来源:https://my.oschina.net/liboware/blog/5076245
字符串拼接及创建的案例分析
案例一
String a = "test";
String b = "test";
System.out.println(a.equals(b)); // true
System.out.println(a == b); // true
System.out.println(System.identityHashCode(a)); // 1639705018
System.out.println(System.identityHashCode(b)); // 1639705018
当a初始化时,"test"对象被加入字符串常量池,b初始化时,检查到"test"对象在字符串常量池中,则直接指向该对象;
a.equals(b)比较的是对象持有的内容,显然为true,a==b比较的是是否指向的是同一对象,因为指向的同为字符串常量池中"test"对象,结果为true;
System.identityHashCode方法的返回值为参数对象object中hashCode()的返回值,无论hashCode()方法是否被覆盖。
案例二
String a = "test";
String b = new String("test");
System.out.println(a.equals(b)); // true
System.out.println(a == b); // false
System.out.println(System.identityHashCode(a)); // 1639705018
System.out.println(System.identityHashCode(b)); // 1627674070
当a初始化时,"test"对象被加入字符串常量池,b初始化时,首先检查到"test"对象在字符串常量池中,无需在字符串常量池中创建对象,然后在堆中创建"test"对象,b指向堆中"test"对象;
可得a.equals(b)为true,a==b为false
案例三
String a = new String("test");
String b = new String("test");
System.out.println(a.equals(b)); // true
System.out.println(a == b); // false
System.out.println(System.identityHashCode(a)); // 1639705018
System.out.println(System.identityHashCode(b)); // 1627674070
当a初始化时,"test"对象被加入字符串常量池,然后在堆中创建"test"对象,a指向堆中"test"对象;
b初始化同a,但是不像字符串常量池中那样,虽然a与b的内容相同,但是依然会在堆上创建两个对象;
所以a.equals(b)为true,a==b为false
案例四
String a = "test";
String b = "te"+"st";
System.out.println(a.equals(b)); // true
System.out.println(a == b); // true
System.out.println(System.identityHashCode(a)); // 1639705018
System.out.println(System.identityHashCode(b)); // 1639705018
与案例一不同的是,b的值由两个引号相加所得,但是结果和案例一是一样的,a与b指向的都是字符串常量池中的同一对象,这是因为形如"te"+"st"这种由多个字符串常量连接而成的字符串在编译期被认为是一个字符串常量
案例五
String a = new String("test");
String b = new String("te") + new String("st");
System.out.println(a.equals(b)); // true
System.out.println(a == b); // false
System.out.println(System.identityHashCode(a)); // 1639705018
System.out.println(System.identityHashCode(b)); // 1627674070
根据案例三中的分析可知,a与b内容时一致的,但是指向的不是同一对象,但是问题是这个案例中会在字符串常量池中创建多少个对象?
答案应该是三个:"test"、"te"、"st";在堆上会创建多少个对象?答案是四个:a指向的"test"对象,两个匿名对象"te"、"st",b指向的"test"对象
案例六
String a = "test";
String b = "te";
String c = "st";
String d = b + c;
System.out.println(a.equals(d)); // true
System.out.println(a == d); // false
System.out.println(System.identityHashCode(a)); // 1639705018
System.out.println(System.identityHashCode(d)); // 1627674070
对象d的初始化方式似乎跳出了之前所说的两种初始化方式,是由两个存在于字符串常量池中的字符串对象连接生成,但其实此时的d的初始化方式只是复杂了一些,并没有脱离之前所说的两种初始化方式,具体步骤如下:
b、c已经存放在字符串常量池中,将b、c对象复制到堆中;
在堆中新建d对象,并将b、c连接后的值赋给d;
也就是说在这个案例中字符串常量池中创建了三个对象,堆中创建了三个对象
案例七
String a = "test";
final String b = "te";
final String c = "st";
String d = b + c;
System.out.println(a.equals(d)); // true
System.out.println(a == d); // true
System.out.println(System.identityHashCode(a)); // 1639705018
System.out.println(System.identityHashCode(d)); // 1639705018
与案例六不同的是b、c都加了final修饰,在这种情况下,与案例四一样,编译器将b+c视为了字符串常量,所以d指向的是在字符串常量池中已存在的"test"对象
总结
可以看出不同情况下的String对象初始化,的确会直接影响jvm对于对象的创建以及创建位置,这验证了在之前的结论
若编译期String对象的内容可确定(案例四、案例七),初始化方式任被认为是字面量初始化。
String、StringBuilder、StringBuffer
String是不可变字符串,所有的change操作都会创建新对象,StringBuilder与StringBuffer都是可变字符串(字符数组长度可变)
StringBuilder与StringBuffer在实现上基本完全一致,但是StringBuffer中的大部分方法都使用了synchronized进行修饰
String和StringBuffer是线程安全的,StringBuilder不是,因为String是不可变的,显然安全,而StringBuffer中的方法大都采用了synchronized 关键字进行修饰,因此也是线程安全的
通常情况下执行效率StringBuilder > StringBuffer > String,但不是绝对的,具体情况具体分析
当字符串基本不改动或改动很少时使用String
频繁改动使用StringBuilder,
频繁改动且涉及多线程,则使用StringBuffer使用
+号连接字符串的操作是通过StringBuilder的append和toString方法实现的
垃圾收集
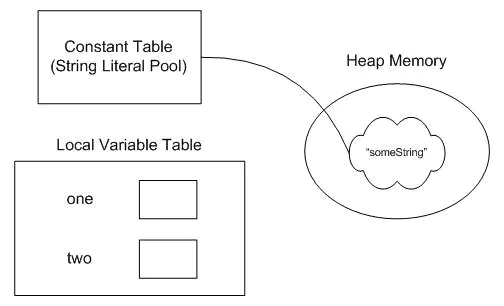
当一个对象没有引用指向时,垃圾收集器便会对它进行收集操作。看下面的一个事例:
public class ImmutableStrings
{
public static void main(String[] args) {
String one = "someString";
String two = new String("someString");
one = two = null;
}
}
当 one = two = null时,只有一个对象会被回收,String对象总是有来自字符串常量池的引用,所以不会被回收
大家可能都知道String.intern()的作用,调用它时,如果常量池中存在当前字符串, 就会直接返回当前字符串. 如果常量池中没有此字符串, 会将此字符串放入常量池中后, 再返回。 但是一些稍复杂的例子,可能就说不清它的运行结果,而且这结果跟jdk版本有关。本篇通过理论和例子让你对String.intern()的有更深入的理解,以及其中的原理。这不仅仅是笔试面试中常考得点,也是对技术深入探究的态度。
intern方法
常量池
Class文件中除了有关的版本、字段、方法、接口等描述信息外,还有一项信息是常量池,用于存放编译期生成的各种字面量和符号引用。其中字符串池(又名字符串规范化)是一个用一个共享的String替换几个具有相同值但不同身份的对象。你可以通过Map来自己实现此目标(根据要求可能有软或弱引用),或者可以使用String.intern()由JDK提供的方法。
Java 6中的String.intern()
Java 6以及6之前中常量池存放在方法区(Perm 区)中,过多的使用intern()会直接产生java.lang.OutOfMemoryError: PermGen space错误的。
因为方法区具有固定大小,不能在运行时扩展。虽然可以使用-XX:MaxPermSize=N选项进行设置,根据平台的不同,默认的PermGen大小在32M到96M之间变化。
你可以增加它的大小,但它的大小仍然是固定的,这种限制使得不能不受控制的使用String.intern()。这就是Java 6时代的字符串池主要在手动管理的Map中实现的原因。
Java 7中的String.intern()
Oracle对Java 7中的常量池做了一个非常重要的改变 — z字符串常量池被重新定位到堆中。 这意味着你不再受限于单独的固定大小内存区域。所有字符串现在都位于堆中,与大多数其他普通对象一样,这使你可以在调整应用程序时仅管理堆大小。从技术上讲,这仅仅是一个使用String.intern()的理由。但还有其他原因。
常量池中的GC,如果常量不再被引用,那么JVM是可以回收它们来节省内存,因此常量池放在堆区可以更方便和堆区的其他对象一起被JVM进行垃圾收集管理。
在之前的结论中,可以看到String对象被加入进字符串常量池中的条件似乎是必须在编译器可表示为字符串常量,而在运行期间确定的字符串对象时无法加入的,但是也不是绝对的,String类中提供的intern方法就是一种在运行期间加入字符串常量池的一种方法。
当调用intern方法时,如果字符串常量池中已经包含一个内容相同的String对象,则返回池中的对象。否则,将在字符串常量池中添加一个该对象在堆中引用地址,并返回该对象地址值(在jdk6中,是直接将此String对象添加到池中,并返回此String对象)。
如以下案例
String a = "test";
System.out.println(System.identityHashCode(a)); // 1639705018
a = a.intern();
System.out.println(System.identityHashCode(a)); // 1639705018
此时a初始化完成后指向的对象的位置是在字符串常量池中,执行a = a.intern()后,指向位置任是在字符串常量池中;所以看到打印的hashcode是一样的;
String a = new String("test");
System.out.println(System.identityHashCode(a)); // 1639705018
a = a.intern();
System.out.println(System.identityHashCode(a)); // 1627674070
此时a初始化完成后指向的对象的位置是在堆上的,同时在字符串常量池中有一个相同内容的String对象,执行a = a.intern()后,指向位置是在字符串常量池中;
String a = new String("te") + new String("st");
System.out.println(System.identityHashCode(a)); // 1639705018
a = a.intern();
System.out.println(System.identityHashCode(a)); // 1639705018
此时a初始化完成后指向的对象的位置是在堆上的,字符串常量池中没有相同内容的String对象(这里指的是test),执行a = a.intern()后
字符串常量池中增加一个引用,该引用指向堆上的String对象,所以a依然指向的是堆上的String对象,执行前后,hashcode没有变化;(如果在jdk6 执行此代码,获得结果是不一样的-分别是用字符串常量池的地址与堆得地址做比较)
String的创建及拼接
String的创建
字符串不属于基本类型,但是可以像基本类型一样,直接通过字面量赋值,当然也可以通过new来生成一个字符串对象。不过通过字面量赋值的方式和new的方式生成字符串有本质的区别:
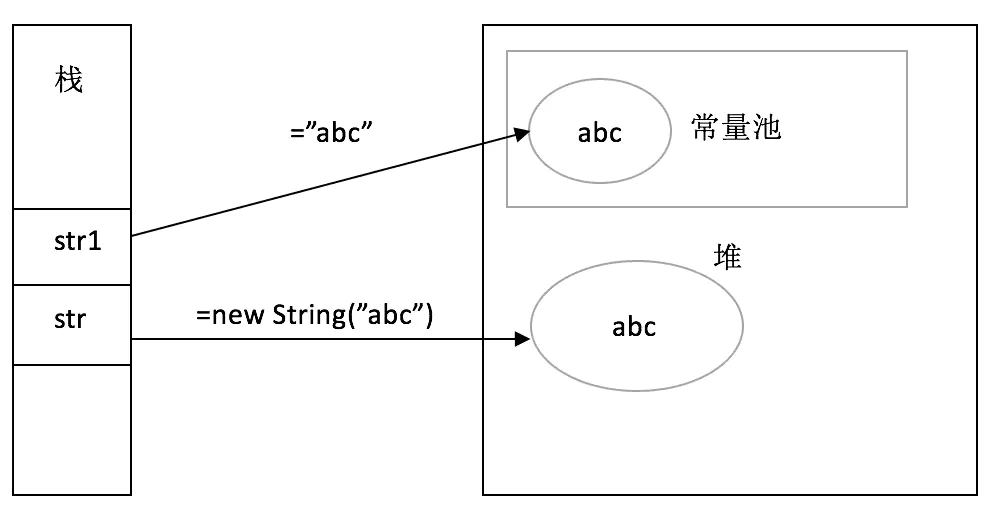
通过字面量赋值创建字符串时,会先在字符串常量池中查找是否已经存在相同的字符串,倘若已经存在,栈中的引用直接指向该字符串;倘若不存在,则在字符串常量池中生成一个字符串,再将栈中的引用指向该字符串。
通过new的方式创建字符串时,就直接在堆中生成一个字符串的对象,栈中的引用指向该对象。
String的拼接
直接多个字符串字面量值“+”操作,编译阶段直接会合成为一个字符串。
//等价于直接赋值"hello world"
String s = "hello "+"world";
变量进行字符串拼接的方式
String s1="world";
String s = "hello "+s1;
通过反编译可知以上代码相当于
String s1="world";
StringBuilder sb=new StringBuilder("hello");
sb.append(s1);
String s = sb.toString();
实际上是先创建StringBuilder,然后使用append()拼接,最后toString()赋值给s
变量采用final进行修饰
final String s1="world";
String s = "hello "+s1;
将s1用final修饰,则拼接也是在编译时完成,编译时会先把用常量值替换s1,再就是和第一种情况相同
String s=new String("hello ") + new String("world");
这种也是用StringBuilder拼接
public class StringTest01 {
public static void main(String[] args) {
String baseStr = "baseStr";
final String baseFinalStr = "baseStr";
String str1 = "baseStr01";
String str2 = "baseStr"+"01";
String str3 = baseStr + "01";
String str4 = baseFinalStr+"01";
String str5 = new String("baseStr01").intern();
System.out.println(str1 == str2);
System.out.println(str1 == str3);
System.out.println(str1 == str4);
System.out.println(str1 == str5);
}
}
按顺序依次讲解:
上面字符串拼接说了,str2也相当于直接用"baseStr01"赋值,str1==str2 肯定会返回true,因为str1和str2都指向常量池中的同一引用地址。
str3由非常量baseStr 拼接,实际上是stringBuilder.append()生成的结果,所以与str1不相等,结果返回false。
str4由常量baseFinalStr 拼接,在编译时就进行了替换,等同于字面量赋值,所以为true。
在常量池中已经有"baseStr01"字符串,str5和str1都引用它,所以返回true。
public class InternTest {
public static void main(String[] args) {
String str2 = new String("str")+new String("01");
str2.intern();
String str1 = "str01";
System.out.println(str2==str1);
}
}
在java 1.6运行结果:false 在java 1.7以及之后运行结果:true
因为str2和str1分别指向堆中对象和常量池中字符串,所以返回false。
为什么java 1.7后,结果为true呢,这就跟上面说的常量池被移到堆中有关了,intern()在实现上发生了比较大的改变,还是会先去查询常量池中是否有已经存在,如果存在,则返回常量池中的引用,这一点与之前没有区别
区别在于,如果在常量池找不到对应的字符串,则不会再将字符串拷贝到常量池,而只是在常量池中生成一个对原字符串的引用。
所以,str2.intern();这句话不是没任何影响的,它会在常量池中生成一个对堆中的“str01”的引用,而在进行字面量赋值的时候,常量池中已经存在,所以直接返回该引用即可,因此str1和str2都指向堆中的字符串,返回true。
public class InternTest01 {
public static void main(String[] args) {
String str1 = "str01";
String str2 = new String("str")+new String("01");
str2.intern();
System.out.println(str2 == str1);
}
}
将str1的定义放在前面,则java 1.6,1.7都返回false
因为这次str2.intern();执行时,常量池中已经有了"str01", 因此str1和str2引用不同。
String对象的创建和字符串常量池的放入
那到底什么时候会创建String 对象?什么时候引用放入到字符串常量池中呢?先需要提出三个常量池的概念:
静态常量池
常量池表(Constant Pool table,存放在Class文件中),也可称作为静态常量池,里面存放编译器生成的各种字面量和符号引用。
其中有两个重要的常量类型为CONSTANT_String_info和CONSTANT_Utf8_info类型
运行时常量池
运行时常量池属于方法区的一部分,常量池表中的内容会在类加载时存放在方法区的运行时常量池,运行时常量池相比于Class文件常量池一个重要特征是动态性,运行期间也可以将新的常量放入到 运行时常量池中。
字符串常量池
在HotSpot 虚拟机中,使用StringTable来存储String对象的引用,即来实现字符串常量池,StringTable 本质上是HashSet,所以里面的内容是不可以重复的。
一般来说,说一个字符串存储到了字符串常量池也就是说在StringTable中保存了对这个String对象的引用
执行过程
首先给出结论,"在类的解析阶段,虚拟机便会在创建String对象,并把String对象的引用存储到字符串常量池中"。
当.java 文件 编译为class文件时,字符串会像其他常量一样存储到class文件中的常量池表中,对应于CONSTANT_String_info和CONSTANT_Utf8_info类型
类加载时,会把静态常量池中的内容存放到方法区中的运行时常量池中,其中CONSTANT_Utf8_info类型在类加载的时候就会全部被创建出来,即说明了加载类的时候,那些字符串字面量会进入到当前类的运行时常量池,但是此时StringTable(字符串常量池)并没有相应的引用,在堆中也没有相应的对象产生;(No initialization)
遇到ldc字节码指令(该指令将int、float或String型常量值从常量池中推送至栈顶)之前会触发解析阶段,进入到解析阶段,若在解析的过程中发现StringTable已经有与CONSTANT_String_info一样的引用,则返回该引用,若没有,则在堆中创建一个对应内容的String对象,并在StringTable中保存创建的对象的引用,然后返回;
下面给出几个具体实例,来说下这个过程:
// 字面量的形式创建字符串
public class test{
public static void main(String[] args){
String name = "HB";
String name2 = "HB";
}
}
通过javap 反编译后的字节码代码如下所示
# 2 = String #14
#14 = utf8 HB
……
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=1, locals=3, args_size=1
0: ldc #2 // String HB
2: astore_1
3: ldc #2 // String HB
5: astore_2
6: return
……
当编译成字节码文件后,字面量"HB" 会存储到常量类型CONSTANT_Utf8_info的class静态常量池中
类加载时,其也会随之加载到方法区中的运行时常量池中,接下来可以用此来在StringTable查询是否有匹配的String对象引用(当然只是简化的说法,具体CONSTANT_Utf8_info还指向一个Symbol对象);
遇到第一个ldc字节码指令之前,解析过程中发现StringTable(字符串常量池)还没有与CONSTANT_String_info一样的引用,则在堆中创建一个对应内容的String对象,并在StringTable中保存创建的对象的引用,然后返回;
astore_1指令把返回的引用存到本地变量name
遇到二个ldc字节码指令之前,解析过程中发现StringTable(字符串常量池)已经有与CONSTANT_String_info一样的引用,则直接返回即可。
并通过astore_2 指令将其返回的引用保存到本地变量 name2中
new 创建字符串
public class test2{
public static void main(String[] args){
String name = new String("HB");
String name2 = new String("HB");
}
}
通过javap 反编译后的字节码代码如下所示
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=3, locals=3, args_size=1
0: new #2 // class java/lang/String
3: dup
4: ldc #3 // String HB
6: invokespecial #4 // Method java/lang/String."<init>":(Ljava/lang/String;)V
9: astore_1
10: new #2 // class java/lang/String
13: dup
14: ldc #3 // String HB
16: invokespecial #4 // Method java/lang/String."<init>":(Ljava/lang/String;)V
19: astore_2
20: return
使用了关键字new后,会有稍微不同,new指令会在堆中创建一个新的String对象,并将其引用值压入栈顶,通过dup指令复制栈顶的新对象的引用值并把复制值压入栈顶,本地变量name所保存的值就为该引用值;
接下来在遇到第一个ldc字节码指令之前,解析过程中发现StringTable(字符串常量池)还没有与CONSTANT_String_info一样的引用,则在堆中创建一个对应内容的String对象,并在StringTable中保存创建的对象的引用, 所以在运行时,会创建两个String对象哦。
最后
以上就是呆萌烤鸡最近收集整理的关于带你进入String类的易错点和底层本质分析!的全部内容,更多相关带你进入String类内容请搜索靠谱客的其他文章。








发表评论 取消回复