**
python3爬虫进阶之自动登录网易云音乐并爬取指定歌曲评论
**
一、访问网易云首页,找到所需元素的位置
用浏览器打开网易云首页https://music.163.com/之后,发现我们要找的登录就在网页的右上角如图一,但是又有很多登录选项没有列出来,只有鼠标移动到登录按钮的位置并点击才会显示出来如图二。
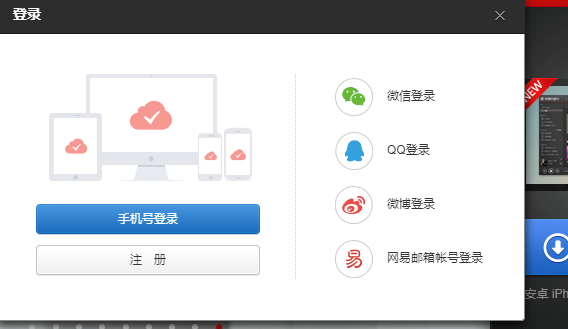
这里我们选择手机号登录
def login(id, passwd):
url = 'https://music.163.com/'
browser = webdriver.Chrome()
browser.get(url)
time.sleep(5) # 等待5秒,待界面完全加载
element = browser.find_element_by_xpath('//div[@class="m-tophead f-pr j-tflag"]')
ActionChains(browser).move_to_element(element).perform()
s1 = '//div[@class="m-tophead f-pr j-tflag"]/div/div/ul/li/a/em' # 手机登录标签的Xpath
browser.find_element_by_xpath(s1).click() # 点击手机登录
time.sleep(3)
browser.find_element_by_name('p').clear()
browser.find_element_by_name('p').send_keys(id) # 输入用户账户
browser.find_element_by_name('pw').clear()
browser.find_element_by_name('pw').send_keys(passwd) # 输入用户密码
browser.find_element_by_xpath('//div/a[@class="j-primary u-btn2 u-btn2-2"]').click() # 点击登录
二、跳转至指定歌曲界面并爬取评论
我选取的是《盗将行》这首歌,程序运行如下图:

将所有的评论内容,用户名,用户ID和被赞次数保存成csv文件。
三、附源码
from selenium import webdriver
from selenium.webdriver import ActionChains
import time
import random
import math
def login(id, passwd):
url = 'https://music.163.com/'
browser = webdriver.Chrome()
browser.get(url)
time.sleep(5) # 等待5秒,待界面完全加载
element = browser.find_element_by_xpath('//div[@class="m-tophead f-pr j-tflag"]')
ActionChains(browser).move_to_element(element).perform()
s1 = '//div[@class="m-tophead f-pr j-tflag"]/div/div/ul/li/a/em' # 手机登录标签的Xpath
browser.find_element_by_xpath(s1).click() # 点击手机登录
time.sleep(3)
browser.find_element_by_name('p').clear()
browser.find_element_by_name('p').send_keys(id) # 输入用户账户
browser.find_element_by_name('pw').clear()
browser.find_element_by_name('pw').send_keys(passwd) # 输入用户密码
browser.find_element_by_xpath('//div/a[@class="j-primary u-btn2 u-btn2-2"]').click() # 点击登录
def start_spider(url):
"""启动Chrome浏览器访问页面"""
brower = webdriver.Chrome()
brower.get(url)
# 等待5s,让评论加载完毕
time.sleep(5)
# 页面嵌套一层iframe,必须切换到iframe,才能定位到iframe里面的元素
iframe = brower.find_element_by_class_name('g-iframe')
brower.switch_to.frame(iframe)
# 获取【最新评论】总数
new_comments = brower.find_elements_by_xpath("//h3[@class='u-hd4']")[1]
max_page = get_max_page(new_comments.text)
print("================")
print(max_page)
# 接着循环抓取评论数据,首先抓取第1页的评论数据
current = 1
is_first = True
while current <= max_page:
print('正在爬取第', current, '页的数据')
if current == 1:
is_first = True
else:
is_first = False
data_list = get_comments(is_first, brower)
savef_data_to_mongo(data_list)
time.sleep(1)
go_nextpage(brower)
time.sleep(random.randint(8, 12))
current += 1
# 根据评论总数计算出总分页数
def get_max_page(new_comments):
"""根据评论总数计算出总页数"""
print('===' + new_comments + '===')
max_page = new_comments.split('(')[1].split(')')[0]
# 每页显示20条最新评论
offset = 20
max_page = math.ceil(int(max_page) / offset)
print('总共有', max_page, '页')
return max_page
def get_comments(is_first, brower):
"""获取评论数据"""
items = brower.find_elements_by_xpath("//div[@class='cmmts j-flag']/div[@class='itm']")
# 首页的数据中包含15条精彩评论,20条最新评论,只保留最新评论
if is_first:
items = items[15: len(items)]
data_list = []
data = {}
for each in items:
# 用户id
userId = each.find_elements_by_xpath("./div[@class='head']/a")[0]
userId = userId.get_attribute('href').split('=')[1]
# 用户昵称
nickname = each.find_elements_by_xpath("./div[@class='cntwrap']/div[1]/div[1]/a")[0]
nickname = nickname.text
# 评论内容
content = each.find_elements_by_xpath("./div[@class='cntwrap']/div[1]/div[1]")[0]
content = content.text.split(':')[1] # 中文冒号
# 点赞数
like = each.find_elements_by_xpath("./div[@class='cntwrap']/div[@class='rp']/a[1]")[0]
like = like.text
if like:
like = like.strip().split('(')[1].split(')')[0]
else:
like = '0'
# 头像地址
avatar = each.find_elements_by_xpath("./div[@class='head']/a/img")[0]
avatar = avatar.get_attribute('src')
data['userId'] = userId
data['nickname'] = nickname
data['content'] = content
data['like'] = like
data['avatar'] = avatar
print(data)
data_list.append(data)
data = {}
return data_list
def savef_data_to_mongo(data_list):
"""
一次性插入20条评论。
插入效率高,降低数据丢失风险
"""
data_list = str(data_list)
with open("网易评论.csv", "a", encoding='gbk') as file:
file.write(data_list)
print('成功插入', len(data_list), '条数据')
def go_nextpage(brower):
"""模拟人为操作,点击【下一页】"""
next_button = brower.find_elements_by_xpath("//div[@class='m-cmmt']/div[3]/div[1]/a")[-1]
if next_button.text == '下一页':
next_button.click()
if __name__ == '__main__':
id = '' # 用户ID
passwd = '' # 用户密码
login(id,passwd)
url = 'https://music.163.com/#/song?id=574566207'
start_spider(url)
最后
以上就是腼腆裙子最近收集整理的关于python3爬虫进阶之自动登录网易云音乐并爬取指定歌曲评论的全部内容,更多相关python3爬虫进阶之自动登录网易云音乐并爬取指定歌曲评论内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复