
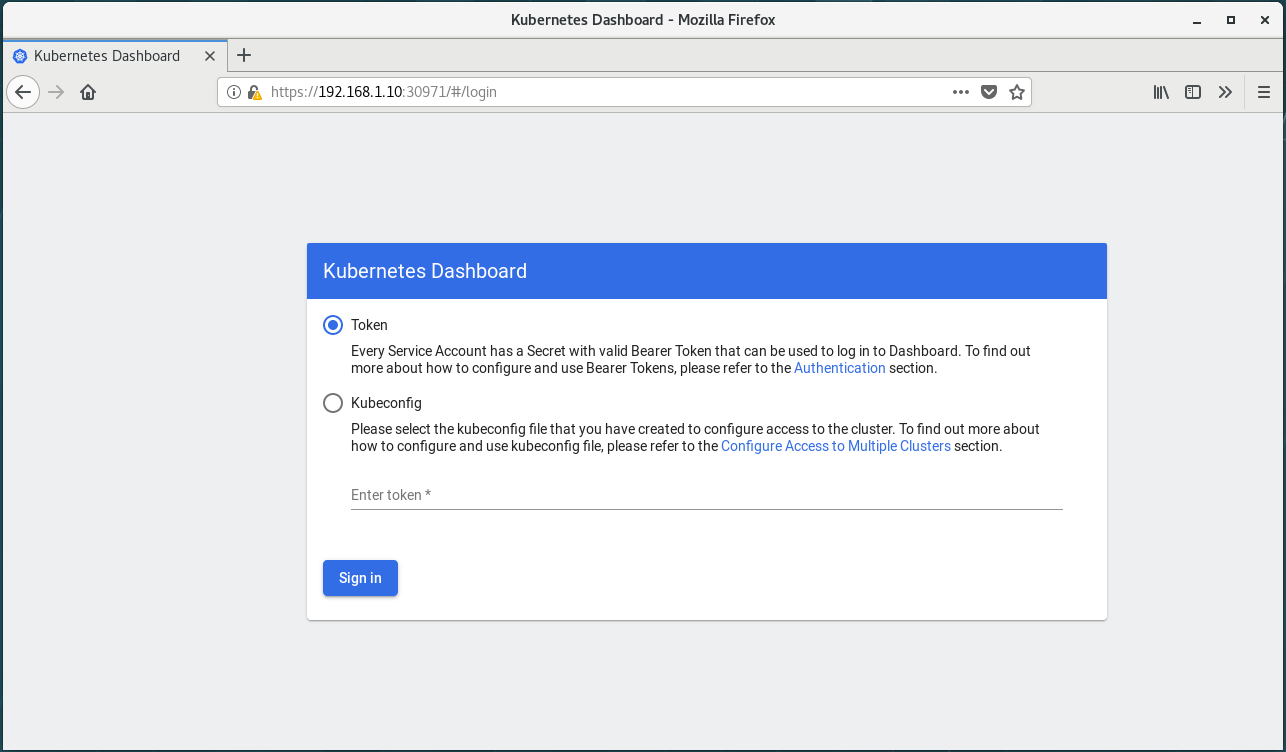
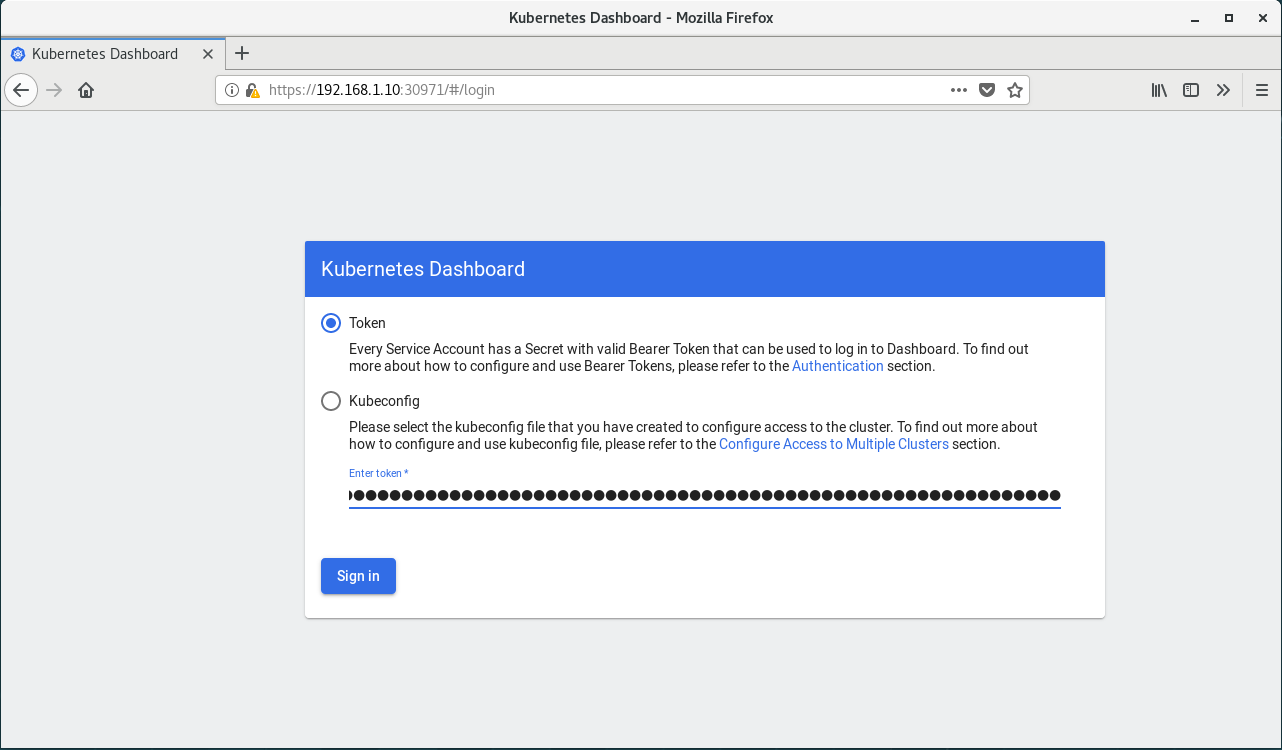
获取登录密钥token
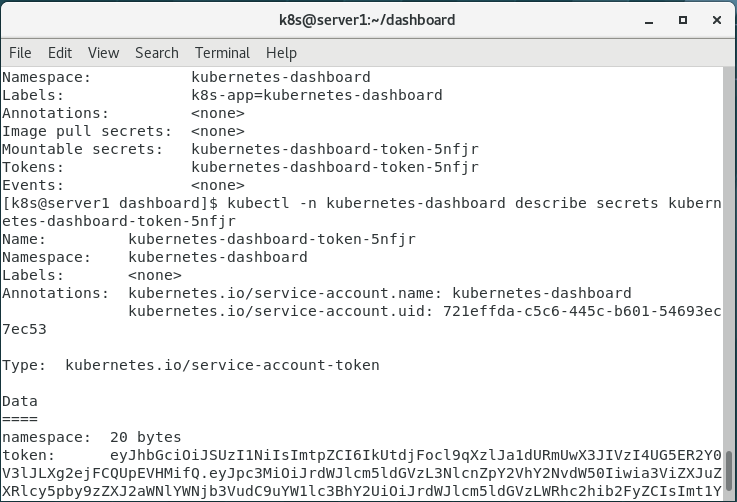
粘贴token
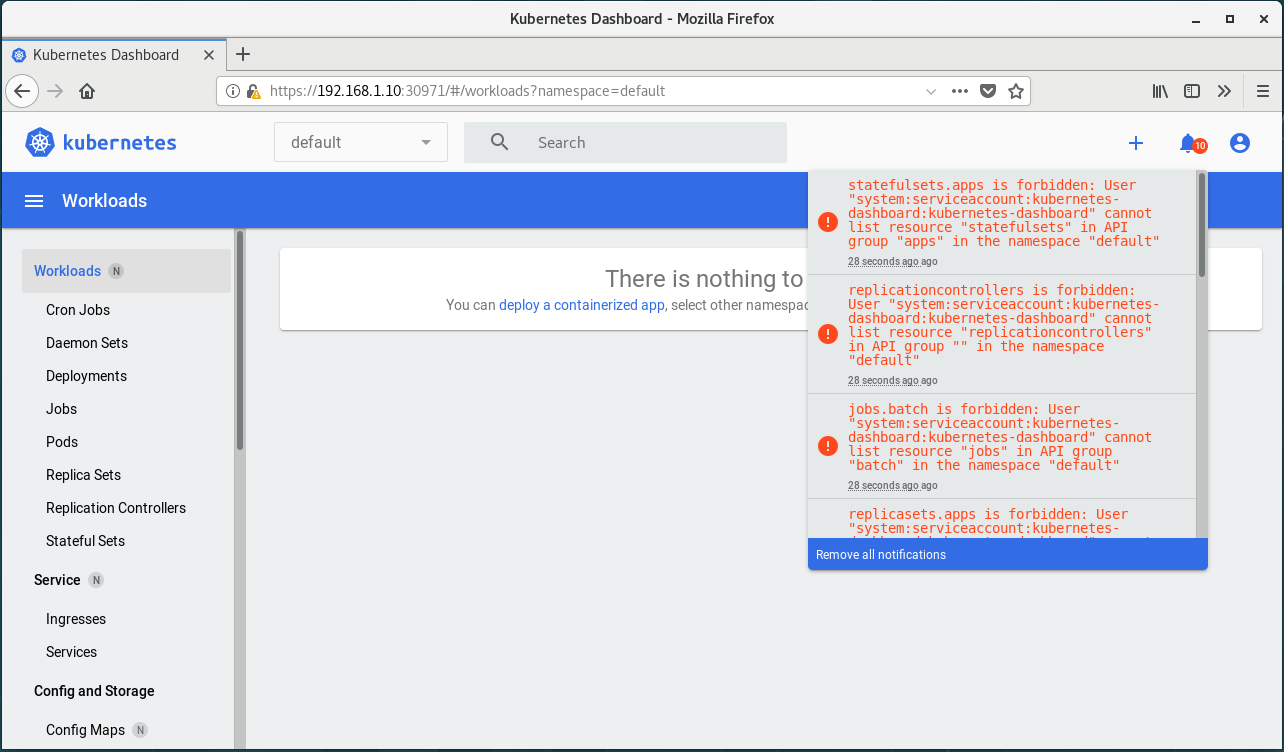
处理报错
报错,原因是没有权限。
接下来开始进行授权
授权后发现报错消失

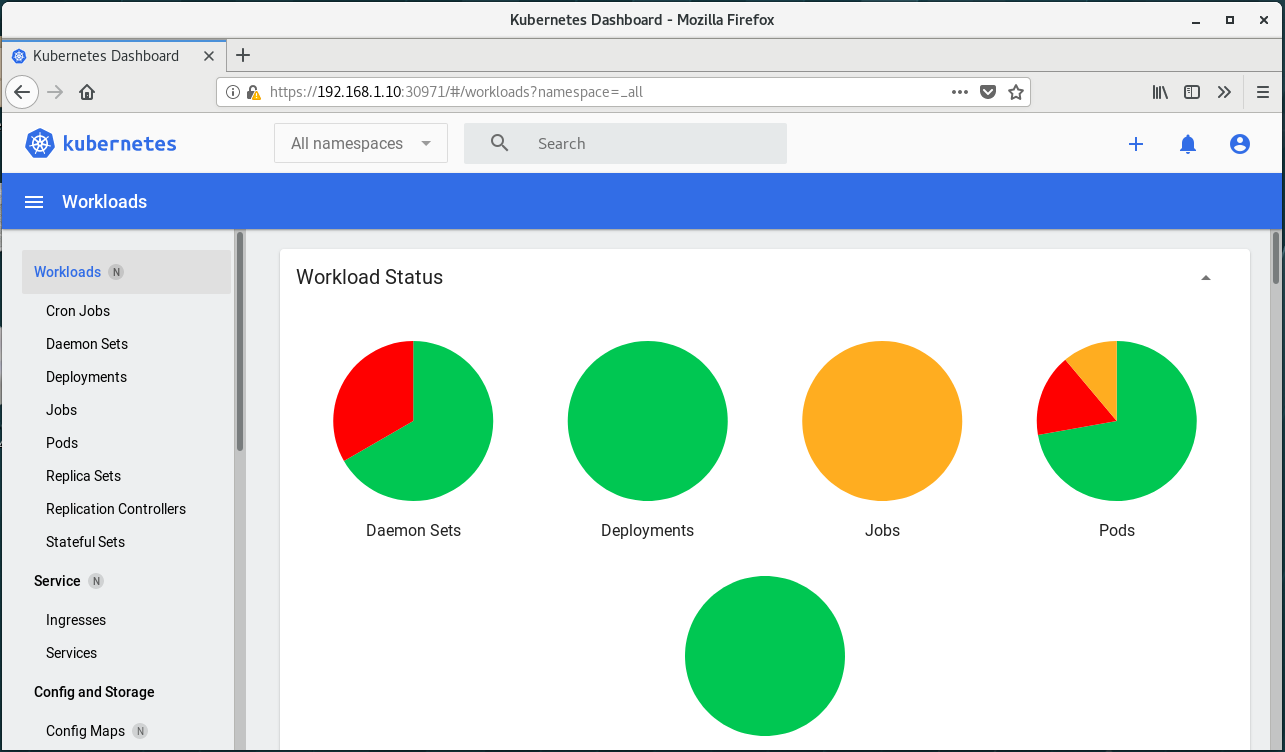
测试
(1)新建一个demo
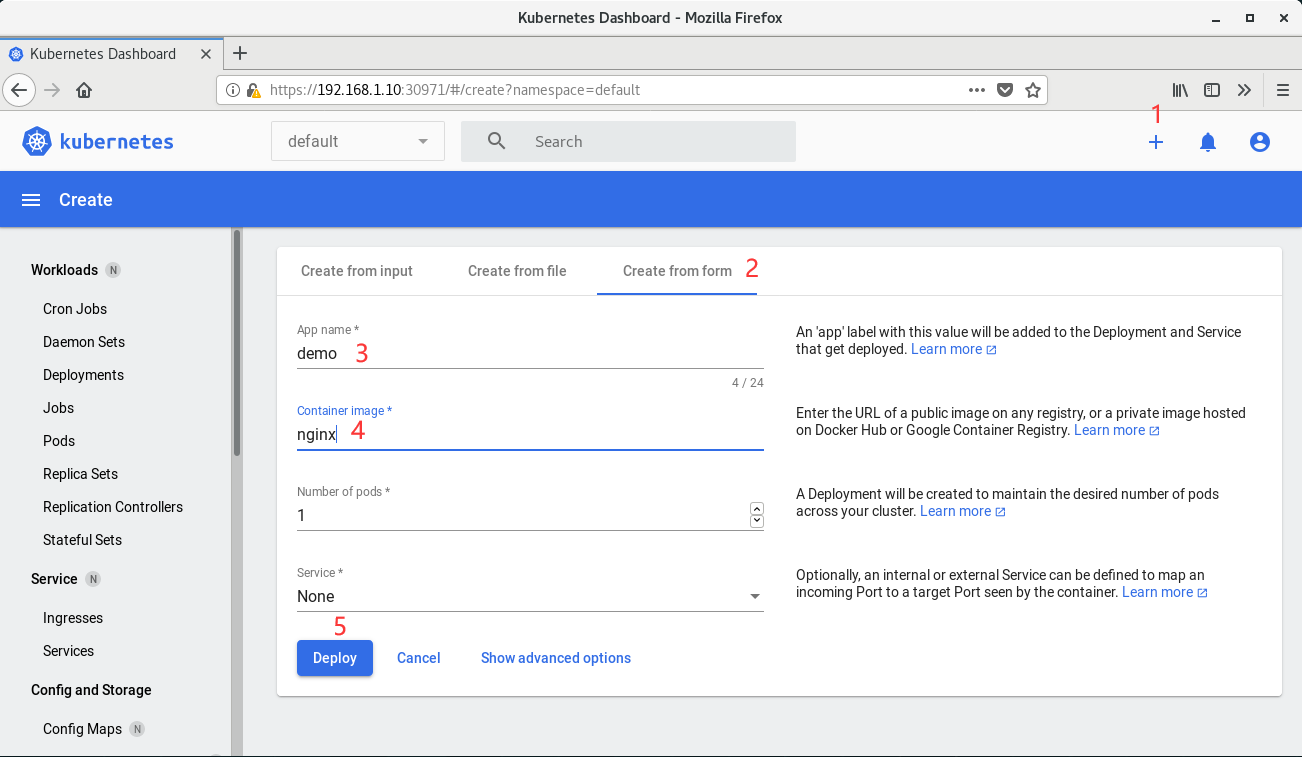
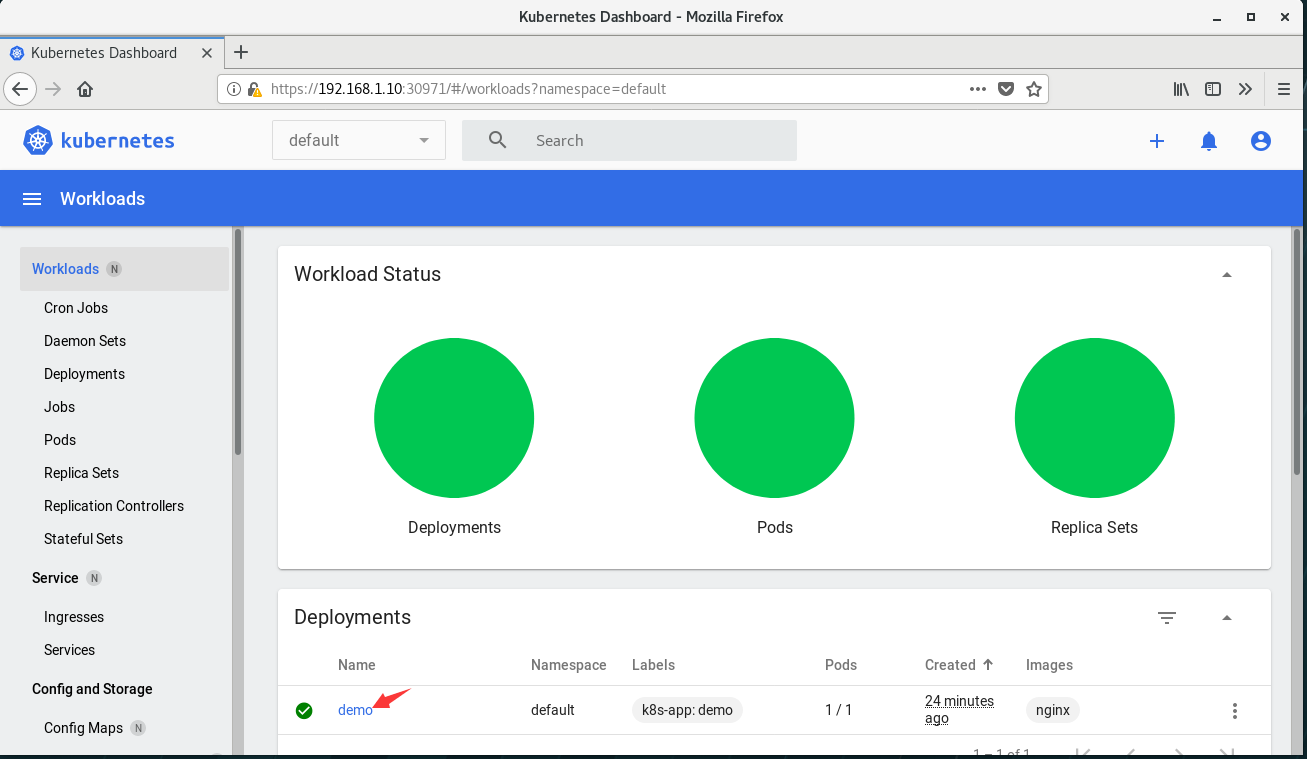

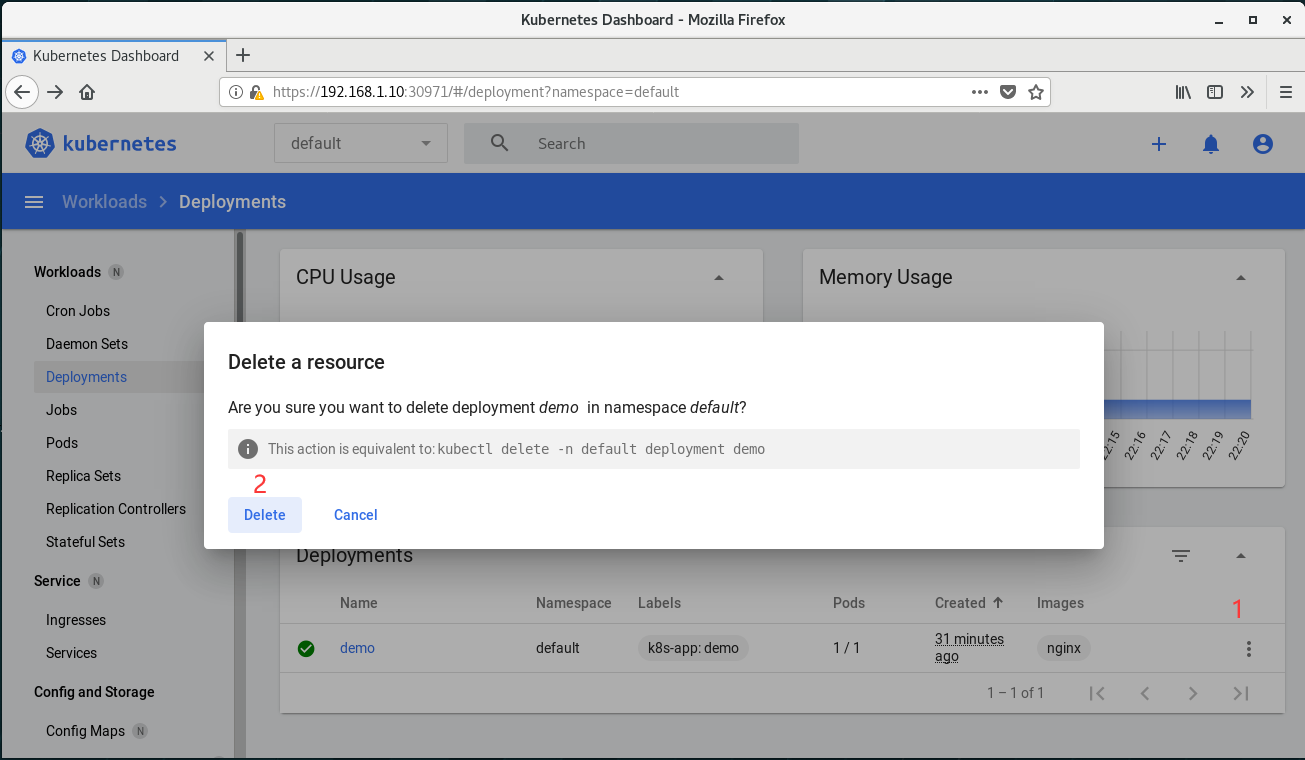
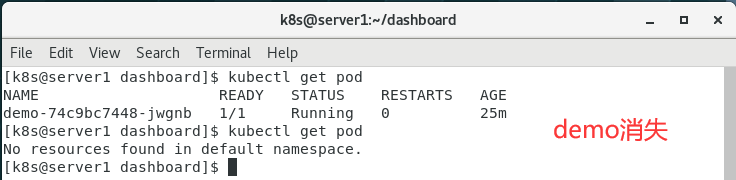
(2)删除demo
HPA(Horizontal Pod Autoscaler)实例
HPA简介
- HPA(Horizontal Pod Autoscaler)Pod自动弹性伸缩,K8S通过对Pod中运行的容器各项指标(CPU占用、内存占用、网络请求量)的检测,实现对Pod实例个数的动态新增和减少。
官方参考链接 - HPA伸缩过程:
(1)收集HPA控制下所有Pod最近的cpu使用情况(CPU utilization)
(2)对比在扩容条件里记录的cpu限额(CPUUtilization)
(3)调整实例数(必须要满足不超过最大/最小实例数)
(4)每隔30s做一次自动扩容的判断
CPU utilization的计算方法是用cpu usage(最近一分钟的平均值,通过metrics可以直接获取到)除以cpu request(这里cpu request就是我们在创建容器时制定的cpu使用核心数)得到一个平均值,这个平均值可以理解为:平均每个Pod CPU核心的使用占比。 - HPA进行伸缩算法:
(1)计算公式:TargetNumOfPods = ceil(sum(CurrentPodsCPUUtilization) / Target)
(2)ceil()表示取大于或等于某数的最近一个整数
(3)每次扩容后冷却3分钟才能再次进行扩容,而缩容则要等5分钟后。
(4)当前Pod Cpu使用率与目标使用率接近时,不会触发扩容或缩容。
触发条件:avg(CurrentPodsConsumption) / Target >1.1 或 <0.9
单度量指标CPU
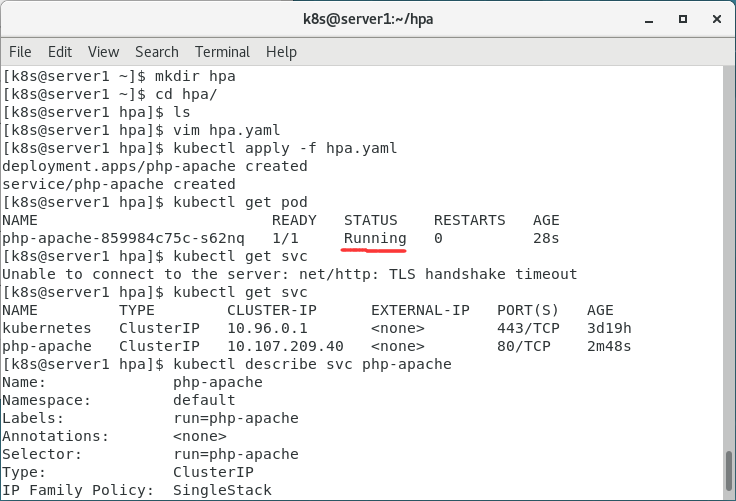
1.建立目录
mkdir hpa
cd hpa
2.拉取镜像
docker pull shenshouer/hpa-example
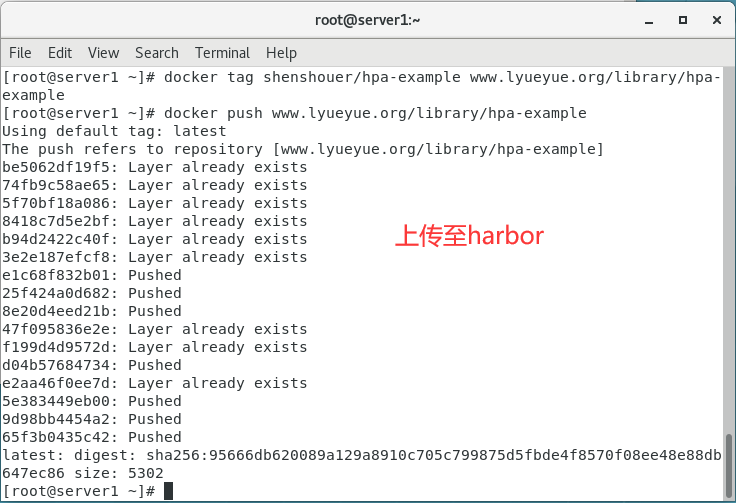
docker tag shenshouer/hpa-example www.lyueyue.org/library/hpa-example
docker push www.lyueyue.org/library/hpa-example
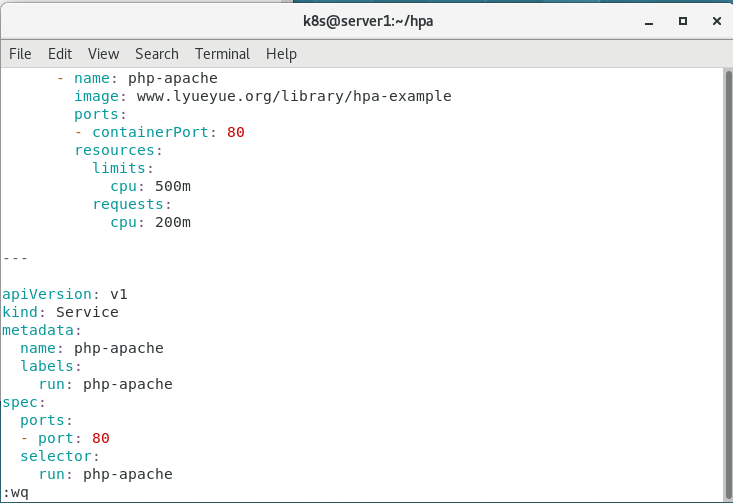
3.编写文件
apiVersion: apps/v1
kind: Deployment
metadata:
name: php-apache
spec:
selector:
matchLabels:
run: php-apache
replicas: 1
template:
metadata:
labels:
run: php-apache
spec:
containers:
- name: php-apache
image: www.lyueyue.org/library/hpa-example
ports:
- containerPort: 80
resources:
limits:
cpu: 500m
requests:
cpu: 200m
---
apiVersion: v1
kind: Service
metadata:
name: php-apache
labels:
run: php-apache
spec:
ports:
- port: 80
selector:
run: php-apache
4.运行文件
kubectl apply -f hpa.yaml
5.查看
kubectl get pod
kubectl get svc
kubectl describe svc php-apache
6.扩容
kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=10
7.做压测
kubectl get hpa
kubectl run -i --tty load-generator --rm --image=busybox --restart=Never -- /bin/sh -c "while sleep 0.01; do wget -q -O- http://php-apache; done"
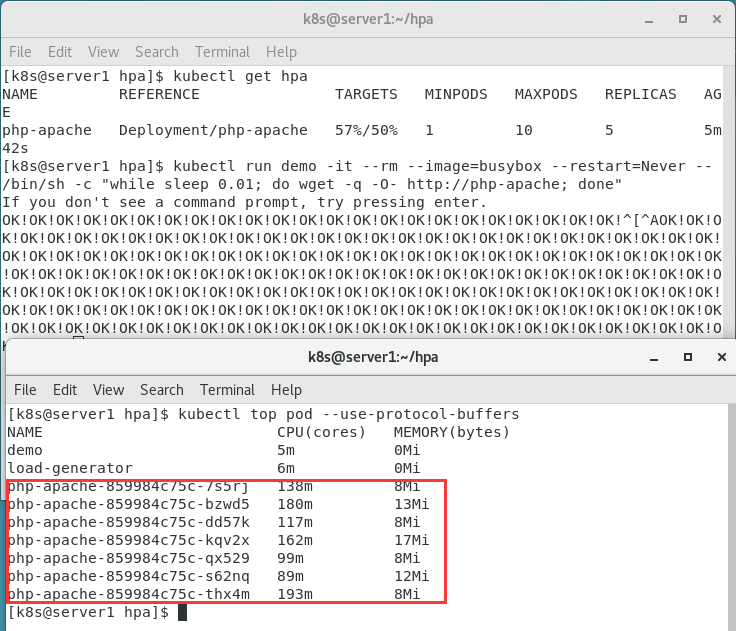
8.查看
kubectl top pod --use-protocal-buffers
kubectl get pod
解决虚拟机报错
首先下载一个镜像hpa-example
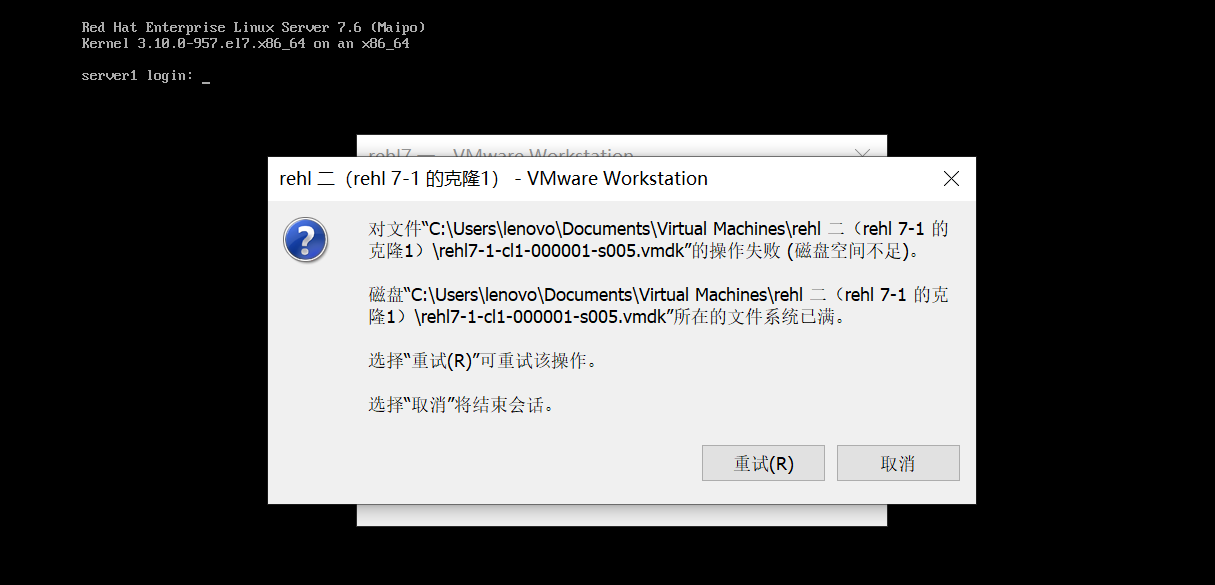
在做实验的过程中虚拟机报如下错误,提示目录内存不够。
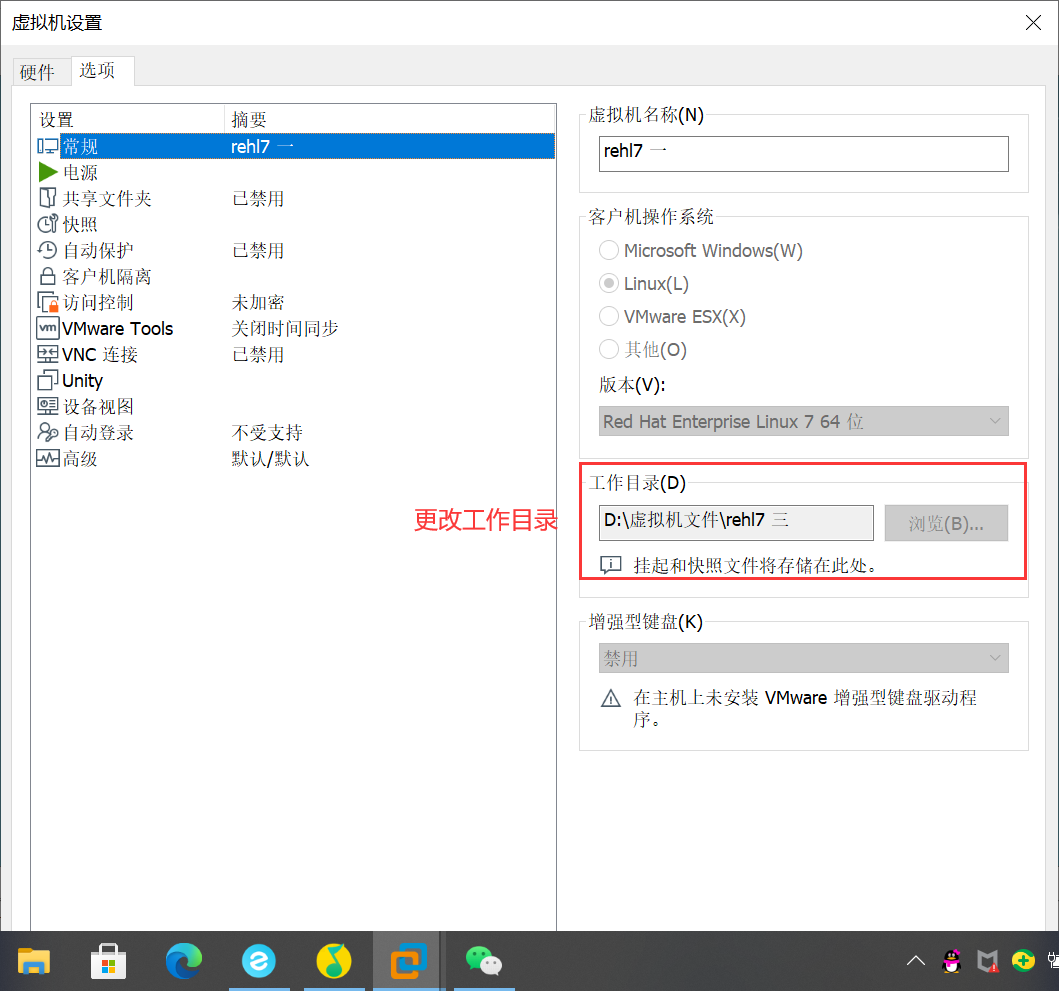
解决办法是将虚拟机所在目录放到别的磁盘内存充足的地方或者删除一些不用的虚拟机并将其所在的虚拟机目录删除
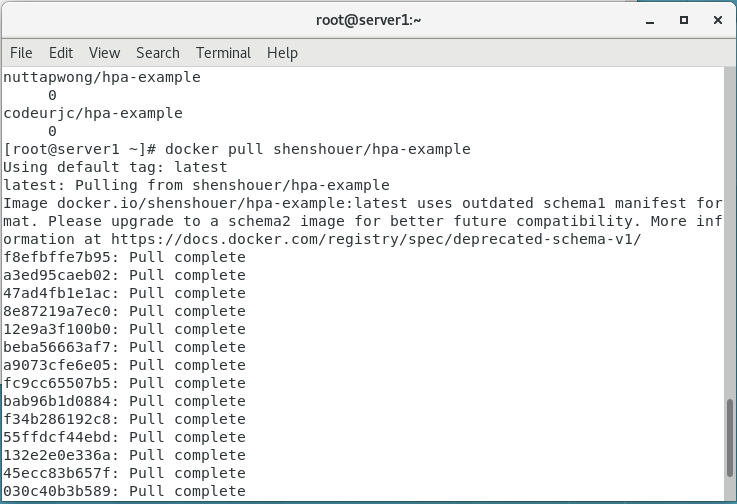
发现虚拟机运行正常了
开始部署
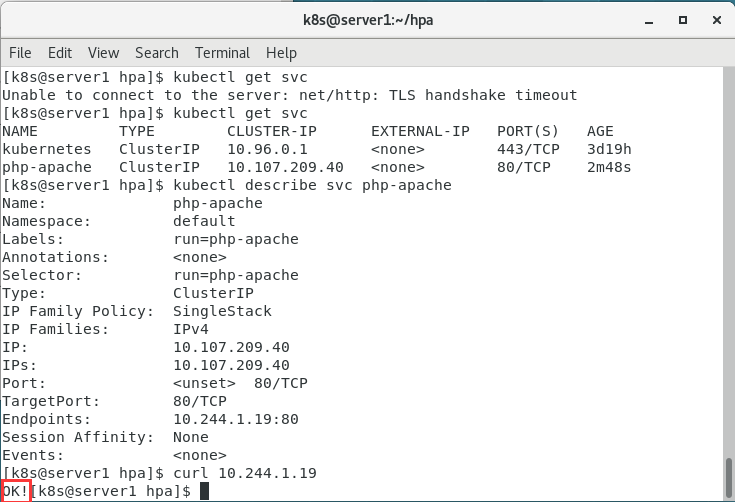
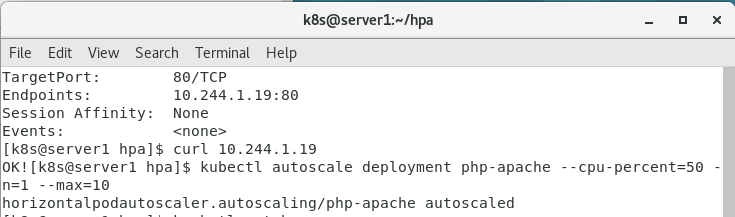
做压测,发现扩容成功。
解决报错二
我们发现有pending的情况
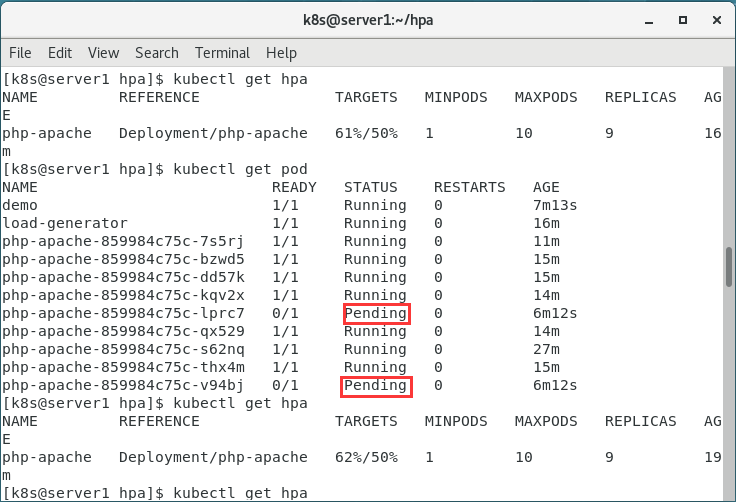
查看此pod的日志,去除污点,将 master 标记为可调度。
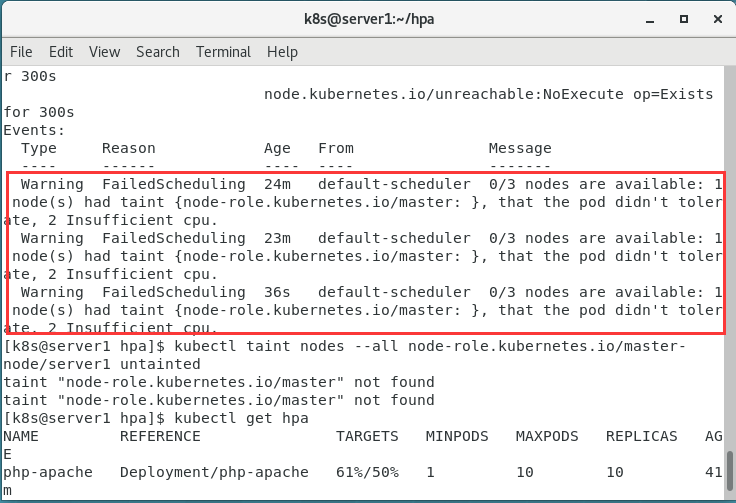
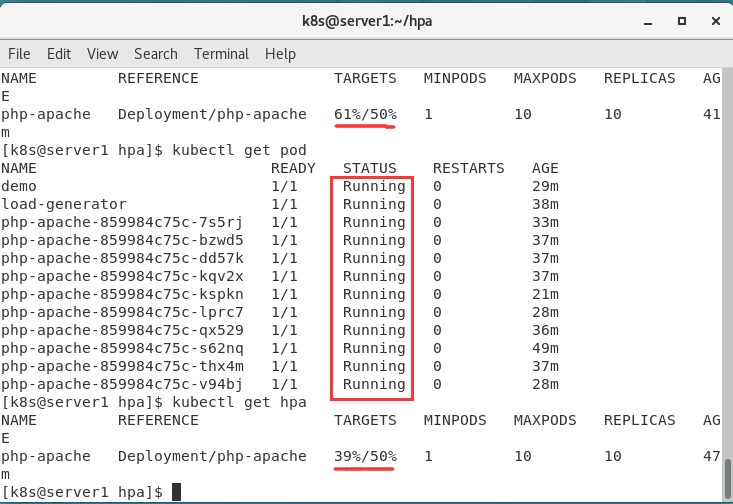
发现pod都正常了,且百分比降到50以下了。
多项度量指标CPU+memory
1.清理环境
kubectl delete -f hpa.yaml
2.编写文件
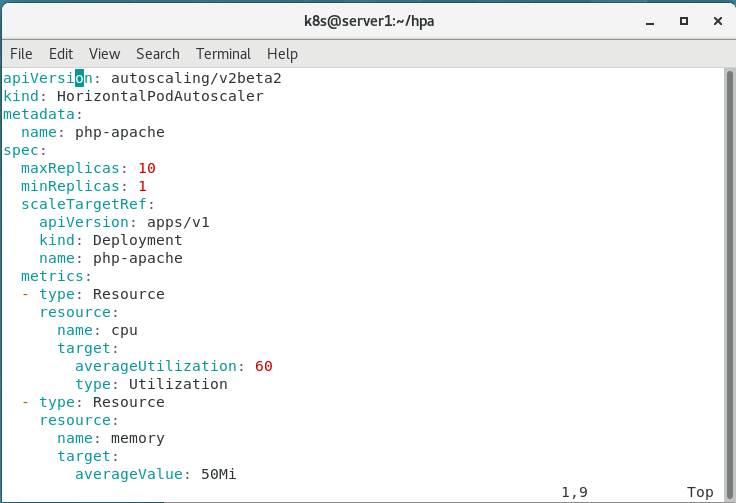
vim hpa-v2.yaml
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
spec:
maxReplicas: 10
minReplicas: 1
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
metrics:
- type: Resource
resource:
name: cpu
target:
averageUtilization: 60
type: Utilization
- type: Resource
resource:
name: memory
target:
averageValue: 50Mi
type: AverageValue
3.运行文件
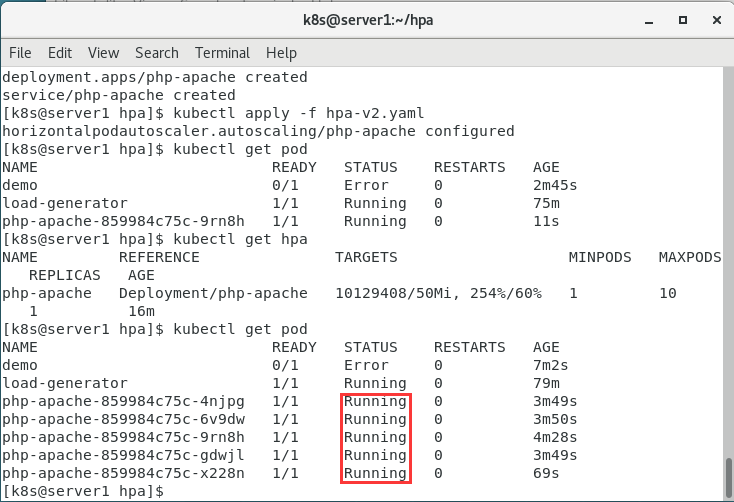
kubectl apply -f hpa-v2.yaml
4.查看
kubectl get hpa
kubectl get pod
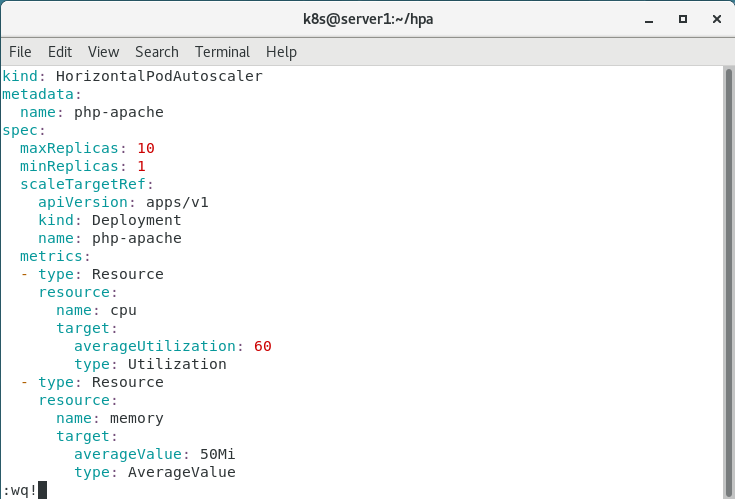
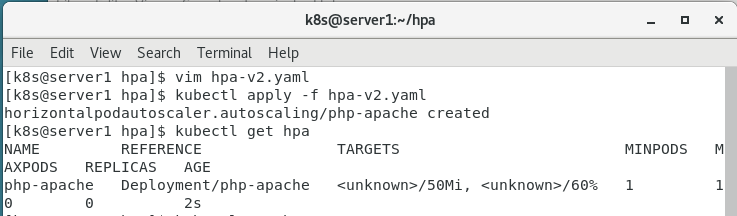
扩容成功!
这一篇终于写完了,写了很久,继续努力!
最后
以上就是风趣大山最近收集整理的关于k8s 十四之kubernetes资源监控 + 虚拟机报错的解决 + HPAMetrics-ServerdashboardHPA(Horizontal Pod Autoscaler)实例的全部内容,更多相关k8s内容请搜索靠谱客的其他文章。

![[问题已处理]-k8s访问svc的clusterip异常的慢](https://www.shuijiaxian.com/files_image/reation/bcimg26.png)






发表评论 取消回复