参考文章:http://stor.51cto.com/art/201808/582218.htm
选择合适的进程缓存
- ConcurrentHashMap,
- 比较适合缓存比较固定不变的元素,且缓存的数量较小的
- jdk自带的,使用方便
- 可以用来缓存反射的Method, Field等
- LRUMap
- 依赖common-collections包
- 淘汰算法淘汰数据
- Ehcache
- Guava Cache
- 本地缓存
- 轻量级的而且功能较为丰富
- 在不了解 Caffeine 的情况下可以选择
- Caffeine
- 命中率,读写性能上都比 Guava Cache 好很多
- API 和 Guava Cache 基本一致,甚至会多一点
总结:如果不需要淘汰算法则选择 ConcurrentHashMap;如果需要淘汰算法和一些丰富的 API,这里推荐选择 Caffeine
选择合适的分布式缓存
- redis
- memcache
多级缓存
一般来说我们选择一个进程缓存和一个分布式缓存来搭配做多级缓存,一般来说引入两个也足够了
如果使用三个,四个的话,技术维护成本会很高,反而有可能会得不偿失,如下图所示:
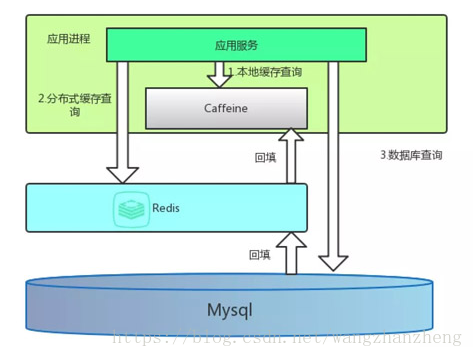
对于 Caffeine 的缓存,如果有数据更新,只能删除更新数据的那台机器上的缓存,其他机器只能通过超时来过期缓存,超时设定可以有两种策略:
- 设置成写入后多少时间后过期。
- 设置成写入后多少时间刷新。
为了解决进程内缓存的问题,设计进一步优化:
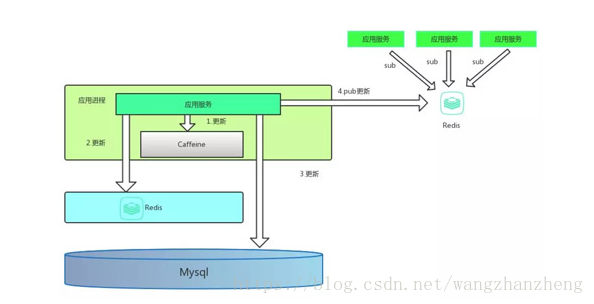
通过 Redis 的 Pub/Sub,可以通知其他进程缓存对此缓存进行删除。如果 Redis 挂了或者订阅机制不靠谱,依靠超时设定,依然可以做兜底处理。
缓存的三大坑
- 缓存穿透
- 缓存穿透是指查询的数据在数据库是没有的,那么在缓存中自然也没有,所以在缓存中查不到就会去数据库查询,这样的请求一多,我们数据库的压力自然会增大。
- 解决
- 对于返回为 NULL 的依然缓存,对于抛出异常的返回不进行缓存,注意不要把抛异常的也给缓存了
- 制定一些规则过滤一些不可能存在的数据,小数据用 BitMap,大数据可以用布隆过滤器
- 缓存击穿
- 对于某些 Key 设置了过期时间,但是它是热点数据,如果某个 Key 失效,可能大量的请求打过来,缓存未命中,然后去数据库访问,此时数据库访问量会急剧增加
- 解决
- 加分布式锁
- 异步加载,对这部分热点数据采取到期自动刷新的策略
- 缓存雪崩
- 缓存雪崩是指缓存不可用或者大量缓存由于超时时间相同在同一时间段失效,大量请求直接访问数据库,数据库压力过大导致系统雪崩。
- 解决
- 增加缓存系统可用性,通过监控关注缓存的健康程度,根据业务量适当的扩容缓存。
- 采用多级缓存,不同级别缓存设置的超时时间不同,即使某个级别缓存都过期,也有其他级别缓存兜底。
- 缓存的 Key 值可以取个随机值,比如以前是设置 10 分钟的超时时间,那每个 Key 都可以随机 8-13 分钟过期,尽量让不同 Key 的过期时间不同。
- 缓存污染
最后
以上就是甜甜小笼包最近收集整理的关于缓存系统的设计和问题选择合适的进程缓存选择合适的分布式缓存多级缓存的全部内容,更多相关缓存系统内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复