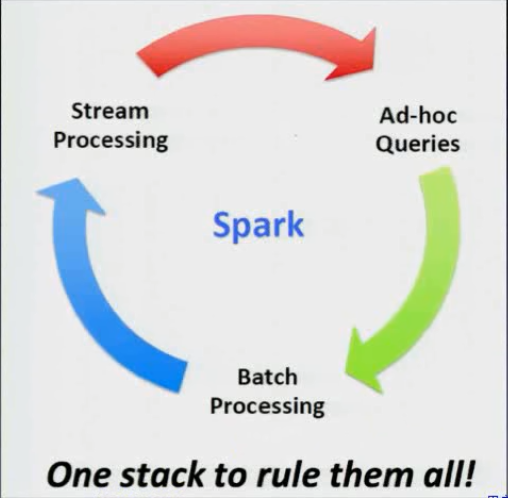
1.统一的RDD抽象和操作,基于该抽象一个栈就可以轻松的处理实时流计算,SQL交互式查询,机器学习和图计算等。
基于统一的技术堆栈,使得Spark称为大数据通用计算平台。
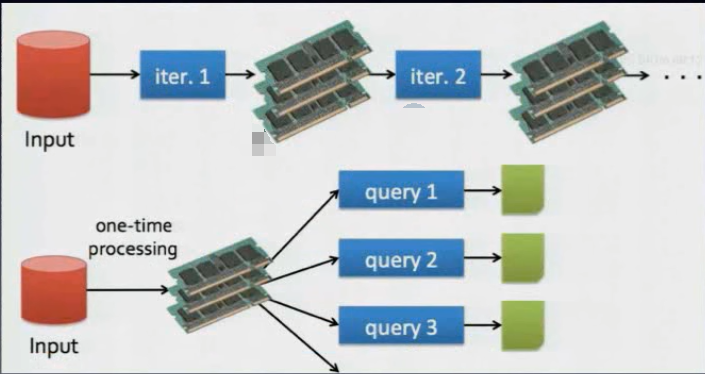
2.基于内存的迭代式计算
回顾下hadoop中经典处理过程:
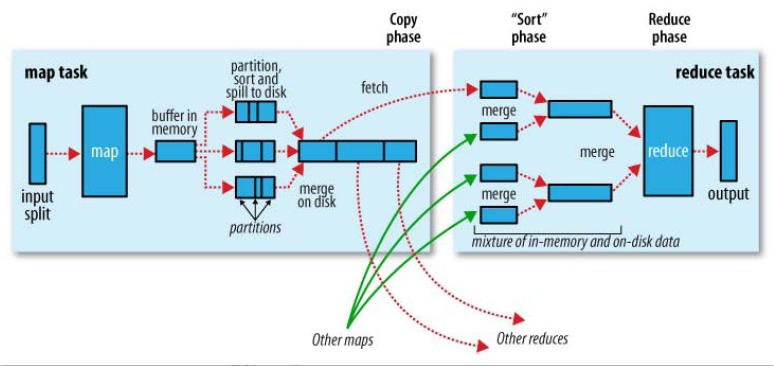
MapReduce在每次执行时都要从磁盘读取数据,计算完毕后都要把数据存放到磁盘上。
比如:机器学习的时候,会不断的迭代数据 ,这样的话,会消耗大量的IO

而Spark是基于内存的。
3.DAG
它可以把整个执行过程做一个图,然后进行优化。
最后
以上就是能干发带最近收集整理的关于Spark为啥比hadoop速度快?的全部内容,更多相关Spark为啥比hadoop速度快内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复