在现代的软件系统中,几乎所有的系统都使用到了数据库,不论是关系型数据,例如MySql、SQLite、Oracle、SQLServer等,还是非关系性数据,例如mongoDB、redis等。本文已web系统为例来阐述为什么要降低数据库的压力,在提出具体方案之前先大致讲解一下现在web系统的架构,要了解web系统的架构和演变过程具体可以参考大型网站架构演变和知识体系这片文章。
现代web系统的架构
现在的大型web系统多采用分布式的架构,分布式系统面临的最大挑战就是如何在复杂的、并发的情况下保证数据的一致性问题。通常为了避免由于保证数据一致性问题而带来的困难,通常情况下都是采用多个实例,单个数据源的架构模式,简化模式如图。
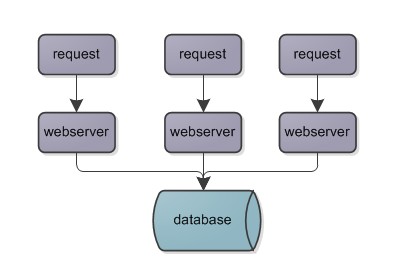
在这个架构中,通过不断的增加实例(webserver)可以降低应用服务器的压力,所以只要保证应用代码的质量、应用之间的低耦合性、可扩展性和可维护性等,应用服务器的压力就不再会成为整体架构中性能瓶颈,但是随着业务量的不断增加增长,或者时间的积累,沉淀下来的数据变得越来越来多,随着而来的数据库的压力变得越来越大,慢慢的性能的瓶颈主要集中在数据库上。
降低数据库压力的方法
1.合理增加索引
表索引可以加快对表中数据的检索速度,但是会降低表中数据的更新速度,所以增加表的索引一定控制在合理范围内,过多的索引不但不会降低数据库的压力,反而可能增大数据库的压力,表索引的建立一般要从具体业务场景出发,对于读多写少的场景,可以通过适当的增加索引来提高效率,对表的那些列建立索引?建立单独索引还是建立复合索引?要根据具体的业务场景来决定,建立索引之后可以针对索引对业务逻辑中使用的SQL进行优化,建立索引是最基础的手段,这里不错过多的介绍。
2.数据截转
一般情况下,业务中所处理的数据的都具有一定的时间间隔,所以可以通过对业务进行梳理,将当前时间间隔之外的数据进行截转,截转到历史数据库中,通过对业务进行拆分,当需要历史数据时,可以转到历史数据库中进行查询,或者修改,通过减少当前数据库的数据量,来减轻当前业务数据的压力。数据截转一般情况下是按照时间来进行,所以在业务员数据库设计的时候就要考虑到时间这个因素。
数据截转可以进行间隔一段时间做一次手工的数据截转,也可以启动一个定时器,每个一段时间进行一次数据截转,推荐的方式是准实时截转,及每天在业务量较小的时间,启动任务实时截转。
数据截转需要注意的几个问题:(1)外键关联关系(特别是有主键ID的关联的)注意在截转的历史数据库中的关联关系是否正确。(2)保证生产库和历史库的业务关联关系,从而避免历史库的数据需要关联生产库中的数据。
3.增加缓存
缓存是降低数据压力一个强有力的手段,基本是所有系统大型web系统中都会使用到,所以现代的大型web系统的架构一般如图。
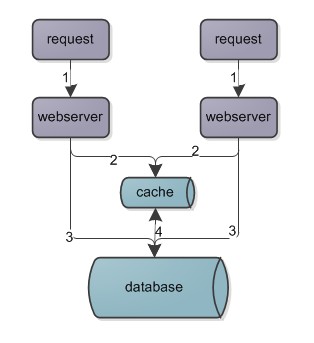
请求1到达webserver之后,首先执行2访问缓存,如果hit则返回,miss则执行3访问数据库,在执行4同步到缓存中,再返回。但是不是缓存并不是万能的,缓存也有其使用的业务场景,一般在读多写少,数据重复查询比较集中的场景下,缓存可以大大提高性能,缓存操作顺序非常重要,不合理的操作顺序,在并发场景下常常会导致数据的不一致,缓存的具体操作可以参考缓存架构设计细节二三事这边文章。
4.生成宽表,冗余数据
有些业务例如报表、数据汇总等需要数据量较多,此时可能需要进行多表联合查询,联合查询操作非常消耗数据库的性能,所以在这种业务场景下为了避免过大的性能消耗,往往需要将查询时的多个表按照关联条件进行关联,生成一张含有冗余信息的包含所有表的多个字段的大宽表,这样在进行查询时,只在一张表中进行查询,性能明显得到提升。大宽表的生成是在业务流程中生成还是通过异步化任务来生成,根据具体的业务逻辑来定。
5.修改关系型数据库为非关系性数据库
非关系型数据库,也就是我们通常说的NoSQL数据,最常见就是key/value类型的数据库,这类数据库不强调表的关系,但是查询速度非常快,所在某些具体场景下,我们应该优先选择NoSQL数据库,例如字典信息表的查询。
6.读写分离
如果采用单点数据数据库,就算对数据进行上述的相关优化,但是由于其本身的单点性,所以随着流量的激增,数据库仍然会成为系统的瓶颈,如何对数据进行拆分来解决这个问题了,读写分离就是最常用的方法,读写分离的原理如下图。
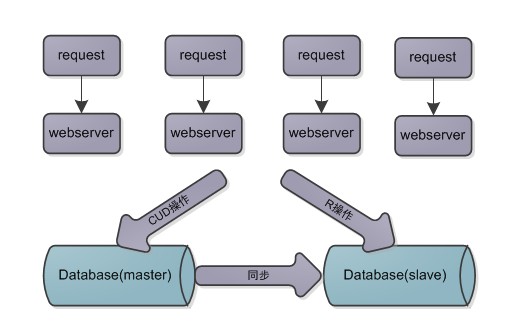
读写分离技术现在已经应用的很成熟,通过将数据拆分为两个实例,读写分离操作改善了数据单点的瓶颈,分摊了数据库压力,而且当主数据库宕机之后可以迅速的切换到从库,而不会导致业务不可用,同时也起到数据备份的作用,由于存在两个数据实例,所以数据怎么由主库同步到从库、主从之间延迟引发的数据不一致问题,以及怎么来分离业务中读和写操作成为要解决的问题成为要解决的问题。主从同步可以参考Mysql主从架构的复制原理及配置这篇文章,从主数据一致可以参考DB主从一致性的几种解决方法这篇文章。
7.数据库拆分
采用读写分离之后,数据库已经变为两份实例,数据库的压力已经得到分摊,如果数据库的压力还是过大时,这是就要从业务方面着手,将具体业务细分,将业务对应的表分拆到不同的数据库当中,如下图。
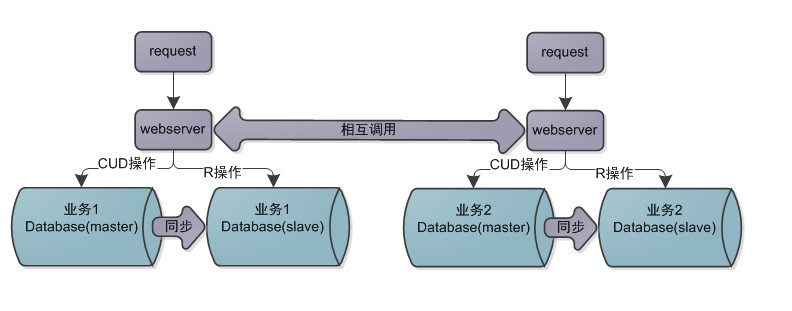
业务变动较大,同时要对系统内部之间的相互调用提供接口,调用方式可以选用RPC、Restful、JMQ消息等方式。一般情况下,数据库垂直拆分做的足够细分的话,加上读写分离技术,加上适当的数据截转就可以满足一般的大型业务系统对性能的需求。
8.表的垂直拆分
数据库可以进行垂直拆分,当然也可以对数据库中的表进行垂直拆分,对表进行拆分就是对数据拆分的再拆分,如图。种解决方法只适用于一些特定的场景,例如对表进行垂直拆分,通过异步化调用将所有任务异步化,前提是总的任务可以进行分布的异步化操作,在实际应用比较少,因为设计的表只要复合三范式的要求,一般是很难在进行拆分的,应用较多是对表进行水平拆分。
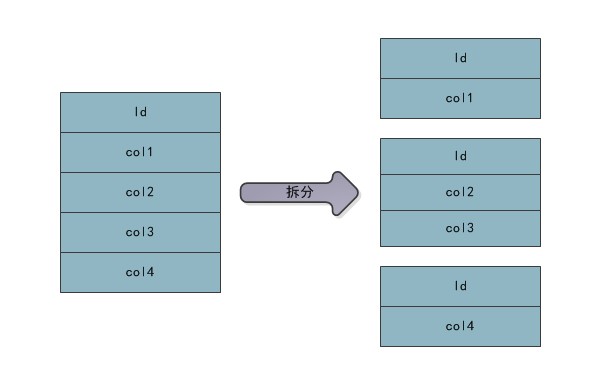
9.表的水平拆分
如果已经做了数据库拆分,并且进行了读写分离,数据压力还是过大,主要原因就是数据库表中的记录太多,或者对数据进行了截转,但是对历史数据的操作还是比较频繁的,且随着截转的历史数据越来越多,历史数据库的压力也边的也变的越来越大,这时有两种解决方案:第一种方案就是对数据库中的表进行垂直拆分,从而不用在截转数据,通过不断对表进行水平拆分,保证数据数据库中单表的记录数保持在一个高性能合理的范围之类,通过扩容将不同分配到不同的数据中(分库分表)来保证数据库的压力,应用在访问时,通过分库分表的条件进行路由,就可以取到数据。第二种就是仍旧对数据进行截转,当历史数据信息过多从而导致数据库压力过大时,采用搜索引擎的方式来解决。相比于第一种操作第二种方案适用于读操作上,对与写操作,具有一定的局限性,第一种方案具有一定的通用性。对表进行水平拆分的过程如图所示。
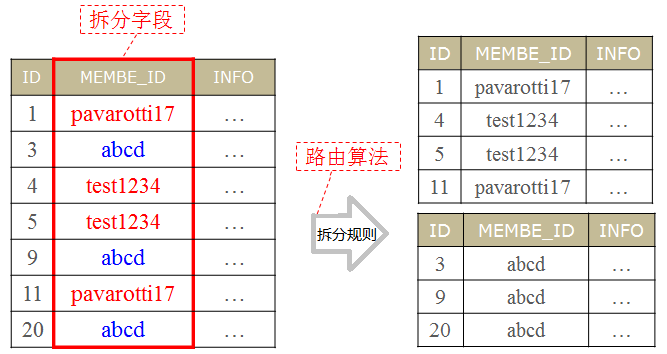
在进行进行具体水平拆分之前,我们需要考虑这样几个问题
- 制定什么样的路由规则
- 如何尽量避免跨库或者跨表操作
- 如何尽可能的避免全库全表扫描
- 如何保证每个库的负载处于基本尽可能均衡的状态
- 如何实时跨库访问事物
- 如何实时聚合操作
- 如何保证扩容的方便性
1. 制定什么样的路由规则
2. 如何尽量避免跨库或者跨表操作
3. 如何尽可能的避免全库全表扫描
4. 如何保证每个库的负载处于基本尽可能均衡的状态
5. 如何实时跨库访问事物
6. 如何实时聚合操作
7. 如何保证扩容的方便性
最后
以上就是快乐睫毛最近收集整理的关于降低数据压力的几种解决方案现代web系统的架构降低数据库压力的方法的全部内容,更多相关降低数据压力内容请搜索靠谱客的其他文章。


![我们的网站压力究竟在哪里[转]](https://www.shuijiaxian.com/files_image/reation/bcimg15.png)





发表评论 取消回复