Series:带标签的数组
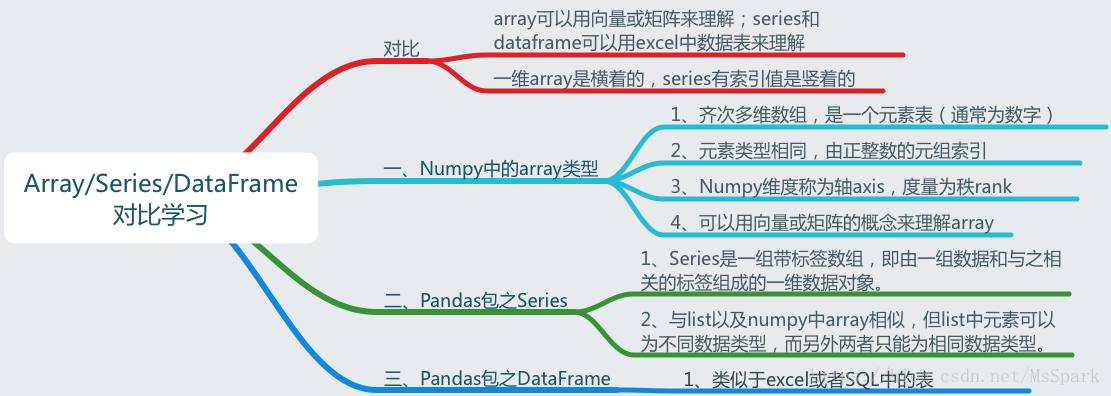
本文对Pandas包中的一维数据类型Series特点及用法进行了总结归纳。
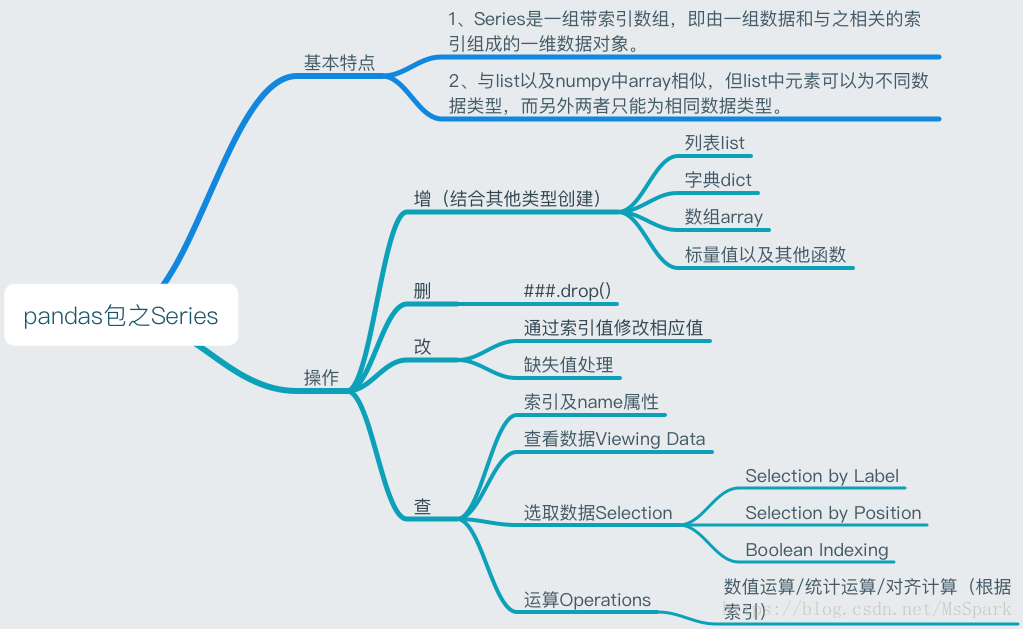
2.1 如何创建Series
#导入Pandas包
import pandas as pd
#创建Series
#1.1.1 通过列表List
listSer=pd.Series([10,20,30,40])
print(listSer)
#1.1.2 通过字典dict
dictSer=pd.Series({'a':10,'b':40,'c':5,'d':90,'e':35,'f':40},name='数值')
print(dictSer)
#1.1.3 通过array
import numpy as np
arrySer=pd.Series(np.arange(10,15),index=['a','b','c','d','e'])
print(arrySer)
[output]
0 10
1 20
2 30
3 40
dtype: int64
a 10
b 40
c 5
d 90
e 35
f 40
Name: 数值, dtype: int64
a 10
b 11
c 12
d 13
e 14
dtype: int64
2.2 索引及name属性
Series类型包括(index,values)两部分
#index
print(arrySer.index)
#values
print(arrySer.values)
[output]
Index(['a', 'b', 'c', 'd', 'e'],dtype='object')
[10 11 12 13 14]
2.3 获取数据
#iloc通过位置获取数据
dictSer[0:1] #相当于dictSer.iloc[0:1]
>>>
a 10
Name: 数值, dtype: int64
#loc通过索引获取数据
dictSer[['a','b']] #相当于dictSer.loc[['a','b']]
>>>
a 10
b 40
Name: 数值, dtype: int64
#boolean indexing获取值
dictSer[dictSer.values<=10] #获取值不超过10的数据
>>>
a 10
c 5
Name: 数值, dtype: int64
dictSer[dictSer.index!='a'] #获取索引值不是a的数据
>>>
b 40
c 5
d 90
e 35
f 40
Name: 数值, dtype: int64
2.4 基本运算
查看描述性统计数据
dictSer.describe()
>>>
count 6.000000
mean 36.666667
std 30.276504
min 5.000000
25% 16.250000
50% 37.500000
75% 40.000000
max 90.000000
Name: 数值, dtype: float64
dictSer.mean() #均值
dictSer.median() #中位数
dictSer.sum() #求和
dictSer.std() #标准差
dictSer.mode() #众数
dictSer.value_counts() #每个值的数量
数学运算
dictSer/2 #对每个值除2
dictSer//2 #对每个值除2后取整
dictSer%2 #取余
dictSer**2 #求平方
np.sqrt(dictSer) #求开方
np.log(dictSer) #求对数
对齐计算
dictSer2=pd.Series({'a':10,'b':20,'d':23,'g':90,'h':35,'i':40},name='数值')
dictSer3=dictSer+dictSer2
dictSer3
>>>
a 20.0
b 60.0
c NaN
d 113.0
e NaN
f NaN
g NaN
h NaN
i NaN
Name: 数值, dtype: float64
2.5 缺失值处理
#找出空/非空值
dictSer3[dictSer3.notnull()] #非空值
>>>
a 20.0
b 60.0
d 113.0
Name: 数值, dtype: float64
dictSer3[dictSer3.isnull()] #空值
>>>
c NaN
e NaN
f NaN
g NaN
h NaN
i NaN
Name: 数值, dtype: float64
#填充空值
dictSer3=dictSer3.fillna(dictSer3.mean()) #用均值来填充缺失值
>>>
a 20.000000
b 60.000000
c 64.333333
d 113.000000
e 64.333333
f 64.333333
g 64.333333
h 64.333333
i 64.333333
Name: 数值, dtype: float64
2.6 删除值
dictSer3=dictSer3.drop('b')
print(dictSer3)
>>>
a 20.000000
c 64.333333
d 113.000000
e 64.333333
f 64.333333
g 64.333333
h 64.333333
i 64.333333
Name: 数值, dtype: float64
如果对于本文中代码或数据有任何疑问,欢迎评论或私信交流
相近文章:
Numpy中Array用法总结
Pandas中DataFrame用法总结
最后
以上就是甜美寒风最近收集整理的关于Python-Pandas中Series用法总结的全部内容,更多相关Python-Pandas中Series用法总结内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复