【文献翻译】Functional Dependency Discovery:An Experimental Evaluation of Seven Algorithms
- 摘要
- 1. 函数依赖关系
- 2. FD算法概述
- 2.1 准备工作
- 2.2 分类
- 2.3 其他算法
- 3. 七种FD发现算法
- 3.1 TANE
- 3.2 FUN
- 3.3 FD Mine
- 3.4 DFD
- 3.5 Dep-Miner
- 3.6 FastFDs
- 3.7 FDEP
- 4. 评价
- 4.1 实验装置
- 4.2 行可扩展性实验
- 4.3 列可扩展性实验
- 4.4 对不同数据集的实验
- 4.5 内存实验
- 4.6 实验结果外推
- 5. 总结
摘要
1. 函数依赖关系
所有算法的目标相同,即发现给定数据集中所有最小的、非平凡的函数依赖关系。
分析:怎么理解最小,非平凡
贡献:我们按其主要概念对七种FD算法进行了分类,并对最新的发展进行了概述。我们重新审视所有的算法,并为它们的实际实现提供额外的描述,因为它们的原始出版物很少。我们比较了不同数据集的算法,并评估运行时和内存使用情况。从我们的实验结果,我们得出了具体的建议,何时使用哪种算法。我们还将所有实施、数据和评估框架在线提供
结构:第2节给出了FD发现的概述,讨论了常见概念、替代方法以及我们对发现算法的分类。第3节描述了算法的实现。第4节给出了我们的评估结果,第5节总结了每种发现算法的优缺点
2. FD算法概述
2.1 准备工作
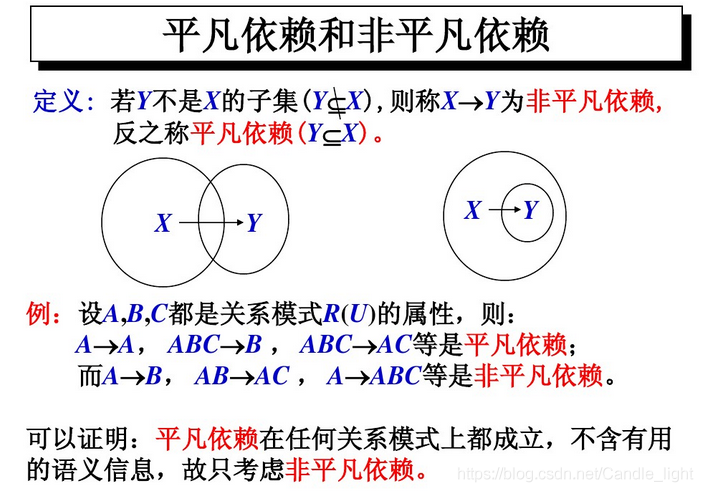
FD的定义:X->A ;如果X的子集并不确定A,则函数依赖性X→A是最小的。如果A不是X的子集,则它是非平凡的。为了发现数据集中的所有函数依赖性,只要发现所有最小的、非平凡的FDs就足够了,因为所有的左侧(lhs)子集都是非依赖性的,而所有的左侧(lhs)超集都是逻辑推理的依赖性。
子集和超集:
2.2 分类
为了更好地理解这七种函数依赖性发现算法及其性质,我们将它们分为三类。第3节以下是对每种算法的详细讨论。
2.3 其他算法
3. 七种FD发现算法
3.1 TANE
有参考资料
基于三个概念:
- 分区细分(partition refinement)检查函数依赖是否成立
- 先验-基因(apriori-gen)确保找到所有且只有最小的函数依赖被发现
- 剪枝规则(pruning rules)动态缩小搜索空间
与所有的格遍历算法一样,TANE将搜索空间建模为Hasse图,如第2.1节所述。
2.1节讲了什么
图1描述了关系式r ={A,B,C}的Hasse图。
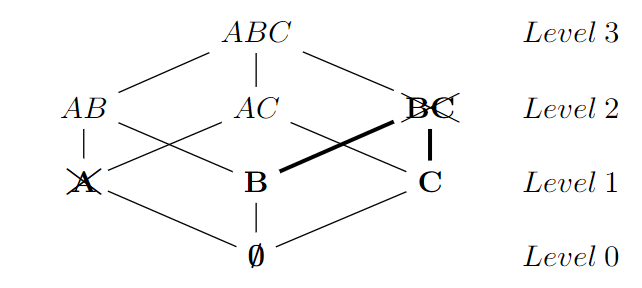
晶格被划分为级别,其中Li级别包含大小为i的所有属性组合。TANE没有开始计算整个晶格,而是从第1级(大小为1 属性集)开始,然后逐级向上移动(示例中的粗体)。
In each level Li, the algorithm tests all attribute combinations X ∈ Li for the functional dependency X A → A for all A ∈ X.
X A表示差集
在每一级别中Li中算法对X∈Li的所有的属性组合进行测试,进行函数依赖X A→A的测试
如果一个测试交付一个新的函数依赖项,那么 Tane 会使用一组剪枝规则修正所有已发现 FD 的超集。当向上移动到下一个级别时,apriorigen 函数[2]只计算前一个级别中尚未裁剪的属性组合。
请注意,图1显示了一个示例,我们将在本节的最后更详细地描述这个示例。
TANE’s search space pruning is based on the fact that for a complete result only minimal functional dependencies need be discovered. To prune efficiently, the algorithm stores a set of right-hand-side candidates C+(X) for each attribute combination X. The set C+(X) = {A ∈ R | ∀B ∈ X : X {A, B} → B does not hold} contains all attributes that may still depend on set X. C+(X) is used in the following three pruning rules:
TANE’s的搜索空间修剪是基于这样一个事实,即对于一个完整的结果,只需要发现最小的函数依赖性。为了有效地修剪,该算法为每个属性组合X存储一组右侧候选对象C+(X)。
集合C+(X)={A∈R|∀B∈X:X {A,B}→B不成立}, 集合C+(X)包含仍然可能依赖于集合X的所有属性
问题:C+(X)为什么包含的是可能依赖于X的所有属性? 对C+(X)这个集合的概念理解起来有点困难
以下三个修剪规则中使用了C+(X):
-
最小性剪枝:如果一个函数依赖项XA→A成立,则可以从C+(X)中删除A和所有B∈C+(X)X。换句话说,如果X包含FD XA→A,则任何FD X→B都不能是最小值,因为A使X成为非最小值。请注意,此定义还包括A=B。
问题:为什么要删除这里的B? 如果存在 XA→A说明 X→ A不是最小的,为啥说明X→B也不是最小的。
-
右侧剪枝:如果C+(X)=∅,则可以从格中修剪属性组合X,因为没有最小函数依赖性的右侧候选对象。
-
键剪枝:如果属性组合X是键,可以从格中修剪。键X是一种属性组合,它确定关系R中的所有其他属性RX。因此,X的所有超集都是超键,根据定义是非最小的。
理解:这里说X的所有超码需要剪到候选码
3.2 FUN
有参考资料
3.3 FD Mine
3.4 DFD
3.5 Dep-Miner
3.6 FastFDs
3.7 FDEP
4. 评价
4.1 实验装置
4.2 行可扩展性实验
4.3 列可扩展性实验
4.4 对不同数据集的实验
4.5 内存实验
4.6 实验结果外推
5. 总结
最后
以上就是欣喜斑马最近收集整理的关于【文献翻译】七种FD发现算法(未完成)摘要1. 函数依赖关系2. FD算法概述3. 七种FD发现算法4. 评价5. 总结的全部内容,更多相关【文献翻译】七种FD发现算法(未完成)摘要1.内容请搜索靠谱客的其他文章。








发表评论 取消回复