本文是通过一台物理机,搭建了集群是由3个协调节点,服务端口号分别为11810,11820,11830,3个编目节点,服务端口号分别为11800,11840,11850,以及3个数据节点,服务端口号分别为11860,11870,11880。(偶只有一台机,不弄虚拟机,就想搭个集群玩玩)。
首先在Sequoiadb官网上下载Sequoiadb数据库,http://www.sequoiadb.com/index.php?p=downserver
我这里下载的是1.6版本运行在x86_64平台的数据库。
下载之后,解压sequoiadb-1.6-linux_x86_64-installer.run.tar.gz
tar –xzvf sequoiadb-1.6-linux_x86_64-installer.run.tar.gz
解压完有个sequoiadb-1.6-linux_x86_64-installer.run文件。运行该文件安装sequoiadb。
./ sequoiadb-1.6-linux_x86_64-installer.run
然后按照提示一步一步操作即可。该数据库默认安装在/opt/sequoiadb目录中,创建默认用户sdbadmin。接下来进行单机集群模式的配置与启动
步骤一:检查Sequoiadb的配置服务状态
service sdbcm status
确认系统提示“ sdbcm is running ”表示服务正在运行,否则请执行如下命令重新配置服务程序:servicesdbcm start
步骤二:启动协调节点
1.切换到sdbadmin用户
su sdbadmin
2.创建协调节点配置目录
mkdir -p /opt/sequoiadb/conf/local/11810
mkdir -p /opt/sequoiadb/conf/local/11820
mkdir -p /opt/sequoiadb/conf/local/11830
其中11810,11820,11830为协调节点的服务端口,可根据进行需要配置。由于每个协调节点会有相关svcname,replname,sharename,catalogname,httpname信息,这些信息的默认端口就在协调端口号附近,所以这里采用11810,11820,11830这三个端口号。
3.拷贝协调节点样例配置文件
cp /opt/sequoiadb/conf/samples/sdb.conf.coord /opt/sequoiadb/conf/local/11810/sdb.conf
cp /opt/sequoiadb/conf/samples/sdb.conf.coord /opt/sequoiadb/conf/local/11820/sdb.conf
cp /opt/sequoiadb/conf/samples/sdb.conf.coord /opt/sequoiadb/conf/local/11830/sdb.conf
4.修改配置文件
vi /opt/sequoiadb/conf/local/11810/sdb.conf
修改内容
# database path
dbpath=/opt/sequoiadb/database/coord
vi /opt/sequoiadb/conf/local/11820/sdb.conf
修改内容
# database path
dbpath=/opt/sequoiadb/database/coord1
svcname=11820
replname=11821
shardname=11822
catalogname=11823
httpname=11824
vi /opt/sequoiadb/conf/local/11830/sdb.conf
修改内容
# database path
dbpath=/opt/sequoiadb/database/coord2
svcname=11830
replname=11831
shardname=11832
catalogname=11833
httpname=11834
dbpath为数据库放置路径,可根据需要修改,请确保路径已经存在(不存在请手工创建),而svcname,replname,shardname,catalogname,httpname都是与协同节点相关的配置信息。
5.按:wq,保存退出vi
6.创建数据文件存放路径
mkdir -p /opt/sequoiadb/database/coord
mkdir -p /opt/sequoiadb/database/coord1
mkdir -p /opt/sequoiadb/database/coord2
路径为上一步骤配置的路径
7.启动协调节点进程
/opt/sequoiadb/bin/sdbstart -c/opt/sequoiadb/conf/local/11810/
/opt/sequoiadb/bin/sdbstart -c/opt/sequoiadb/conf/local/11820/
/opt/sequoiadb/bin/sdbstart -c/opt/sequoiadb/conf/local/11830/
步骤三:通过命令配置和启动编目节点
1.启动SequoiaDB Shell控制台
/opt/sequoiadb/bin/sdb
2.连接到协调节点
在shell 命令中输入:
>var db = new Sdb("localhost",11810)
其中11810为协调节点端口号
3.创建一个编目节点组
>db.createCataRG("anyuser5", 11800,"/opt/sequoiadb/database/cata/11800")
其中
anyuser5:第一个服务器主机名;
11800:为编目节点服务端口(该端口配置不要与随机端口冲突,以下其它端口的配置也需要注意);
/opt/sequoiadb/database/cata/11800:为编目节点的数据文件存放路径;
Note: 请确保存放路径的权限,如果SequoiaDB采用的默认安装,那么给路径赋予sdbadmin权限,下同。
4.开始添加另外两个编目节点
>var cataRG =db.getRG("SYSCatalogGroup");
>var node1 = cataRG.createNode("anyuser5",11840,"/opt/sequoiadb/database/cata/11840")
>var node2 = cataRG.createNode("anyuser5",11850,"/opt/sequoiadb/database/cata/11850")
5.启动编目节点组
>node1.start()
>node2.start()
步骤四:通过命令配置和启动数据节点
1.创建数据节点组
>var dataRG = db.createRG("datagroup")
2.添加数据节点
>dataRG.createNode("anyuser5", 11860,"/opt/sequoiadb/database/data/11860")
>dataRG.createNode("anyuser5", 11870,"/opt/sequoiadb/database/data/11870")
>dataRG.createNode("anyuser5", 11880,"/opt/sequoiadb/database/data/11880")
Note:
创建节点的第一个参数必须为“主机名”,而不能是主机的IP。
3.启动数据节点组
>dataRG.start()
4.退出SequoiaDB shell控制台
>quit
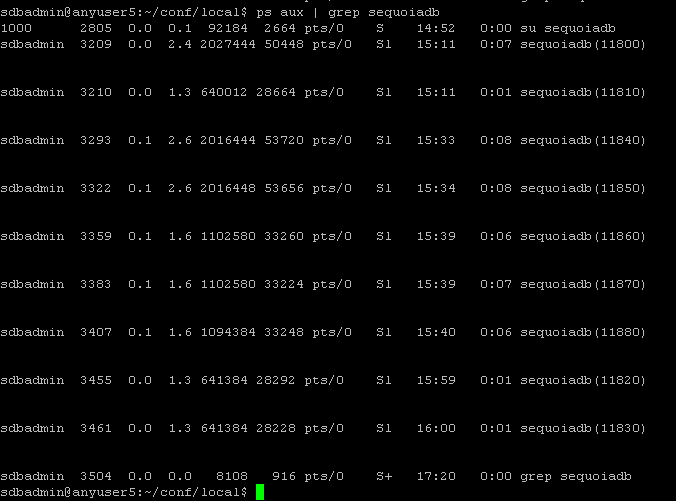
最后
以上就是飘逸老鼠最近收集整理的关于单台物理机搭建Sequoiadb集群的全部内容,更多相关单台物理机搭建Sequoiadb集群内容请搜索靠谱客的其他文章。








发表评论 取消回复