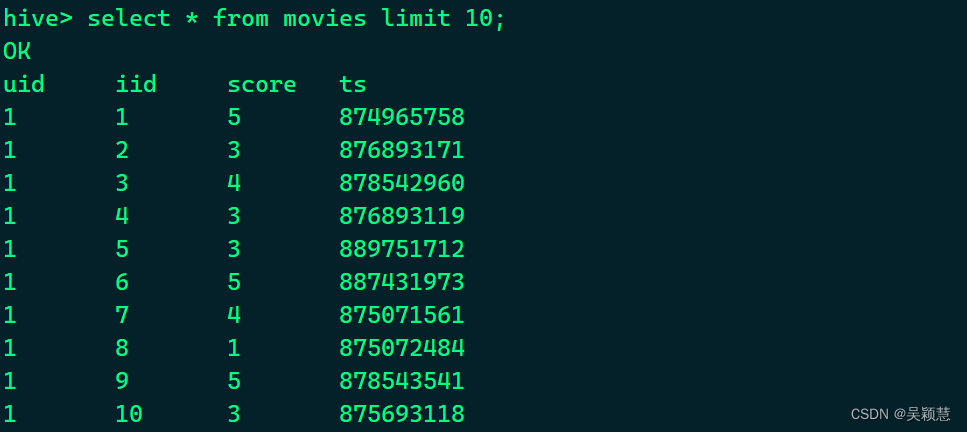
表movies
原表movies文件——uid用户ID,iid电影ID,score评分,ts时间戳
select uid, iid, score, ts, row_number() over(partition by uid order by ts desc) as rk from movies;
1、row_number()
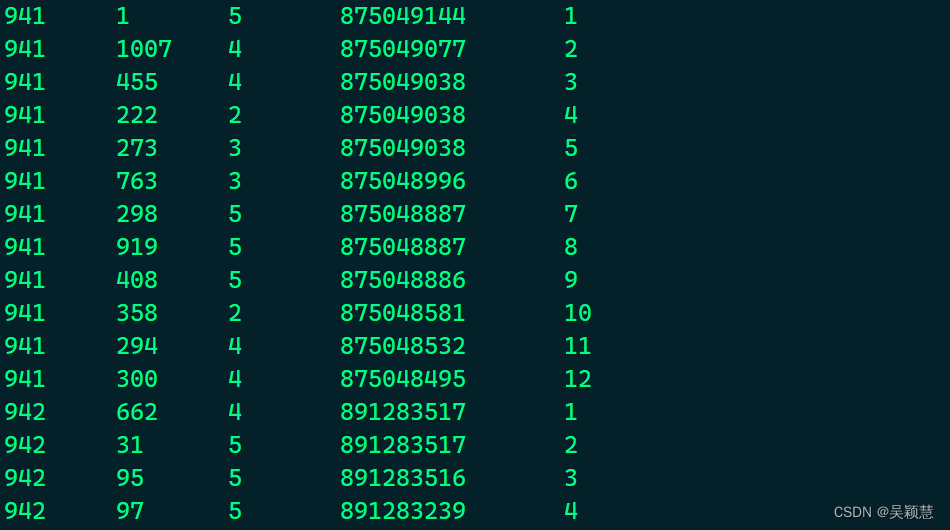
得到的结果以uid为分区,以 ts时间戳为降序排列,row_number()形成一列新的排名序列号,取名rk,以uid分区进行排名。
row_number()生成连续的序号(相同的元素序号不同)。
2、rank()
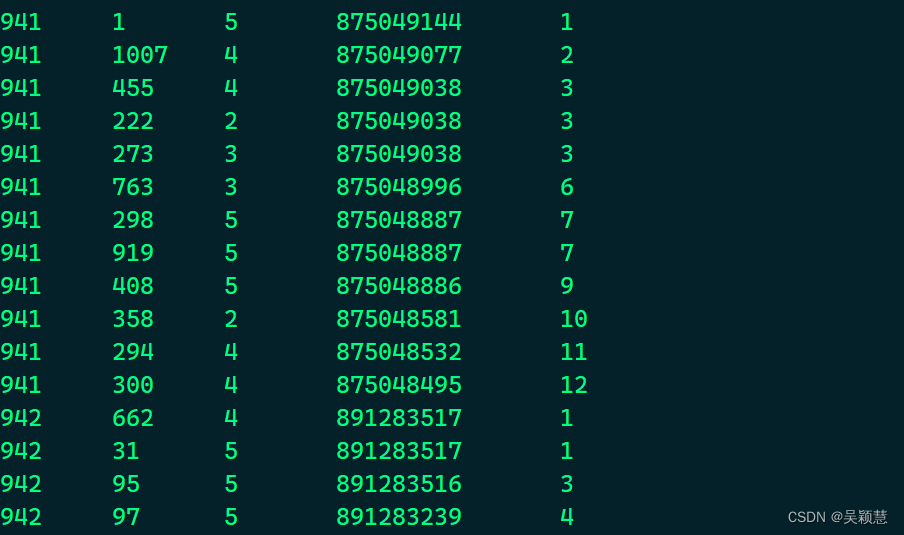
select uid, iid, score, ts, rank() over(partition by uid order by ts desc) as rk from movies;
此处是排序,排序的列里面有相同的值,他的排名会相同。
rank() 如果两个元素相同,则序号相同,并且跳过下一个序号。
3、dense_rank()
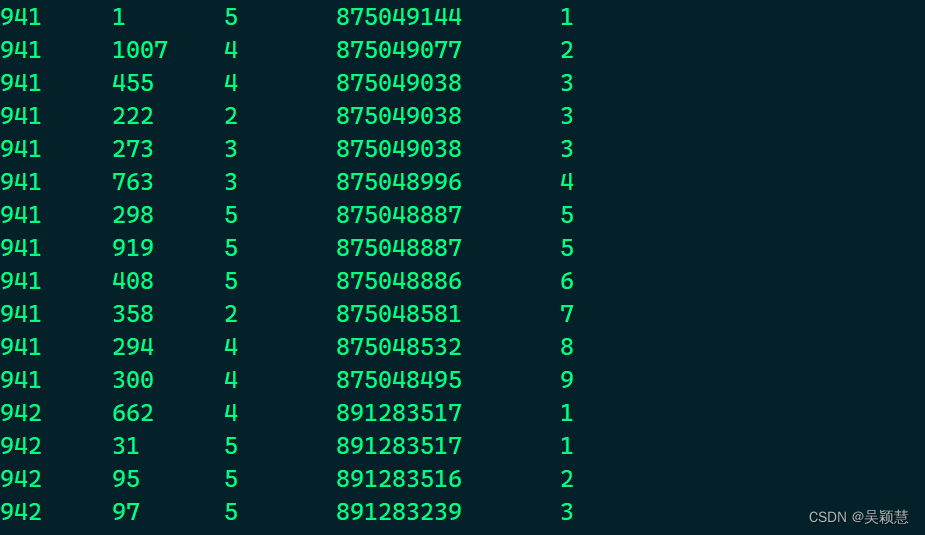
select uid, iid, score, ts, dense_rank() over(partition by uid order by ts desc) as rk from movies;
denes_rank()如果两个元素相等,则序号相同,不会跳过下个序号。
3、collect_list()

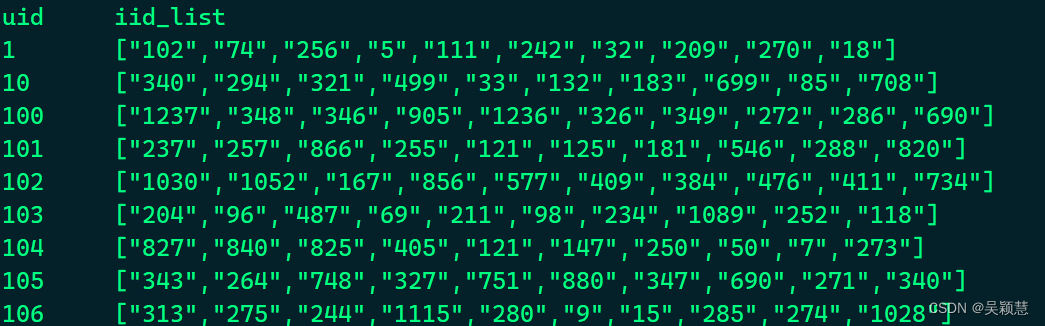
select a.uid,collect_list(a.iid) as iid_list
from (select uid,iid,score,ts,row_number() over(partiton by uid order by ts decs) as rk from movies) a
where a.rk <= 10
group by a.uid;
collect_list 可将列转行,查找用户最近观看的10部电影。
4、collect_set()
collect_list和collect_set的区别:collect_set对结果去重。
最后
以上就是老迟到饼干最近收集整理的关于hive分区排序row_number、rank和dense_rank,列转行collect_list和collect_set的全部内容,更多相关hive分区排序row_number、rank和dense_rank内容请搜索靠谱客的其他文章。








发表评论 取消回复