Map Reduce存在的问题
在介绍Spark首先需要介绍为何要提出Spark,Hadoop高度支持的Map Reduce框架有什么不好的地方吗?
答:没有完美的机制,Map Reduce范式存在下面问题
1、模型能处理的应用有限,主要基于Map和Reduce处理,存在很多限制
2、中间的文件储存在内存里,但是最后MR-output文件存在在文件系统里,涉及到磁盘读取的问题。在一个Map Reduce里存在大量Disk IO问题,效率很低
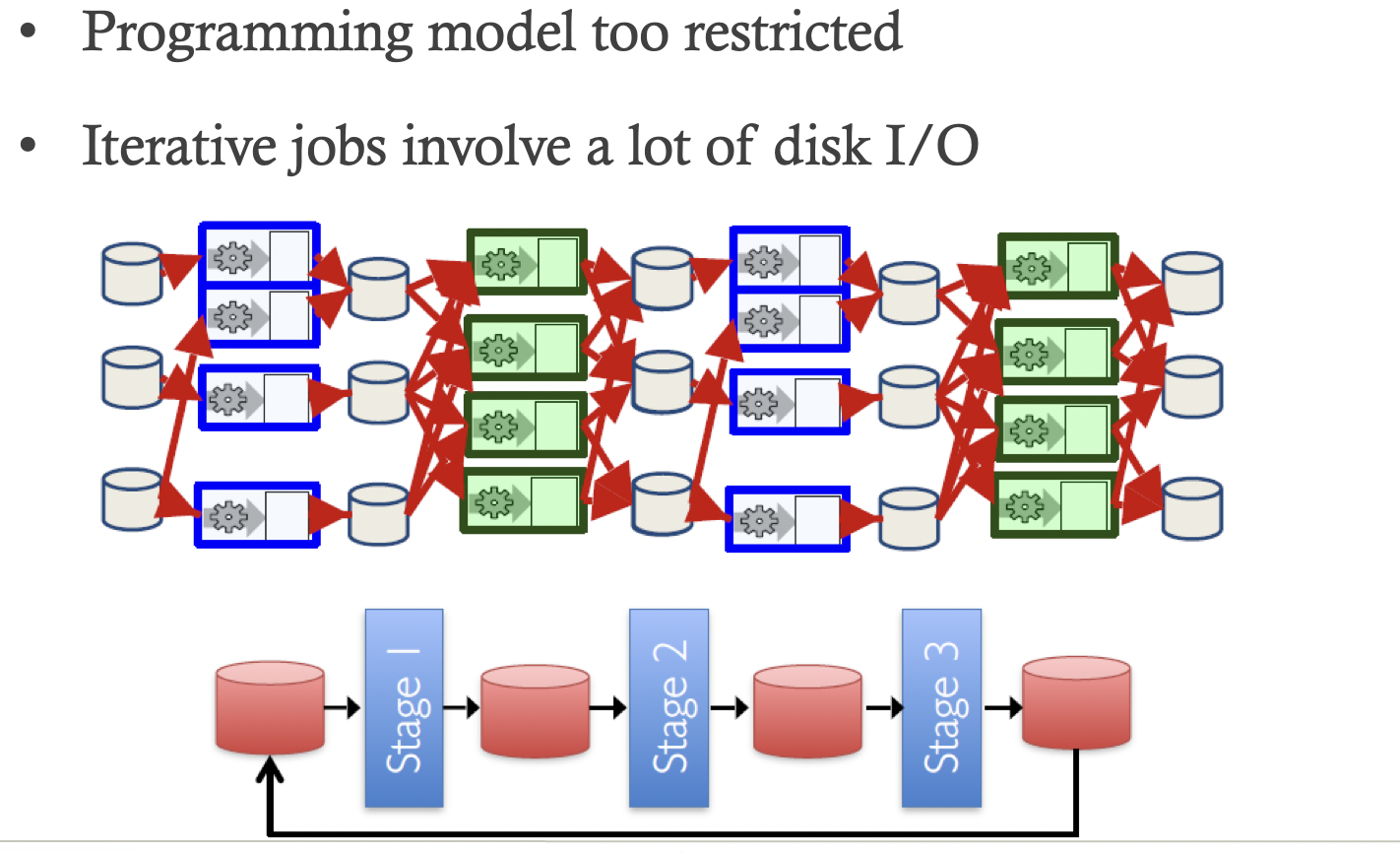
因此在Hadoop的基础上提出了大量的附加系统,例如:
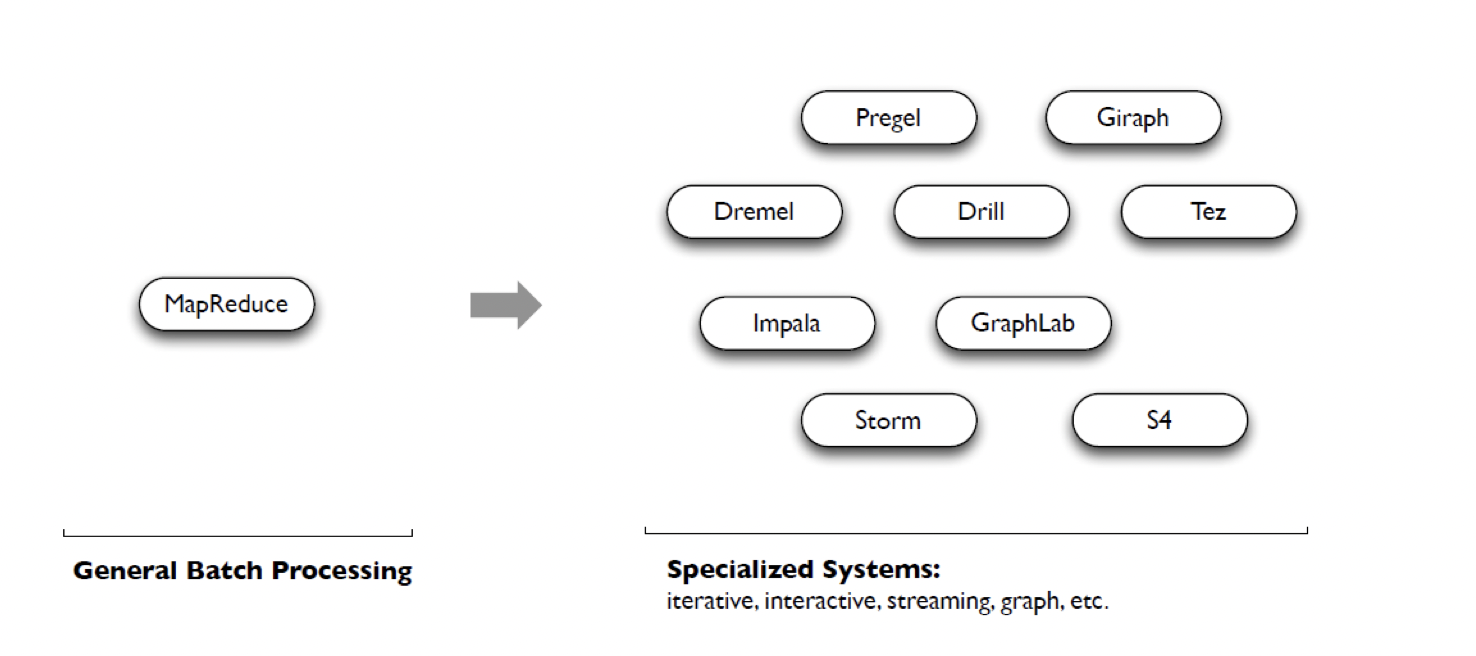
大体分为四种类型:Iterative,Interactive,Streaming,Graph
Spark介绍
Spark具有如下特性:

Spark本身会倾向于把数据存储在内存里,这时效率会百倍于Hadoop。
即使数据量过大,无法在内存里完全缓存,Spark也可以把数据缓存在Disk里,效率依然10倍于hadoop。
另外,Spark提供了交互的shell和丰富支持多语言的API。
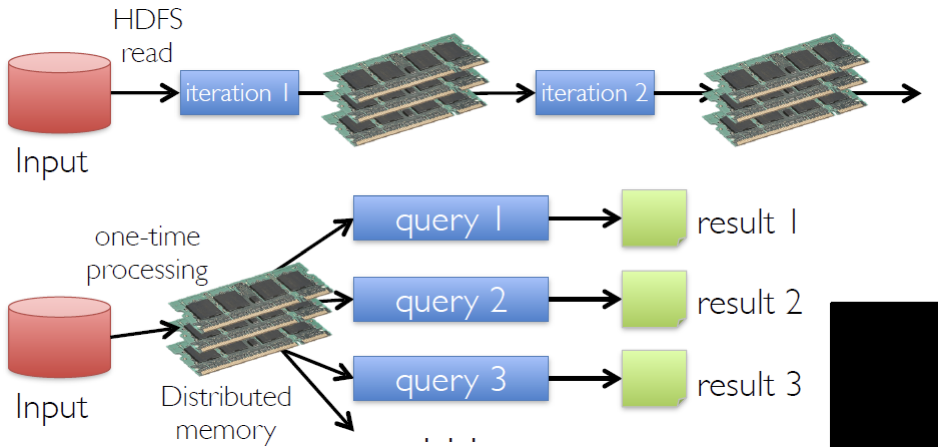

二者区别示意图
Spark编程
上面主要介绍了Spark的一些基本概念,这里将介绍Spark编程的相关技巧与关键点。
提到Spark不可不提的一个概念就是RDD。
RDD全称为Resilient Distributed Datasets,他会把数据映射到不同的partition然后再按照相同的要求进行处理。
RDD会不断将数据按照要求进行transformation转换,并将结果保存在RDD或者Persistent Storage上。
最关键的一点:RDD不需要被Materialized
可以简单理解为,RDD的机制为用时计算,不用的话即使计算会出问题从头打尾也不会注意到
用户编程时除了代码主要可以控制以下两点
1、Persistence
2、Partitioning
Partition设置技巧
Partition设置过小:并行程度不够,整体运行效率较低
Partition设置过大:核是固定的,任务量过多对于提升效率没有太大帮助;且任务传输过程中除了本身的数据还会连带上很多其他数据,导致task的序列化和传输速率降低
核心点:
 执行会自动进行流水线和并行化,无需储存中间结果(当然有些时候可能为了提升效率或达到一定目的依然需要对中间结果进行缓存)
执行会自动进行流水线和并行化,无需储存中间结果(当然有些时候可能为了提升效率或达到一定目的依然需要对中间结果进行缓存)
容错机制
RDD has enough information about how it was derived from to compute its partitions from data in stable storage.
例如,如果RDD某个Partition执行失败,RDD只会重新运行涉及到那个Paritition的line而不会重新运行整个程序
Spark本身的编程模型类似于Lineage Graph,Partitions在不同的节点并行计算,不需要从头开始运行。
Spark编程API

这里将spark的API分为了两类,Transformations和Actions。
Transformations不会得到确定结果,因此也不会进行具体计算。
Actions表示需要展开行动得到实际的值,因此Action API会启动之前全部的计算过程。
编程示例
sc为SparkText,启动spark shell会自动进行初始化,可以直接通过sc.textFile()使用
map负责将一个元素映射为另一个元素,例:
>>> a = sc.parallelize(range(1,100000))
>>> b = a.map(lambda x: math.sqrt(x))reduce负责遍历整个元素集进行合并等操作,例:
textFile.map(lambda line: len(line.split()))
.reduce(lambda a, b: a if (a > b) else b)
统计包含单词最多的行
lines = sc.textFile("README.md")
lineLengths = lines.map(lambda s: len(s))
totalLength = lineLengths.reduce(lambda a, b: a + b)
正如前面所提到的那样,Spark很多时候不会缓存之前执行的结果,sc.fileText()得到的只是一个指向文件的指针,后续操作因为laziness机制也不会立刻执行,直到reduce操作才在各个机器上单独运行任务,生成map中间结果到本地内存,最后生成的结果返回给driver program。
另外需要特别注意的是,通常spark程序在执行完毕后要加上sc.stop()语句,以结束应用,避免资源浪费
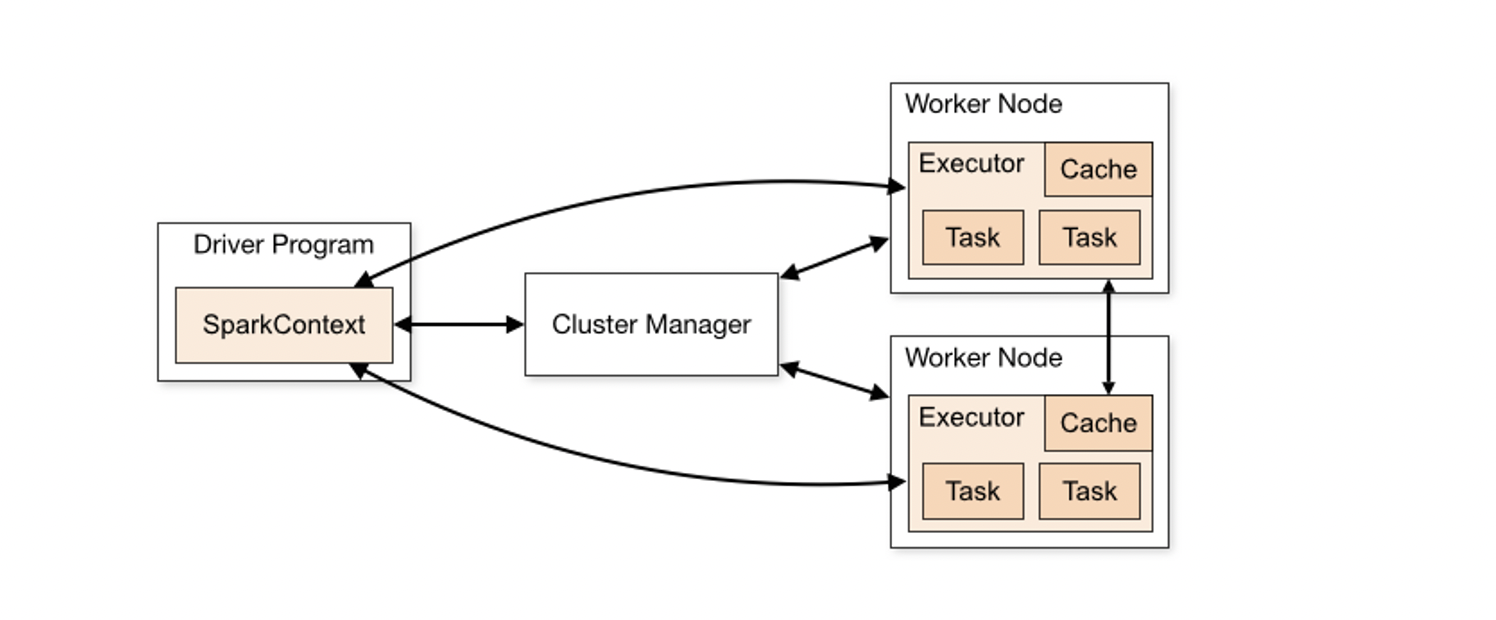
Spark集群实际工作流程图
核心概念:Closure
这种代码是错误的:
var counter = 0
var rdd = sc.parallelize(data)
// Wrong: Don't do this!!
rdd.foreach(x => counter += x)
println("Counter value: " + counter)
错误原因:这里foreach就是一个闭包,里面包括的全局变量counter实际上并不像我们想的那样是counter,而是全局变量counter的一个副本。因此在单点上运行也许能得到正确的结果,但是在集群上运行时这里的counter不会发生变化。
解决方案:引入accumulator这种可以实现安全分发以及统计的机制。
不过accumulator本身也有风险。accumulator会传递到多个partition里,这样如果一个partition错误执行,之后其再次执行时accumulator会执行两次,导致计算出现问题。
Spark Print输出机制
# test closure
counter = 0
rdd = sc.parallelize(range(20))
def increment_counter(x):
global counter
counter+=x
print(counter)
print(rdd.collect())
rdd.foreach(increment_counter)
print(counter)
print(rdd.sum())global用于声明全局变量以便后续对变量进行修改,为python语法
如果不声明为global的话会报下述异常:
UnboundLocalError: local variable 'counter' referenced before assignment
Python本身在函数里使用全局变量无需使用global声明,如果要修改全局变量的值便需要使用global声明
另外这里值得注意的一点是,spark执行后并没有print出对应的信息主要原因如下:
1、spark面向集群,打印输出流的话会涉及内容输出到哪里的问题
2、数据量一般很大,本身不适合打印
因此基于上述考虑,spark采用了屏蔽print语句的方法
Spark缓存机制
如下述示例代码所示:
rdd = sc.parallelize(range(10))
accum = sc.accumulator(0)
def g(x):
global accum
accum += x
return x * x
a = rdd.map(g)
print("accum value1:",accum.value)
print(a.reduce(lambda x, y: x+y))
# 核心语句 a.cache
a.cache()
tmp = a.count()
print("accum value2:",accum.value)
print(rdd.reduce(lambda x, y: x+y))
tmp = a.count()
print("accum value3:",accum.value)
print(rdd.reduce(lambda x, y: x+y))不注释掉a.cache时,运行结果为:
accum value1: 0 285 accum value2: 90 45 accum value3: 90 45
注释掉a.cache时,运行结果为:
accum value1: 0 285 accum value2: 90 45 accum value3: 135 45
疑惑1:为何accum value2为90而非45
疑惑2:为何accum value2、3的值在cache时一样,在不cache时不一样
原理是:如果不缓存a的话每次执行action都需要重新计算a的内容,连带的更新accum的值。第一次在cache前计算了两次a,故结果为90
去除cache的话value2计算两次,value3计算三次,故值不一样
程序示例:用spark实现线性时间查找
• Problem:– Input: an array A of n numbers (unordered), and k– Output: the k- th smallest number (counting from 0)• Algorithm1. x = A[0]2. partition A into
A[0..mid-1] < A[mid] = x < A[mid+1..n-1]3. if mid = k then return x4. if k < mid then A = A[0..mid-1]
if k > mid then A = A[mid+1,n-1], k = k – mid – 15. go to step 1
原始程序:
# Linear-time selection
data = [34, 67, 21, 56, 47, 89, 12, 44, 74, 43, 26]
A = sc.parallelize(data,2)
k = 4
while True:
x = A.first()
A1 = A.filter(lambda z: z < x)
A2 = A.filter(lambda z: z > x)
mid = A1.count()
if mid == k:
print(x)
break
if k < mid:
A = A1
else:
A = A2
k = k - mid - 1得到的结果是67而非我们期待的43,原因为:没有对A1,A2或A进行任何缓存,导致在第二轮循环时linear graph会出现问题
到第二轮时,第一次的A1依然需要进行计算,第一轮X对应的值应该是34,但因为linear graph只知道根据x进行计算,x此时为67,故先取小于67的,再取大于67的,得到空集结果,返回67。
解决方案:对A进行缓存
data = [34, 67, 21, 56, 47, 89, 12, 44, 74, 43, 26]
A = sc.parallelize(data,2)
k = 4
while True:
x = A.first()
A1 = A.filter(lambda z: z < x)
A2 = A.filter(lambda z: z > x)
mid = A1.count()
if mid == k:
print(x)
break
if k < mid:
A = A1
else:
A = A2
k = k - mid - 1
A.cache() // Key Point更直观的例子如下所示:
A = sc.parallelize(range(10))
x = 5
B = A.filter(lambda z: z < x)
# B.cache()
print(B.count())
x = 3
print(B.count())得到的结果为5,3
一个使用技巧是,经常使用take而非collect,collect有时运行逻辑会出现问题
A = sc.parallelize(range(10))
x = 5
B = A.filter(lambda z: z < x)
# B.cache()
B.unpersist()
# print(B.take(10))
print(B.collect())
x = 3
#print(B.take(10))
print(B.collect())
# collect() doesn't always re-collect data - bad design!
# Always use take() instead of collect()在这个情况下,我们期待结果不一样,但打印结果一样,出现了问题
Map与FlatMap的区别
如果一个line里有多个结果过,Map会把结果依然映射为多个数组,例如
[[1,2],[3,4]]
FlatMap则会把拆开的结果合并到一起,得到最终的结果
上面的结果通过flatMap使用会得到:[1,2,3,4]
Map Reduce范式Spark实现示例
from operator import add
lines = sc.textFile('./data/course.txt')
counts = lines.flatMap(lambda x: x.split())
.map(lambda x: (x, 1))
.reduceByKey(add)
print(counts.sortByKey().take(20))通过map构造键值对,然后通过reduceByKey自动进行合并(
合并里可以写常见函数,也可以使用函数实现独特合并。例如,除了使用reduceByKey(add)外,还可以使用reduceByKey(lambda x,y:x*y)等来实现
同理,sort也可以按照不同规则进行排序,例如:
counts.sortBy(lambda x: x[1], False).take(20)
Join与BroadCast的区别
参考链接:spark broadcast join优化 - 简书
在有小副本的情况下可以使用broad来减少shuflle过程
最后
以上就是大方世界最近收集整理的关于Spark讲解与使用的全部内容,更多相关Spark讲解与使用内容请搜索靠谱客的其他文章。








发表评论 取消回复