Apache Spark是一个开放源代码群集计算框架,正在点燃大数据世界。根据Spark认证专家的说法,与Hadoop相比,Sparks的性能在内存上快100倍,在磁盘上快10倍。 在此博客中,我将为您简要介绍Spark架构以及Spark架构的基础知识。
在这篇Spark Architecture文章中,我将介绍以下主题:
- Spark及其功能
- Spark架构概述
- 星火生态系统
- 弹性分布式数据集(RDD)
- Spark架构的工作
- 在Spark Shell中使用Scala的示例
Spark及其功能
Apache Spark是一个用于实时数据处理的开源集群计算框架。Apache Spark的主要功能是其 内存中群集计算 ,可提高应用程序的处理速度。Spark提供了一个接口,用于使用隐式数据并行性和容错性对整个集群进行编程。它旨在涵盖各种工作负载,例如批处理应用程序,迭代算法,交互式查询和流式处理。
Apache Spark的功能:
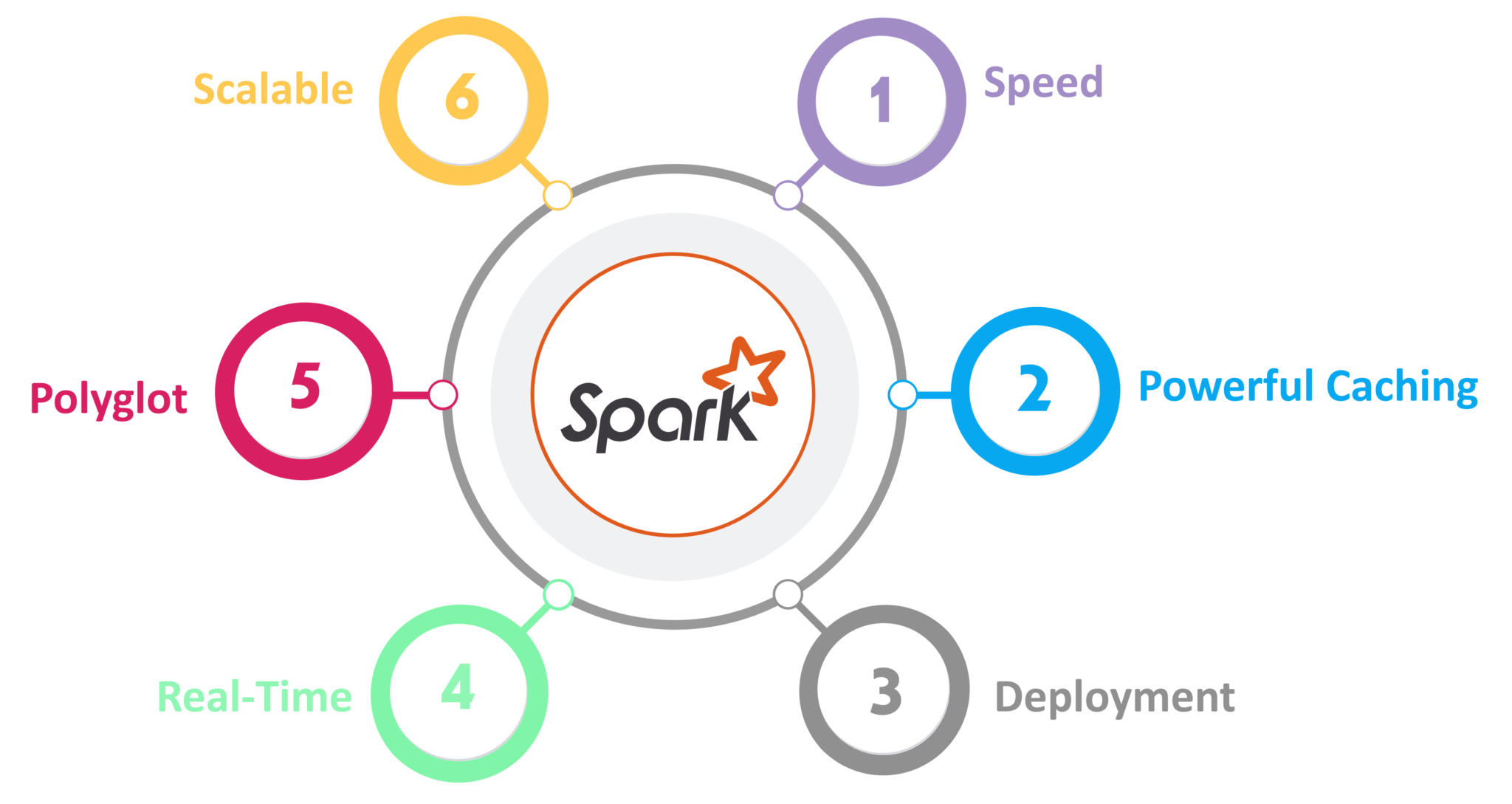
图:Spark的功能
对于大规模数据处理,Speed Spark的运行速度比Hadoop MapReduce快100倍。它还可以通过受控分区来达到此速度。- 强大的缓存
简单的编程层提供了强大的缓存和磁盘持久性功能。 - 部署
可以通过Mesos,通过YARN的Hadoop或Spark自己的集群管理器进行部署。 - 实时
由于内存中的计算,它提供实时计算和低延迟。 - Polyglot
Spark提供Java,Scala,Python和R的高级API。Spark代码可以用这四种语言中的任何一种编写。它还提供了Scala和Python中的Shell。
Spark架构概述
Apache Spark具有定义明确的分层体系结构,其中所有spark组件和层都松散耦合。该体系结构进一步与各种扩展和库集成在一起。Apache Spark架构基于两个主要抽象:
- 弹性分布式数据集(RDD)
- 有向无环图(DAG)
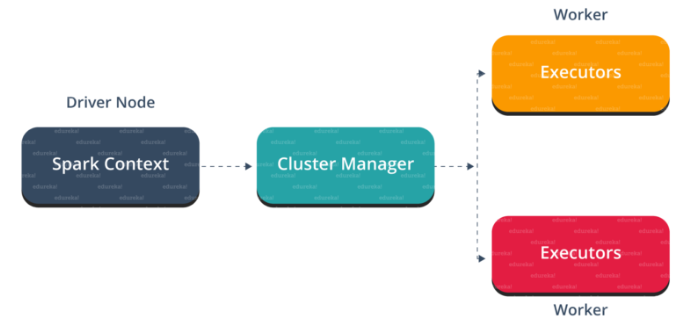
图:Spark体系结构
但是在更深入地介绍Spark架构之前,让我解释一下Spark的一些基本概念,例如Spark生态系统和RDD。这将帮助您获得更好的见解。
首先让我解释一下什么是Spark生态系统。
星火生态系统
从下图可以看到,spark生态系统由各种组件组成,例如Spark SQL,Spark Streaming,MLlib,GraphX和Core API组件。

图:Spark生态系统
- Spark Core
Spark Core是大规模并行和分布式数据处理的基本引擎。此外,建立在核心顶部的其他库允许进行流,SQL和机器学习的各种工作负载。它负责内存管理和故障恢复,计划,分配和监视群集上的作业以及与存储系统进行交互。 - Spark Streaming
Spark Streaming是Spark的组件,用于处理实时流数据。因此,它是核心Spark API的有用补充。它支持实时数据流的高吞吐量和容错流处理。 - Spark SQL
Spark SQL是Spark中的一个新模块,它将关系处理与Spark的功能编程API集成在一起。它支持通过SQL或Hive查询语言查询数据。对于熟悉RDBMS的人来说,Spark SQL将是您早期工具的轻松过渡,您可以在其中扩展传统关系数据处理的范围。 - GraphX
GraphX是用于图形和图形并行计算的Spark API。因此,它使用弹性分布式属性图扩展了Spark RDD。在较高层次上,GraphX通过引入弹性分布式特性图(具有附加到每个顶点和边的特性的有向多图)来扩展Spark RDD抽象。 - MLlib(机器学习)
MLlib代表机器学习库。Spark MLlib用于在Apache Spark中执行机器学习。 - SparkR
它是R包,提供分布式数据帧实现。它还支持选择,过滤,聚合等操作,但要处理大量数据集。
如您所见,Spark附带了高级库,包括对R,SQL,Python,Scala,Java等的支持。这些标准库增加了复杂工作流程中的无缝集成。除此之外,它还允许各种服务集与其集成,例如MLlib,GraphX,SQL +数据框架,流服务等,以增强其功能。
现在,让我们讨论Spark的基本数据结构,即RDD。
订阅我们的YouTube频道以获取新的更新...
弹性分布式数据集(RDD)
RDD是任何Spark应用程序的构建块。RDD代表:
- 弹性: 容错,并能够在发生故障时重建数据
- 分布式: 集群中多个节点之间的分布式数据
- 数据集: 使用值收集分区数据
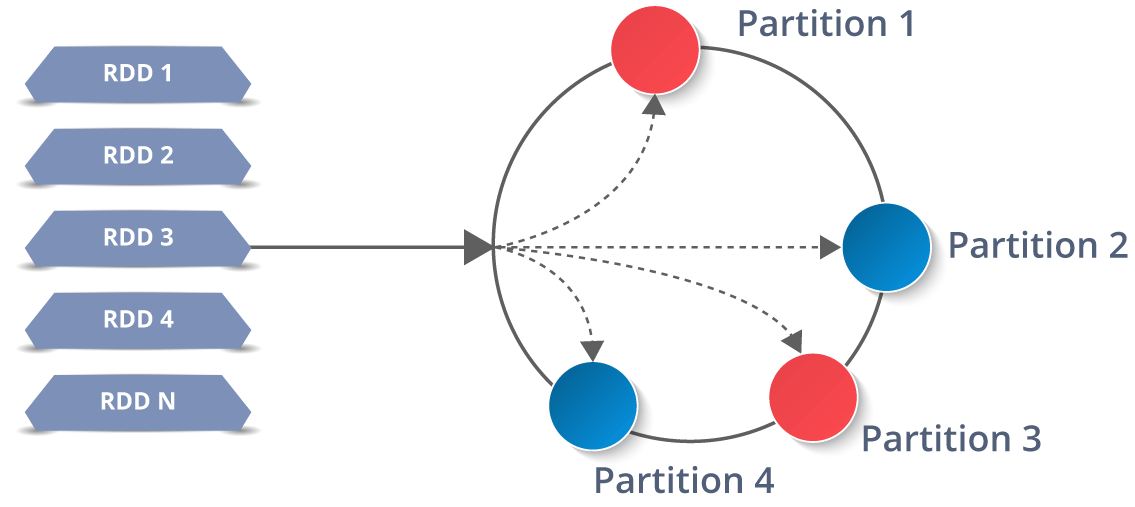
它是分布式集合上的抽象数据层。它本质上是一成不变的,并遵循 惰性变换。
现在您可能想知道它的工作原理。好了,RDD中的数据根据一个密钥分为多个块。RDD具有很高的弹性,即,当跨多个执行程序节点复制相同的数据块时,它们能够从任何问题中快速恢复。因此,即使一个执行者节点发生故障,另一个执行者节点仍将处理数据。这使您可以利用多个节点的功能非常快速地对数据集执行功能计算。
而且,一旦创建了RDD,它就变得不可变。我所说的不可变是指一个对象,其状态在创建后无法修改,但可以确定地进行转换。

Apache Spark和Scala认证培训
- 讲师指导的课程
- 现实生活中的案例研究
- 评估
- 终身访问
说到分布式环境,RDD中的每个数据集都分为逻辑分区,可以在群集的不同节点上进行计算。因此,您可以并行对完整数据执行转换或操作。另外,您不必担心分发问题,因为Spark会处理这些问题。
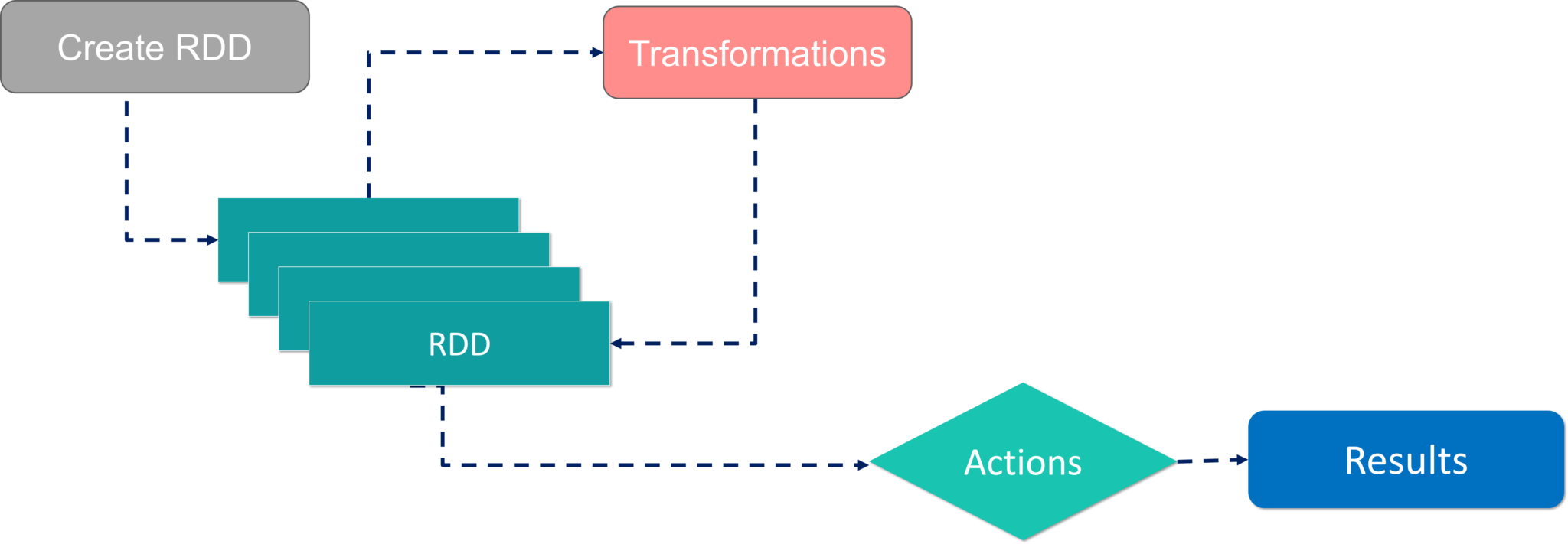
RDD的工作流程
有两种创建RDD的方法-并行化驱动程序中的现有集合,或通过引用外部存储系统(例如共享文件系统,HDFS,HBase等)中的数据集。
使用RDD,您可以执行两种类型的操作:
- 转换:它们是用于创建新RDD的操作。
- 行动: 它们在RDD上应用,以指示Apache Spark应用计算并将结果传递回驱动程序。
希望您对RDD概念有透彻的了解。现在,让我们进一步看一下Spark Architecture的工作。
Spark架构的工作
您已经了解了Apache Spark的基本体系结构概述,现在让我们更深入地研究其工作原理。
在主节点中,您有驱动程序,它驱动您的应用程序。您正在编写的代码充当驱动程序,或者,如果您正在使用交互式外壳,则该外壳将充当驱动程序。
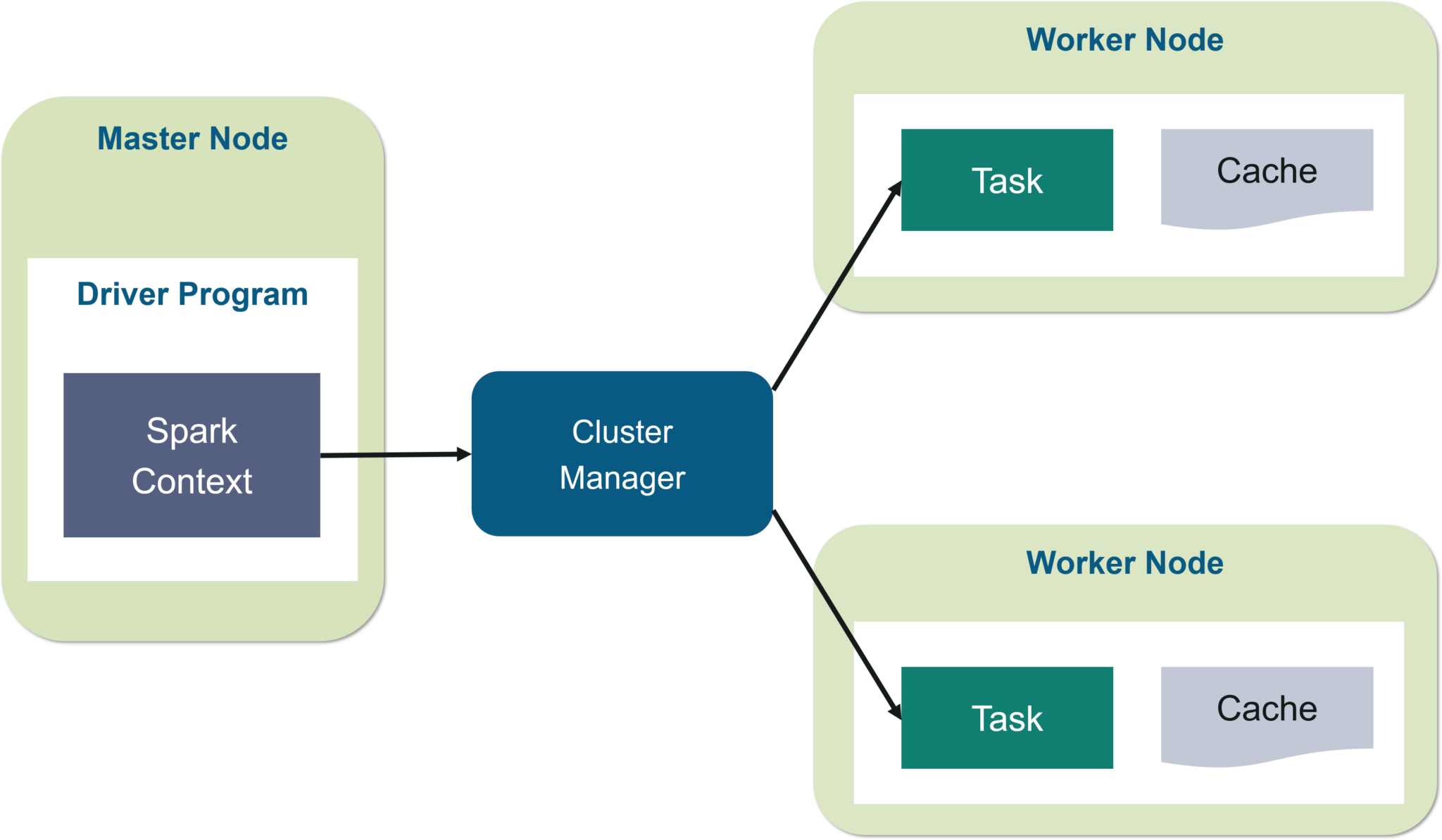
图:Spark体系结构
我n面的驱动程序,你要做的第一件事是,你创建 一个星火语境。假设Spark上下文是所有Spark功能的网关。它类似于您的数据库连接。您在数据库中执行的任何命令都将通过数据库连接进行。同样,您在Spark上执行的所有操作都会通过Spark上下文。
现在,此Spark上下文可与集群管理器一起使用以管理各种作业。驱动程序和Spark上下文负责集群中的作业执行。作业分为多个任务,这些任务分布在工作节点上。每当在Spark上下文中创建RDD时,它就可以分布在各个节点上并可以缓存在该节点上。
w ^ orker节点是从节点,其任务是执行基本任务。这些任务然后在工作节点中的分区RDD上执行,因此将结果返回给Spark上下文。
Spark Context接管该工作,将其分解为任务并将其分发到工作程序节点。这些任务在分区的RDD上工作,执行操作,收集结果并返回到主Spark上下文。
如果增加工作人员的数量,则可以将作业划分为更多的分区,然后在多个系统上并行执行它们。它将更快。
随着工作人员数量的增加,内存大小也将增加,您可以缓存作业以更快地执行它。
要了解Spark Architecture的工作流程,可以查看下面的信息图:
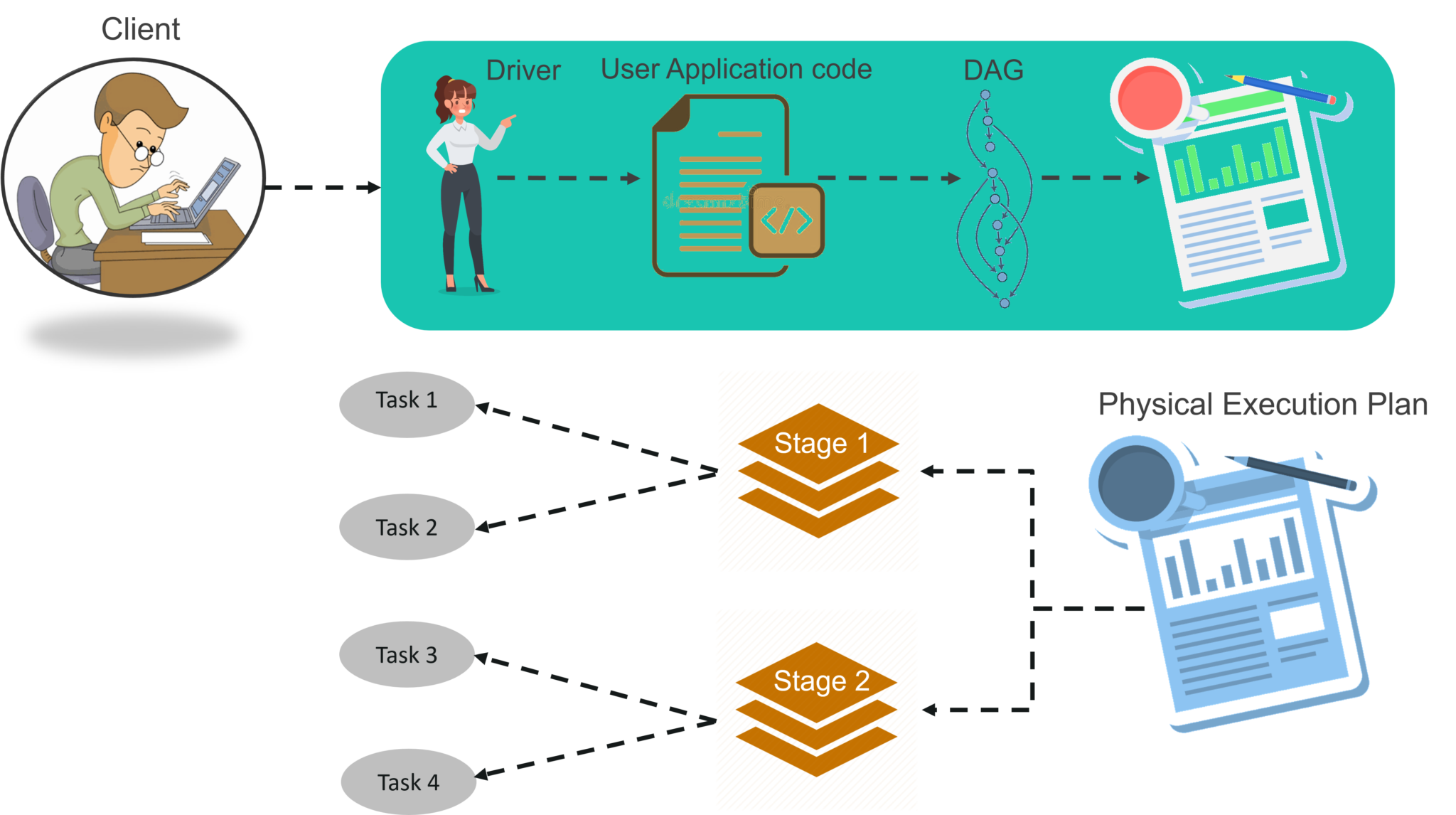
图:Spark Architecture信息图
步骤1: 客户端提交Spark用户应用程序代码。 提交应用程序代码后,驱动程序会将包含转换和操作的用户代码隐式转换为称为 DAG的逻辑定向非循环图。 在此阶段,它还会执行优化,例如流水线转换。
大数据培训
大数据HADOOP认证培训
大数据Hadoop认证培训
评论使用PYSPARK进行PYTHON SPARK认证培训
使用PySpark进行Python Spark认证培训
评论APACHE SPARK和SCALA认证培训
Apache Spark和Scala认证培训
评论SPLUNK培训和认证-高级用户和管理员
Splunk培训和认证-高级用户和管理员
评论APACHE KAFKA认证培训
Apache Kafka认证培训
评论HADOOP管理认证培训
Hadoop管理认证培训
评论ELK STACK培训和认证
ELK Stack培训和认证
评论全面的HIVE认证培训
全面的Hive认证培训
评论APACHE STORM认证培训
Apache Storm认证培训
评论步骤2:之后,它将称为DAG的逻辑图转换为具有多个阶段的物理执行计划。 转换为物理执行计划后,它将在每个阶段创建称为任务的物理执行单元。然后将任务捆绑并发送到集群。
步骤3:现在,驱动程序与集群管理器进行对话并协商资源。 群集管理器代表驱动程序在工作程序节点中启动执行程序。 此时,驱动程序将根据数据放置将任务发送给执行者。 执行者启动时,便向驱动程序注册自己。因此,驱动程序将具有 执行任务的执行者的完整视图。
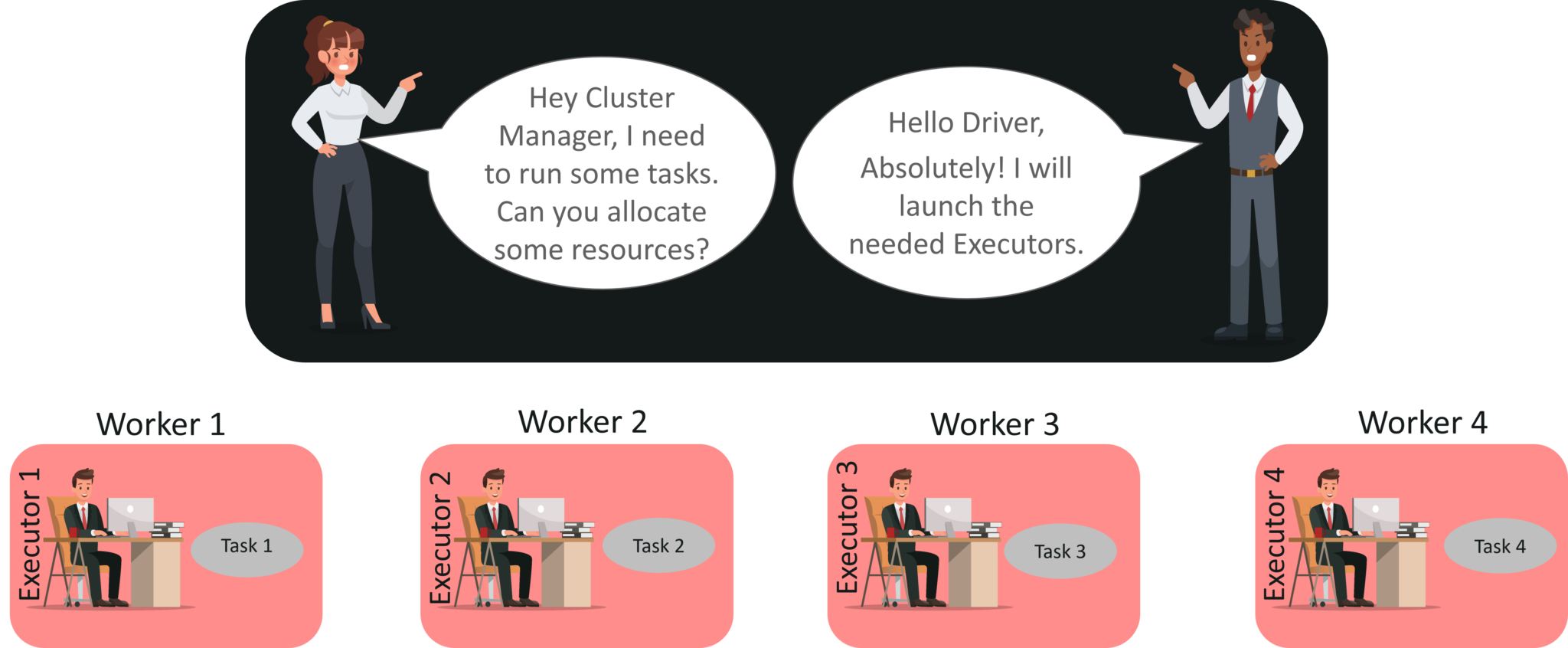
步骤4: 在执行任务的过程中,驱动程序将监视运行的执行程序集。驱动程序节点还基于数据放置安排将来的任务。
这一切都与Spark Architecture有关。现在,让我们来了解一下Spark Shell的工作。
在Spark Shell中使用Scala的示例
首先,让我们假设Hadoop和Spark守护程序已启动并正在运行,以启动Spark Shell。 Spark的Web UI端口是localhost:4040。
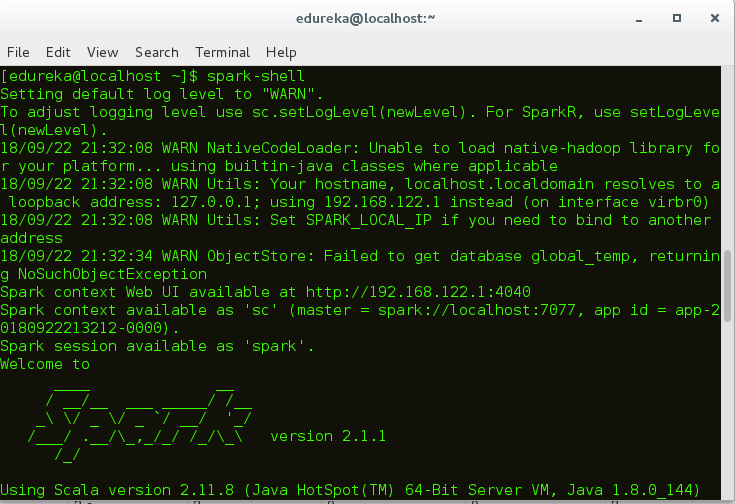
无花果:火花壳
启动Spark Shell之后,现在让我们看看如何执行字数统计示例:
- 在这种情况下,我创建了一个简单的文本文件并将其存储在hdfs目录中。您也可以使用其他大型数据文件。
 图:输入文本文件
图:输入文本文件 - 火花壳启动后, 让我们创建一个RDD。为此,您必须 指定输入文件路径并应用转换flatMap()。下面的代码说明了相同的内容:
|
1个
|
scala> var map = sc.textFile("hdfs://localhost:9000/Example/sample.txt").flatMap(line => line.split(" ")).map(word => (word,1));
|
3.执行该代码后,将如图所示创建一个RDD。

图:RDD创建
4.之后,您需要将动作reduceByKey()应用于创建的RDD。
|
1个
|
scala> var counts = map.reduceByKey(_+_);
|
应用动作后,执行如下所示开始。

图:在shell中执行Spark
5.下一步是将输出保存在文本文件中,并指定存储输出的路径。
![]()
图:指定输出路径
6.指定输出路径后,转到 hdfs Web浏览器localhost:50040。在这里,您可以在“零件”文件中看到输出文本,如下所示。
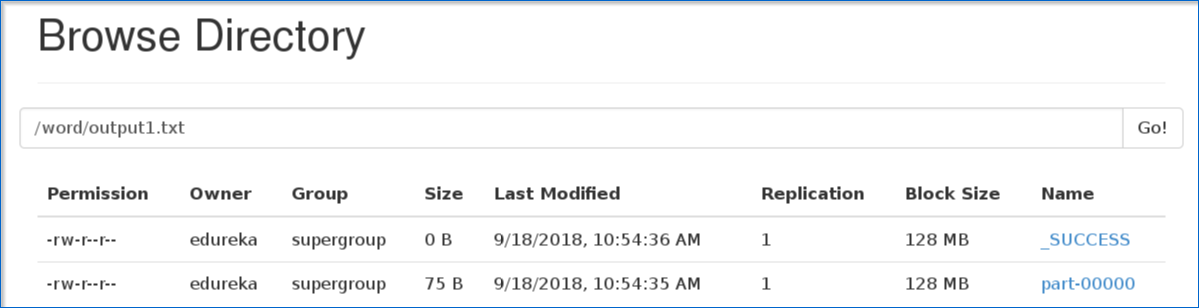
图:输出零件文件
7.下图显示了'part'文件中存在的输出文本。
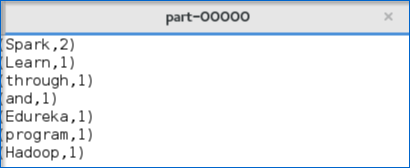
图:输出文本
希望您已经了解如何创建Spark应用程序并获得输出。

Apache Spark和Scala认证培训
平日/周末批次查看批次详细信息现在,让我带您浏览Spark的Web UI,以了解DAG可视化和已执行任务的分区。
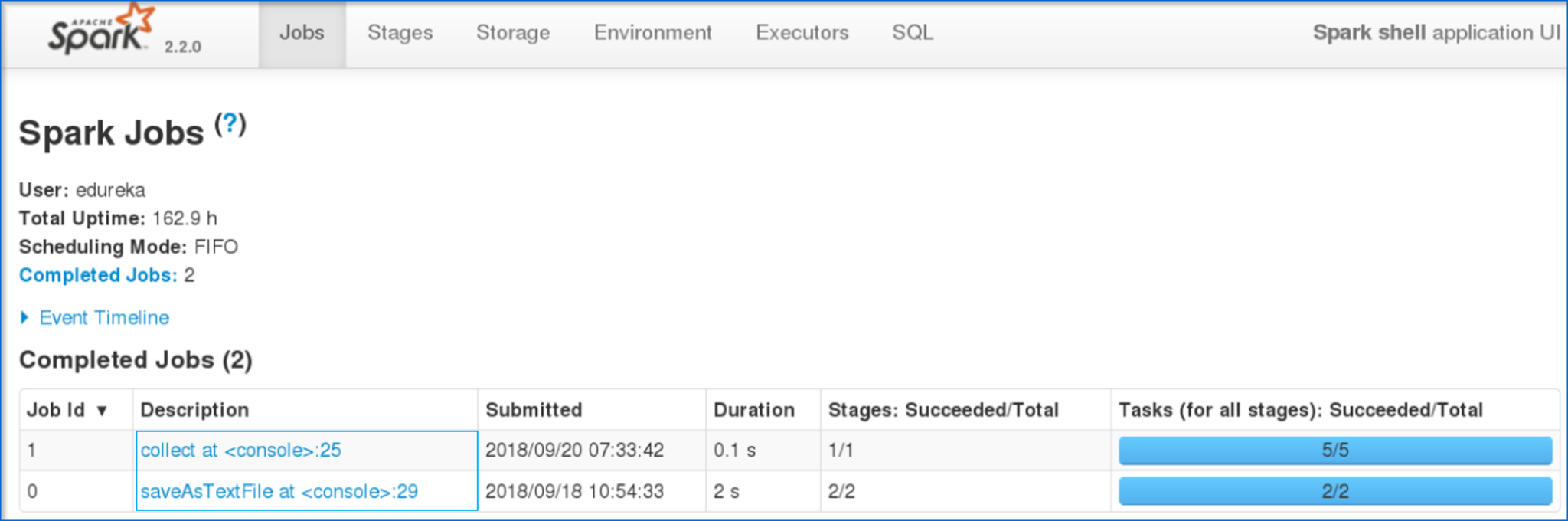
图:Spark Web用户界面
- 单击您提交的任务后,您可以查看已完成作业的有向无环图(DAG)。
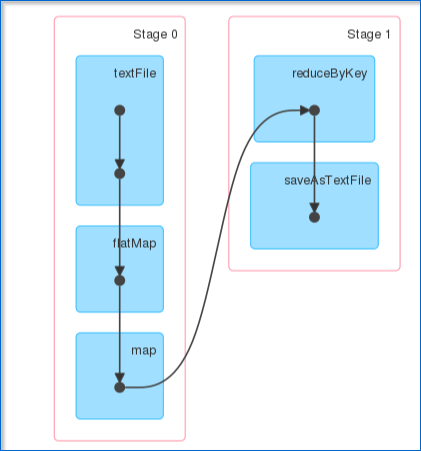
图:DAG可视化
- 此外,您还可以查看已执行任务的摘要指标,例如–执行任务所需的时间,作业ID,完成的阶段,主机IP地址等。
现在,让我们了解RDD中的分区和并行性。
- 甲分区是一个逻辑 块 a的大 分布式 数据 集。
- 默认情况下,星火试图读取 数据 到 一个 RDD从节点是接近 到 它。
现在,让我们看看如何在Shell中执行并行任务。
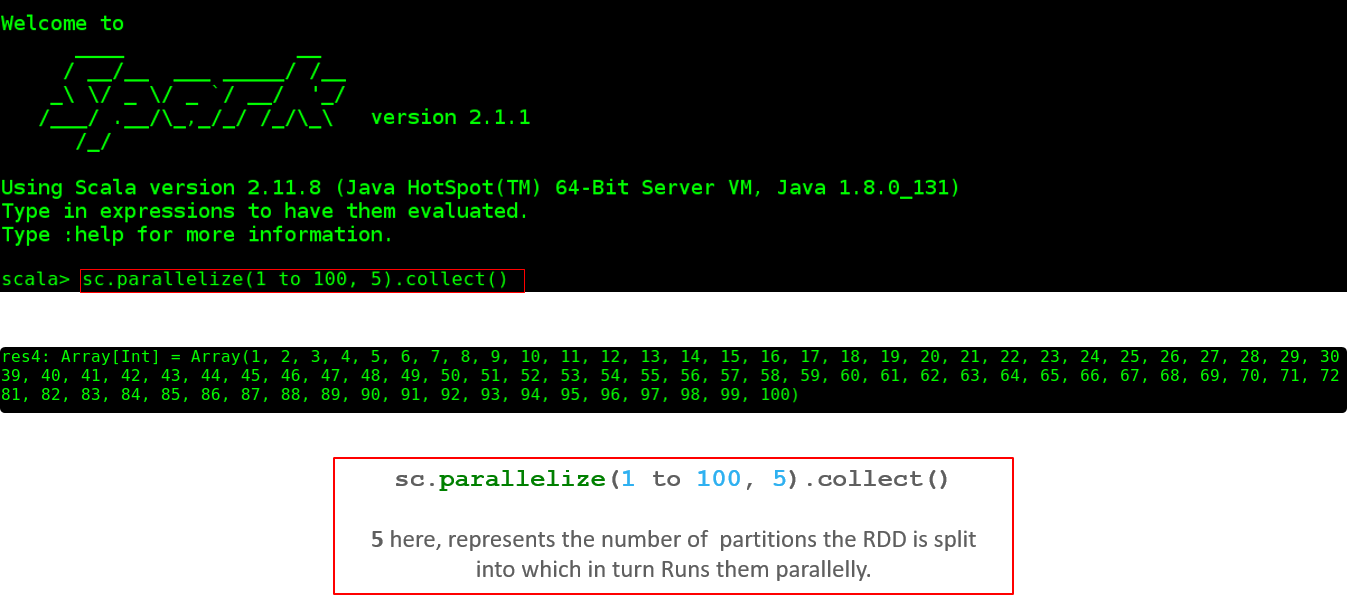
图:任务的并行执行
- 下图显示了创建的RDD上的分区总数。
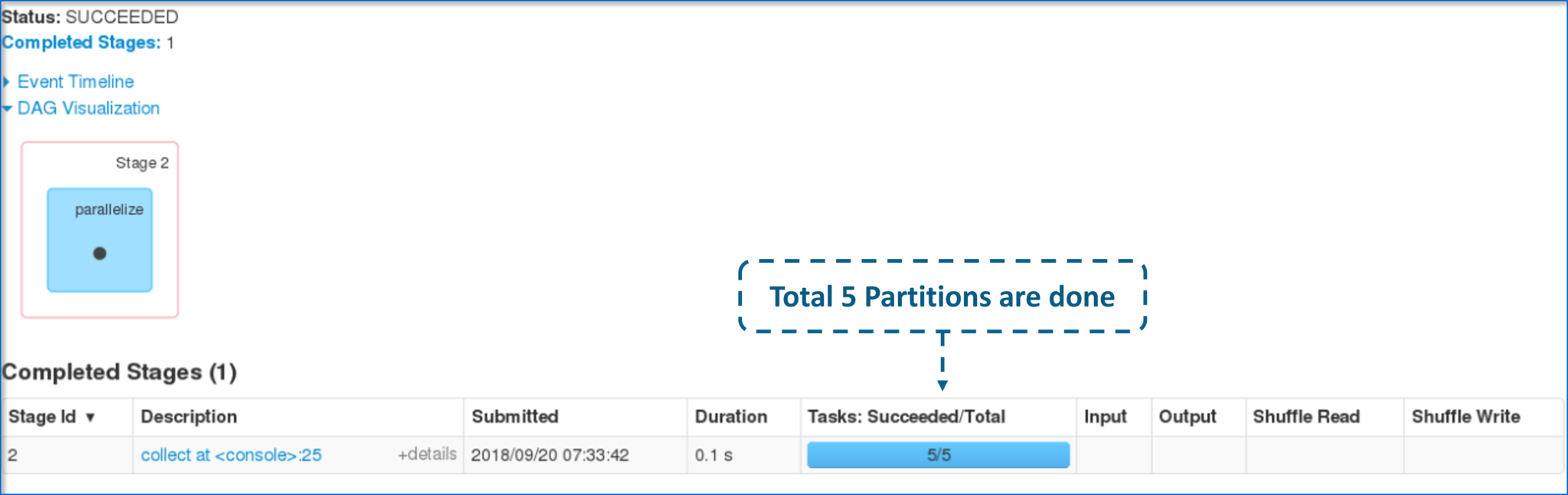
图:已完成任务的分区
- 现在,让我向您展示5个不同任务的并行执行情况。
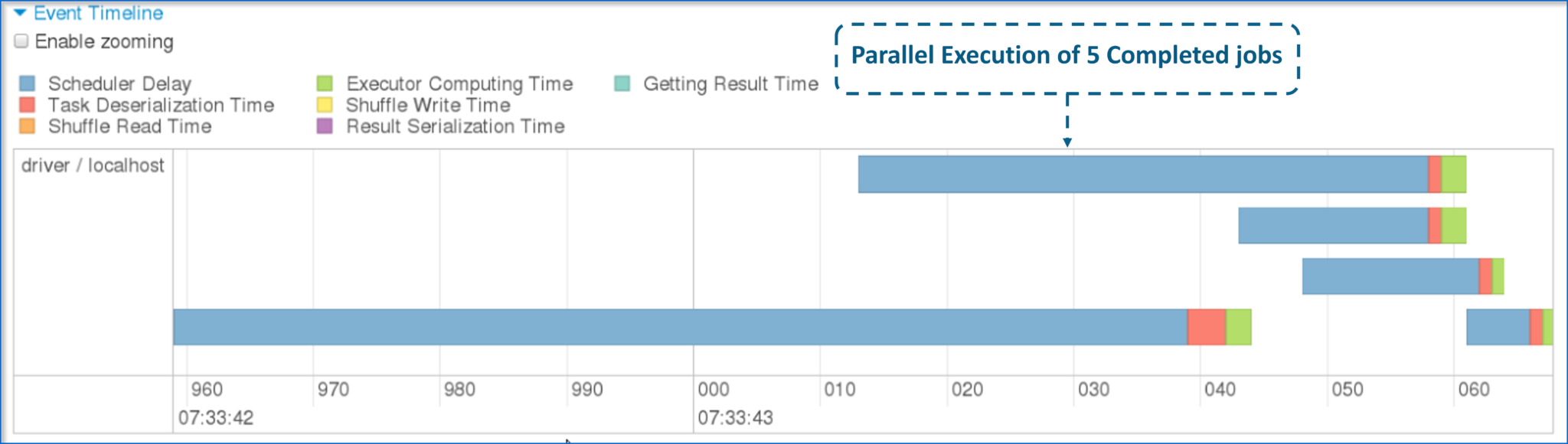
图:5个已完成任务的并行性
这使我们到了Apache Spark Architecture博客的结尾。我希望该博客能为您提供丰富的信息,并为您的知识增添价值。
最后
以上就是留胡子外套最近收集整理的关于Apache Spark体系结构– Spark集群体系结构介绍的全部内容,更多相关Apache内容请搜索靠谱客的其他文章。








发表评论 取消回复