度量和环境
销售额、库存、访问量、熟客量就是度量。缺乏上 下文和环境来谈度量是没有意义的。比如销售额是3000元,这一单独的数字并不能带来任何帮助。
度量和环境是构成维度建模的基础。所有维度建模正是通过对度量和及其上下文和环境的详细设计来实现的。
事实
常以数值的形式出现,并且一般被大量文本形式的上下文包围着。这些文本形式的上下文描述了实时的5个W。(when where who what why)信息。通常可以被直观的分割为独立的逻辑块。每个独立的逻辑块即为一个维度。

事实表如上,下面2个数值就是度量(事实)。有
可加类型
半可加类型
不可加类型
星形架构和雪花架构
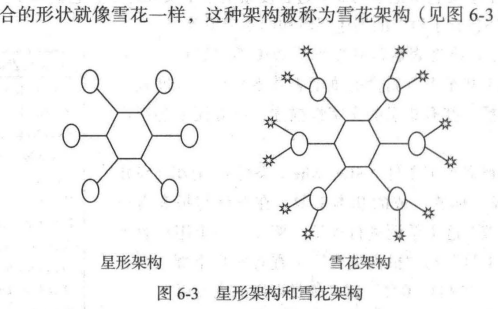
星形式一种非规范化的结构,冗余严重。但是在使用上带来了极度便利。
雪花架构去除冗余。但是下游麻烦。可能要关联三个表。
维度建模的一般过程
1.选取业务过程
2.定义力度
3.确定维度
4.确定事实
维度表设计
1.维度变化
重写维度值、新增行、新增列
2.维度层次
维度层次是指某个维度表中属性之间存在的从属关系。比如商品类目可能有层次的(一级、二级、三级)
一种是扁平化,对应星形
一种是建立类目维度表,对应雪花
*钻取:
下钻增加维度。例如当前是广东省全年销量汇总。增加时间和地点,就变成了计算2月份惠州销量
上钻减少维度。上诉过程的逆过程。
3.维度一致性
具体:列名(横)和领域(竖:可以为NULL但是键要有)一样
一模一样
or
一个是另一个的子集
4.维度表整合和拆分
说白了就是不同的前台业务系统的数据要不要整合到同一张维度表里。
如果要:命名、字段类型、字段编码和含义都要相同
如果不要:能否考虑把相同的属性放在一张维度表里。这样就有三张表
以下是各种维度技术介绍
5.退化维度
就是事实表那些看起来是事实表的一个维度关键字,但实际上并没有对应的维度表的字段。一般是事务编号
6.行为维度

7.角色维度
一个事实表中的多个外健指向同一个维度表。即一个维度表扮演多个角色。、、
事实表和维度表存在一对多关系,这时候没有必要为维度表简历多个副本,只需要基于维度表家里多个视图即可。
8.杂项维度
事务型商业过程通常产生一系列混杂的、低粒度的标识和指示器(属性只有YES NO)。与其为每个标识或属性定义不同的维度,,不如建立单独的将不同的维度合并在一起的杂项维度。通常又叫做事物型概要维度。不需要所有属性可能值的笛卡尔积,但应该包含实际发生在源数据中的合并值。
9.微型维度
根据需要将一些属性从原有的维度表中分离出来单独组合成一个或多个新的维度表。
一般快变超大维度才需要这样的拆分。例如客户维度表。有临时客户和会员客户。临时客户900、会员100。那么到店时间这种公共属性值就会很多。而名字就只有100。这时候公共属性就是快变超大。把公共值抽取出来,成为一个单独的维度。这样节约储存空间。
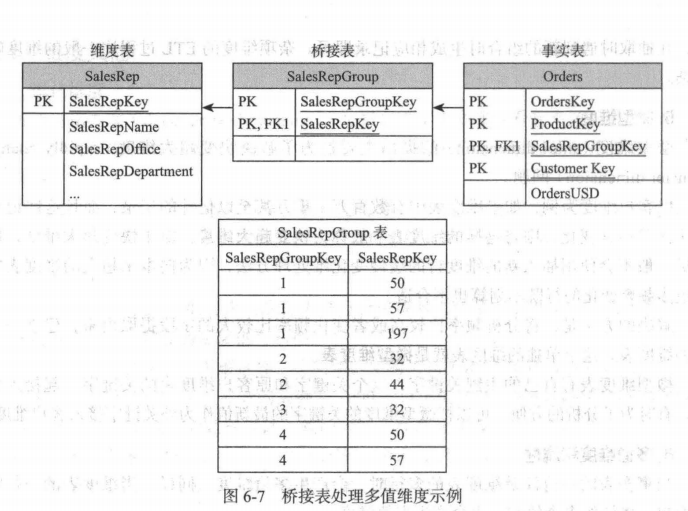
10.多值维度
当事实表的一行涉及到维度表的多行时,会产生多值维度。比如银行的联名账户有多个账户人。
解决办法:
第一:扁平化多值维度,在事实表中引入多列。比如联名账户最多3人拥有,就引入3个拥有人列(第一拥有人、第二拥有人、、、、)
第二:桥接表
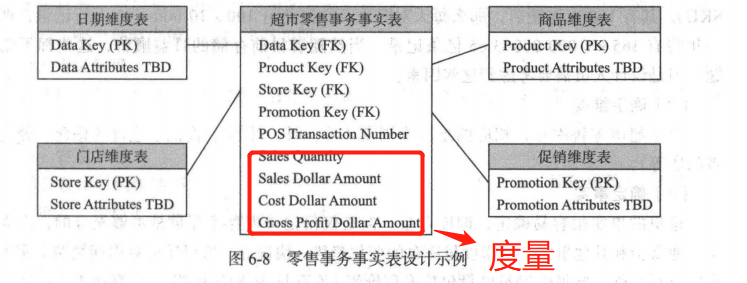
事实表的设计
事物事实表是维度建模事实表中最为常见、使用最为广泛的事实表。
确定业务过程->定义粒度->确定维度->确定事实
确定事实:
寻找度量和事实。对于超市来说就是销售数量、价格、销售金额。成本价是确定的,因此可以确定销售毛利。像毛利率就不放入事实表。一是非可加,二是有一个原则“只存放分子和分母”。
1.周期快照事实表
指间隔一定的周期对业务的状态进行一次拍照并记录下来的事实表。最常见的例子是销售库存、银行账户余额
周期快照通常被认为是稠密的。因为无论有咩有变化,都要拍照。
该事实表的事实一般是半可加的(这个就很好理解啦)
一个鞋子不同颜色,每个颜色就是一个SKU
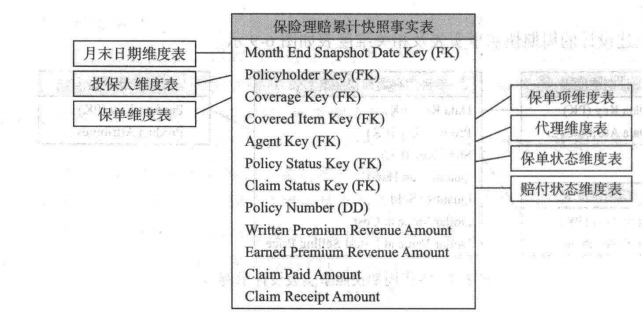
2.累计快照事实表


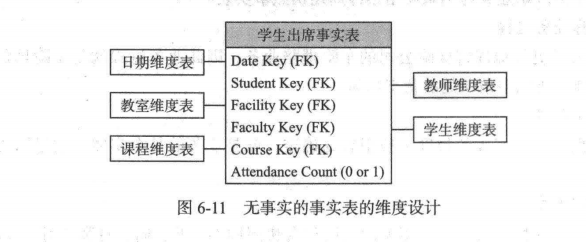
3.无事实的事实表
例如用户在网站的浏览行为、用户对广告点击行为、学生出席情况
4.汇总的事实表
把相同的粒度的事实合并为一个单一的事实表。例如现货销售可以与销售预测合并为一张事实表。合并事实表会增加ETL的负担。但是会减少BI的分析代价。
最后
以上就是可爱鼠标最近收集整理的关于离线大数据开发实战(读书笔记)-- 第五章 维度建模技术的全部内容,更多相关离线大数据开发实战(读书笔记)--内容请搜索靠谱客的其他文章。








发表评论 取消回复