ES-Hadoop无缝打通了ES和Hadoop两个非常优秀的框架,我们既可以把HDFS的数据导入到ES里面做分析,也可以将es数据导出到HDFS上做备份,归档,其中值得一提的是ES-Hadoop全面的支持了Spark框架,其中包括Spark,Spark Streaming,Spark SQL,此外也支持Hive,Pig,Storm,Cascading,当然还有标准的MapReduce,无论用那一个框架集成ES,都是非常简洁的。
最后ES-Hadoop对各种版本的Hadoop都支持,这里面包含社区版本的Apache Hadoop,Cloudrea的CDH,MapR以及Hortonworks的HDP 所以无论我们使用哪个版本的Hadoop都可以非常easy的与ES集成,从而让ES的强大性能帮助我们快速分析海量数据。
上篇文章了,写了使用spark集成es框架,并向es写入数据,虽然能够成功,但从集成度上来讲肯定没有官网提供的ES-Hadoop框架来的优雅,今天我们就来认识一下ES-Hadoop这个框架。
我们都知道Hadoop是标准的大数据生态代表,里面有非常多的组件来处理不同类型或者场景下的数据,Hadoop的基础组件是YARN,HDFS,MapReduce,我们都知道HDFS是可靠的分布式存储系统,大多数我们都是用MapReduce来分析数据,唯一的不足之处在于速度,为了解决这种问题所以才有了Hbase,Spark,Kylin,Presto,Imapla等等许多框架。而我们的elasticsearch却恰恰相反,尤其是其定位高性能的搜索引擎,处理多维数据的检索分析非常高效,此外ES也是一个分布式的,高可靠的,可扩展的搜索框架,这些特点也决定了其处理海量数据的效率也是非常出色的。但es和hadoop属于两个不同的框架,如果想互相共享数据来处理,就需要自己来写程序把各自的数据导入需要的一方,过程非常繁琐,并且需要关注各自框架的版本,从而容易出现问题。
ES-Hadoop的出现则解决了这个问题,我们可以把它看做是ES和Hadoop大数据生态圈之间的数据桥梁,通过它,我们可以快速的分析Hadoop里面的海量数据。
前面说了Hadoop的MapReduce定位是一个离线的批处理计算框架,而现在越来越多的服务,都要求是实时或者近实时的交互式分析,通过ES-Hadoop我们可以轻松的将Hadoop集群上面的数据导入到ES,从而通过使用ES来获得高性能,低延迟,并支持各种聚合,空间检索以及产品推荐的一些特性。最后还可以使用Kibana提供的可视化的数据分析一条龙服务,非常棒的组合。
整个数据流转图如下:
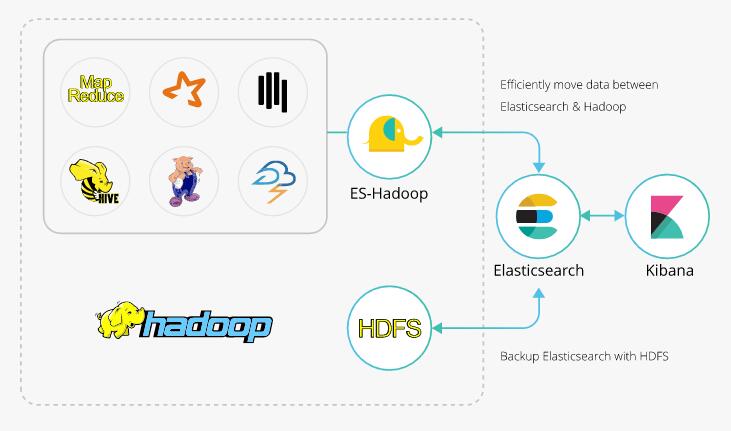
ES-Hadoop无缝打通了ES和Hadoop两个非常优秀的框架,我们既可以把HDFS的数据导入到ES里面做分析,也可以将es数据导出到HDFS上做备份,归档,其中值得一提的是ES-Hadoop全面的支持了Spark框架,其中包括Spark,Spark Streaming,Spark SQL,此外也支持Hive,Pig,Storm,Cascading,当然还有标准的MapReduce,无论用那一个框架集成ES,都是非常简洁的。
最后ES-Hadoop对各种版本的Hadoop都支持,这里面包含社区版本的Apache Hadoop,Cloudrea的CDH,MapR以及Hortonworks的HDP 所以无论我们使用哪个版本的Hadoop都可以非常easy的与ES集成,从而让ES的强大性能帮助我们快速分析海量数据。
有什么问题可以扫码关注微信公众号:我是攻城师(woshigcs),在后台留言咨询。 技术债不能欠,健康债更不能欠, 求道之路,与君同行。

最后
以上就是陶醉小兔子最近收集整理的关于ES-Hadoop插件介绍的全部内容,更多相关ES-Hadoop插件介绍内容请搜索靠谱客的其他文章。








发表评论 取消回复