索引的优缺点
优点:索引可以大大提升查询的速度(最主要的原因)
缺点:(时间)牺牲增删改的速度,因为对表中数据进行增删改的时候,为了保证索引的有序性,需要动态的维护索引,会降低增/改/删的执行效率
(空间)创建索引需要占用硬盘(物理)空间
索引的增删改查
创建
1. 在create table 建表的时候添加索引
CREATE TABLE IF NOT EXISTS `user`(
id INT UNSIGNED PRIMARY KEY auto_increment COMMENT'主键ID',
username VARCHAR(32)UNIQUE NOT NULL COMMENT'用户名',2. 在create table 建表成功后,使用alter语句添加索引
ALTER TABLE 表名 ADD INDEX 索引名 (字段名);
注意:ALTER TABLE用来创建普通索引、UNIQUE(唯一)索引或PRIMARY KEY(主键)索引。
3. 在create table 建表成功后,使用create index 语句添加索引
CREATE INDEX 索引名 ON 表名 (字段名);
注意:CREATE INDEX可对表增加普通索引或UNIQUE索引。(但是,不能创建PRIMARY KEY索引)
创建索引时需要注意什么?
-
非空字段:应该指定列为NOT NULL,除非你想存储NULL。在mysql中,含有空值的列很难进行查询优化,因为它们使得索引、索引的统计信息以及比较运算更加复杂。你应该用0、一个特殊的值或者一个空串代替空值;
-
取值离散大的字段:(变量各个取值之间的差异程度)的列放到联合索引的前面,可以通过count()函数查看字段的差异值,返回值越大说明字段的唯一值越多字段的离散程度高;
-
索引字段越小越好:数据库的数据存储以页为单位一页存储的,数据越多一次IO操作获取的数据越大效率越高。
-
创建索引的原则
-
索引虽好,但也不是无限制的使用,最好符合一下几个原则
1) 最左前缀匹配原则,组合索引非常重要的原则,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
2)较频繁作为查询条件的字段才去创建索引
3)更新频繁字段不适合创建索引
4)若是不能有效区分数据的列不适合做索引列(如性别,男女未知,最多也就三种,区分度实在太低)
5)尽量的扩展索引,不要新建索引。比如表中已经有a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可。
6)定义有外键的数据列一定要建立索引。
7)对于那些查询中很少涉及的列,重复值比较多的列不要建立索引。
8)对于定义为text、image和bit的数据类型的列不要建立索引。
删除
1. 使用alter语句删除索引
alter table 表名 drop index 索引名;
2. 使用drop语句删除索引
drop index 索引名 on 表名
修改
先用删除索引的语句删除原来的索引,再用建表成功后的创建索引语句进行创建新的索引
查询
第一种:SHOW INDEX FROM 表名;
第二种:SHOW KEYS FROM 表名;
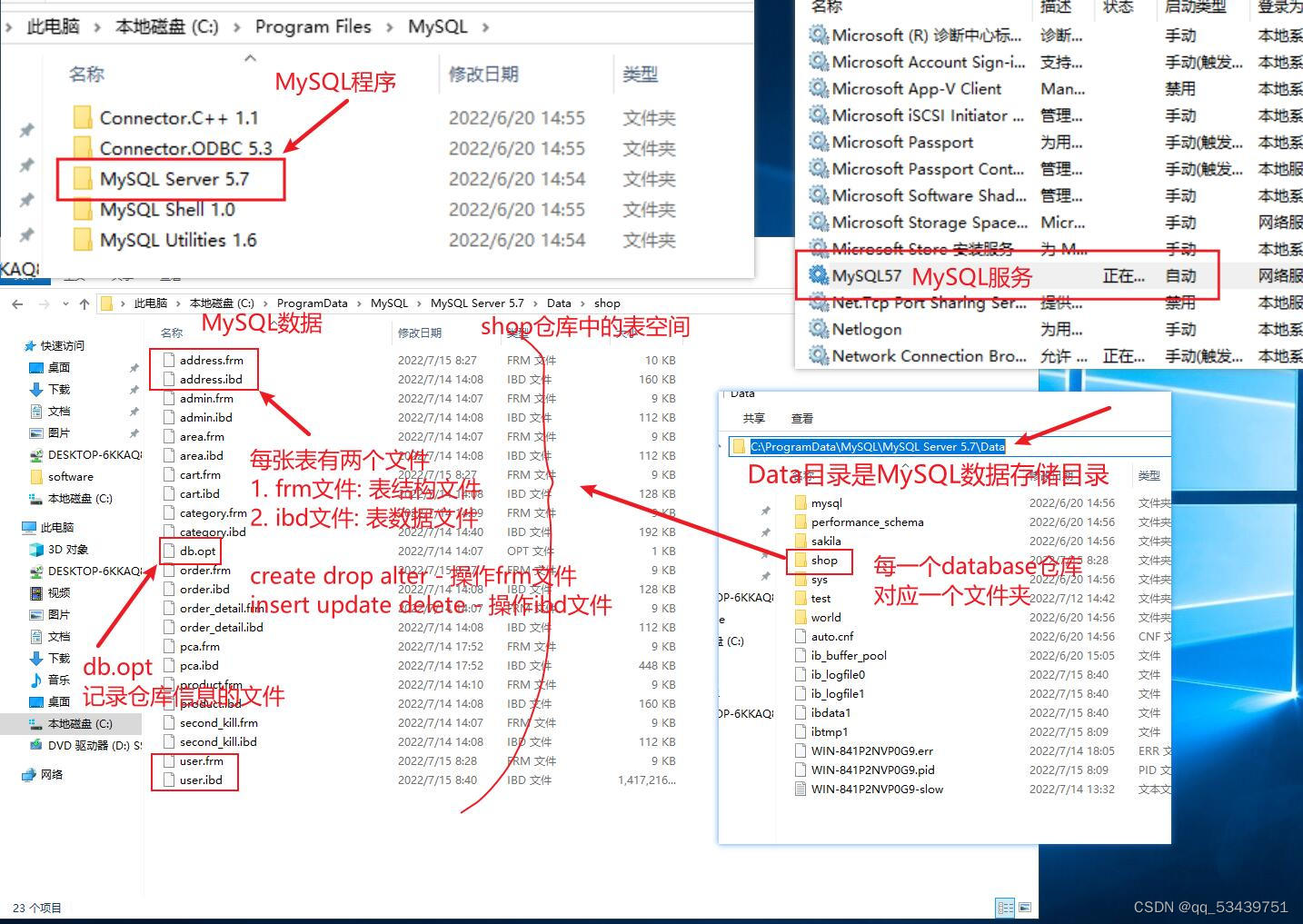
索引的分类
主键索引:关键字 primary key
唯一索引: 关键字 unique
普通索引(非唯一):关键字 index
全文索引:关键字 fulltext innoDB不支持全文索引 MyISAM支持

聚簇索引=主键索引=一级索引(表自带的)
非聚簇索引=(唯一索引,普通索引)=二级索引(自己手动创建)
除了主键索引是聚簇索引,其他所有使用非主键字段创建的索引都是非聚簇索引
(聚簇索引=主键索引都是表自带的,我们自己创建的都是非聚簇索引)
(如果表没有主键,那么会选择隐藏列 rowid 来创建聚簇索引。所以每一张表至少有一个索引叫做聚簇索引)
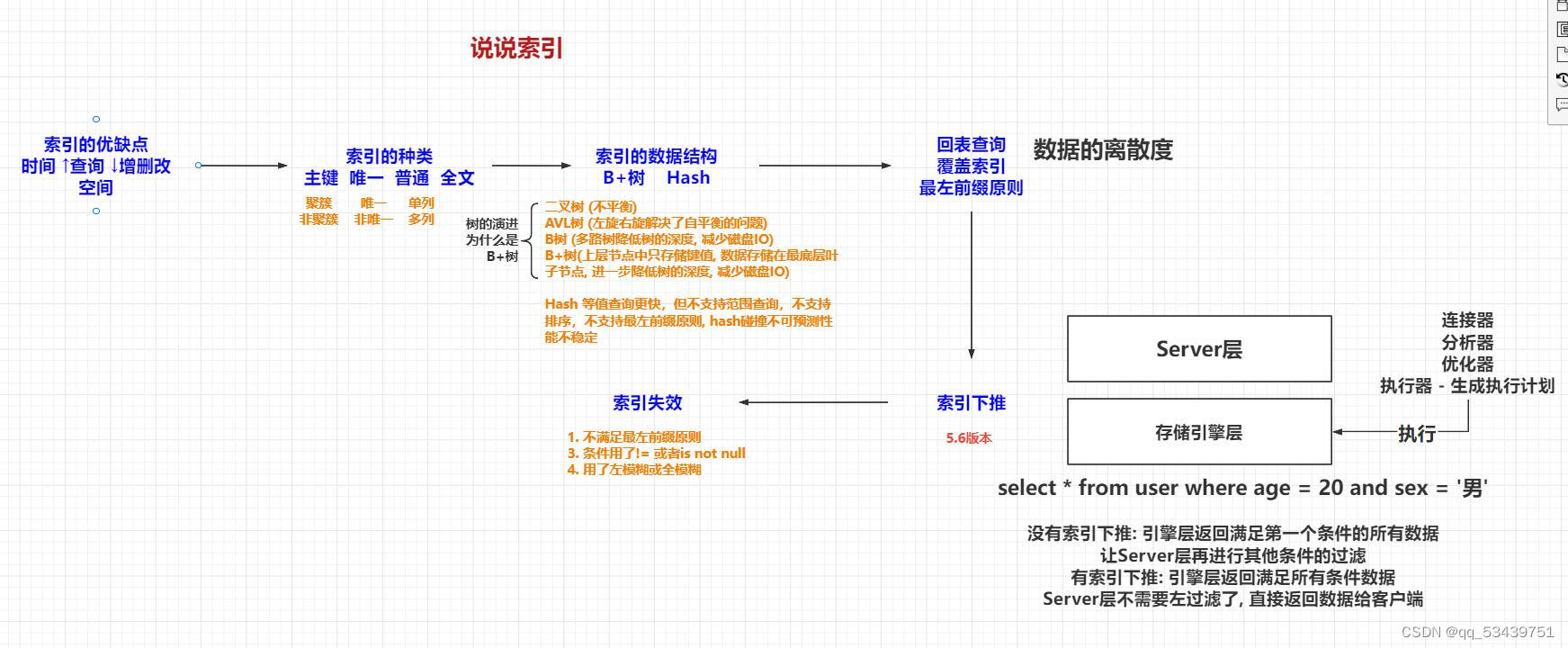
索引的数据结构
1.B+TREE B+树 结构索引(默认)
2. HASH 哈希结构的索引(不支持范围查询,只支持等值查询)
画图网站:Data Structure Visualization
数据结构的演进
1.二叉树:问题是无法自平衡
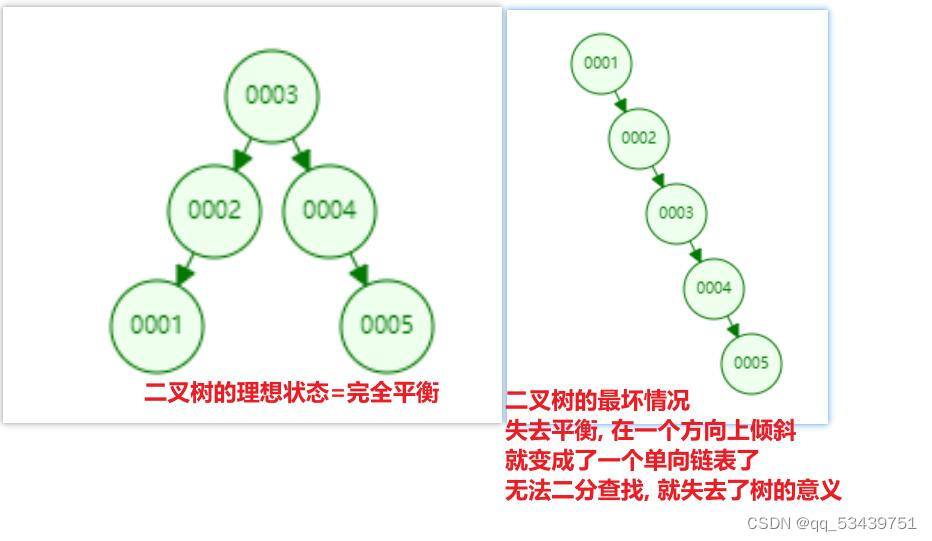
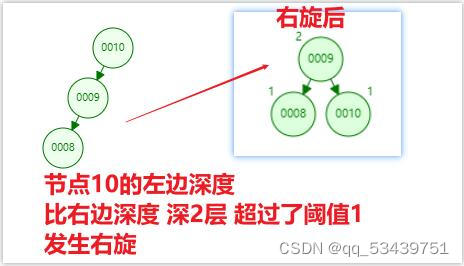
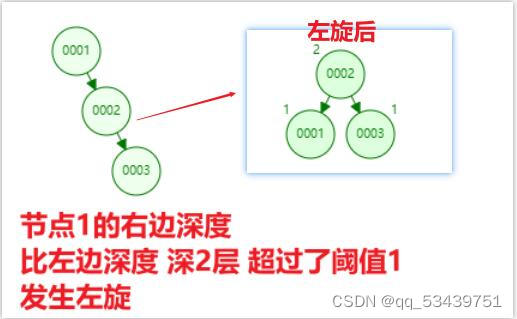
2.平衡二叉树 --AVL树
左旋算法:当右边的叶子节点深度 减 左边叶子节点的深度大于1时,会触发左旋
右旋算法:当左边的叶子节点深度 减 右边叶子节点的深度大于1时,会触发右旋
目的是维持树的平衡
3.多路平衡二叉树 --B 树
树的度数(Degree):树的每个节点中可以存储的元素个数
单路树:度数=1(一个节点只存一个元素,一个元素有左右指针);
多路树:度数=n(n>1)(一个节点能存多个元素,每个元素都有左右指针);
同等规模的数据,单路数是高瘦的,而多路树是矮胖的
多路树比单路树的优势在于 更少次数的磁盘IO就可以找到数据

MySQL是怎么设计索引的
树的每一个节点是一个磁盘块,MySQL将表ibd文件拆分为很多个磁盘块,每个磁盘块的大小统一是16KB(1000多个元素),每次磁盘IO都是读取一个磁盘块的数据
一个磁盘块的数据也称为一页数据
B-树升级为B+树
B树和B+树的区别
B树:
- 行数据data与主键存储在一起
B+树:
- 最底层的叶子节点组成一个单链表
- 部分元素做了冗余
- 只有最底层的叶子节点才存储data,上层节点只存主键id
- 走索引:从根节点开始遍历,二分查找,只需要少量的几次IO流就可以找到数据了
- 不走索引:从底层链表的第一个位置开始遍历,称为全表扫描
SELECT * FROM `user` WHERE id = 999999; -- 0.002s
SELECT * FROM `user` WHERE id_code = '320123199807134710'; -- 6.832s
B树 和B+树的区别


多路平衡二叉树 - B树
树的度数(Degree):树的每一节点中可以存储的元素的个数
单路树:度数是1(一个节点只存一个元素)
多路数:度数=n,n>1;(一个节点可以存储多个元素,每个元素都有左右指针)
同等规模的数据:
- 单路树是高瘦树
- 多路树是矮胖树
- 不同的是磁盘IO的次数,一次读一个节点
- 多路树比单路树的优点在于,更少次数的磁盘IO就可以找到数据
MySQL是怎么设计索引的?
树的每一个节点是一个磁盘块,MySQL将表ibd文件拆分为很多个磁盘块,每个磁盘块的大小统一是16KB(1000多个元素),每次磁盘IO都是读取一个磁盘块的数据
一个磁盘块的数据也称为一页数据
B-树升级为B+树
B树和B+树的区别
B树:
- 行数据data与主键存储在一起
B+树:
- 最底层的叶子节点组成一个单链表
- 部分元素做了冗余
- 只有最底层的叶子节点才存储data,上层节点只存主键id
- 走索引:从根节点开始遍历,二分查找,只需要少量的几次IO流就可以找到数据了
- 不走索引:从底层链表的第一个位置开始遍历,称为全表扫描
SELECT * FROM `user` WHERE id = 999999; -- 0.002s
SELECT * FROM `user` WHERE id_code = '320123199807134710'; -- 6.832s
添加索引
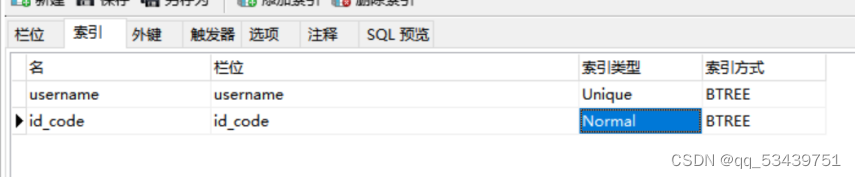
SELECT * FROM `user` WHERE id_code = '320123199807134710'; -- 0.003s
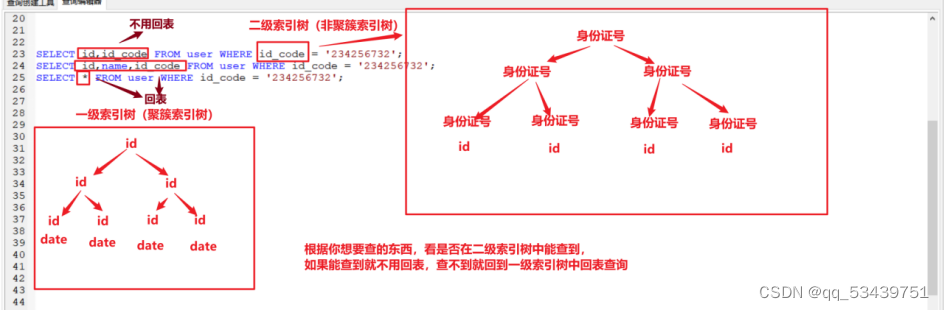
聚簇索引和非聚簇索引
除了主键索引是聚簇索引,其他所有使用非主键字段创建的索引都是非聚簇索引
聚簇索引底层叶子节点存储的date
非聚簇索引底层叶子节点存储是主键id,上层叶子节点里面存储的是按字符集排序的数据,根据非聚簇索引回到聚簇索引表里查询,称为回表查询
从非聚簇索引中的主键id去聚簇索引中查询,称为回表查询
设置索引的原则
根据数据的离散度来决定要不要设置为索引,离散度越低越适合设为索引,(10%~15%),最好的情况是唯一索引
联合索引
覆盖索引:建联合索引
把我们要查询的字段用同一个索引覆盖住
字段A和字段B 联合索引
最左前缀原则:
- A在左B在右
- A是完全有序
- B是不完全有序,只有在同一个A中,B才是完全有序
- 查询的时候按照最左边的字段去查找
优化LIMIT

最后
以上就是迷路钢笔最近收集整理的关于JAVA-DAY21(数据库中的索引)的全部内容,更多相关JAVA-DAY21(数据库中内容请搜索靠谱客的其他文章。








发表评论 取消回复