集合与字典
泛映射类型
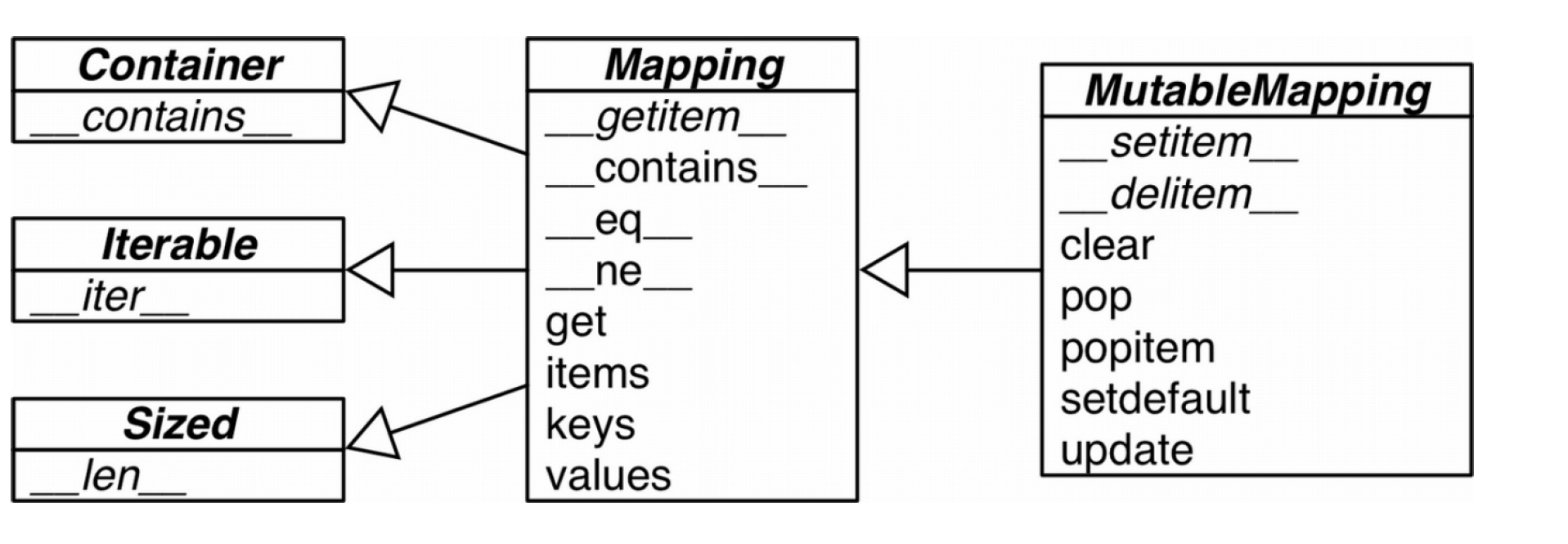
只有可散列的数据才可以作为键
原子不可变数据都是可散列类型,如str、bytes、数字等;
当一个元组包含的所有对象都是可散列时,元组才是可散列对象;
两个可散列对象的值相同时,其hash值也相同;
字典的构造方式

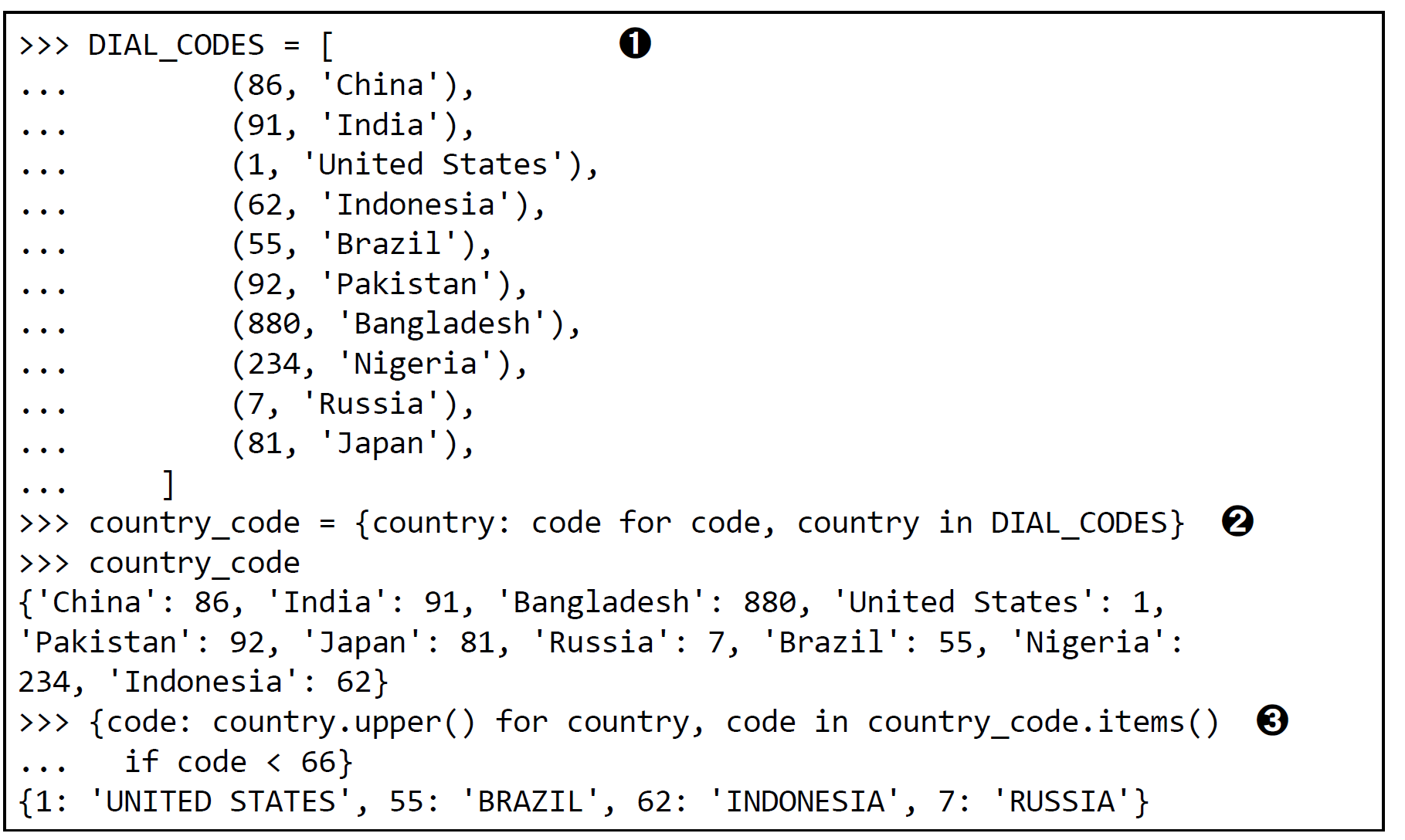
映射的弹性键查询
当某个键不存在时也可以获得一个默认的值;
使用collections.defaultdict;

使用特殊方法__missing__;
在__getitem__方法找不到对应键时,会调用此方法,而不是抛出一个KeyError异常;

__missing__使用示例
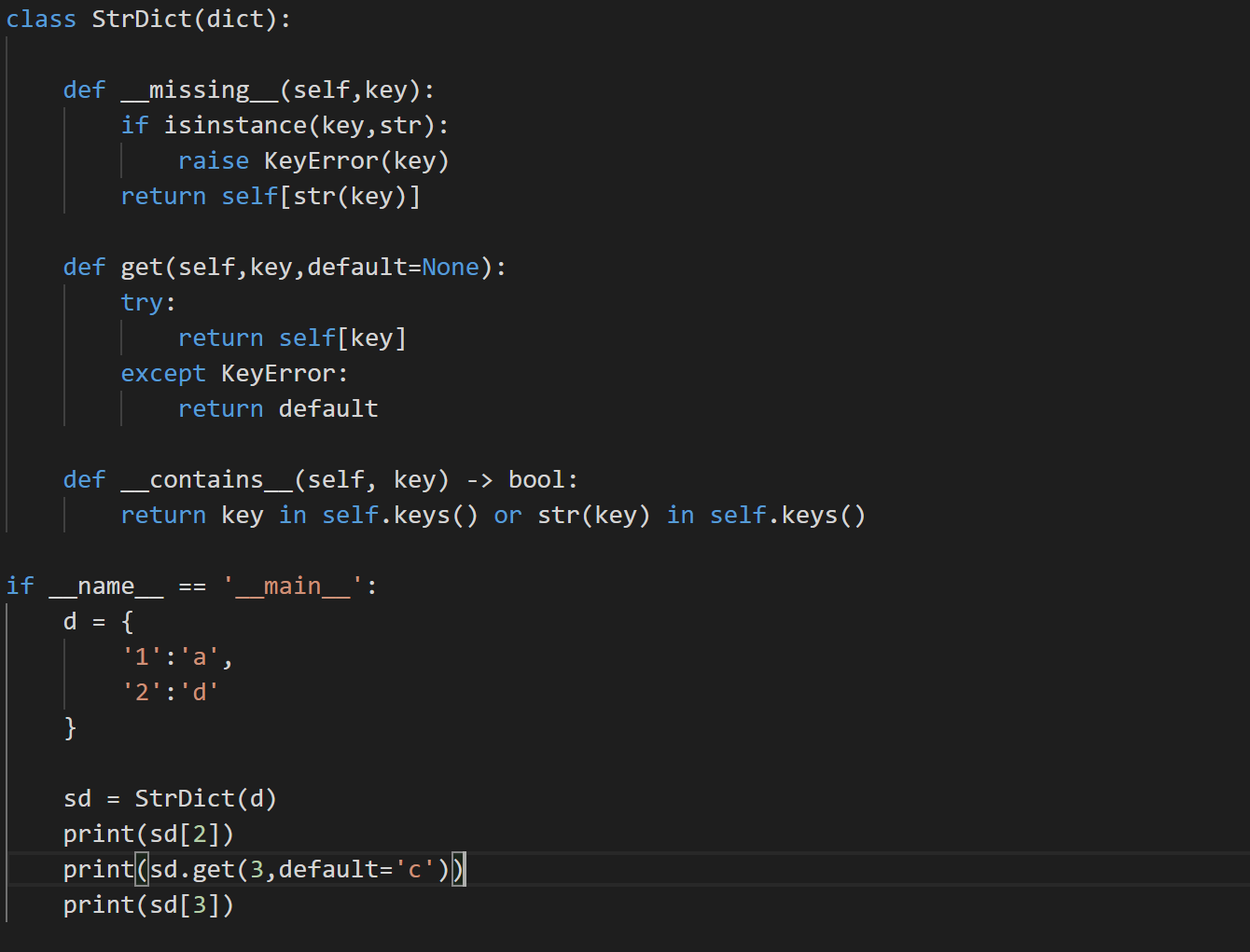
结果示例;
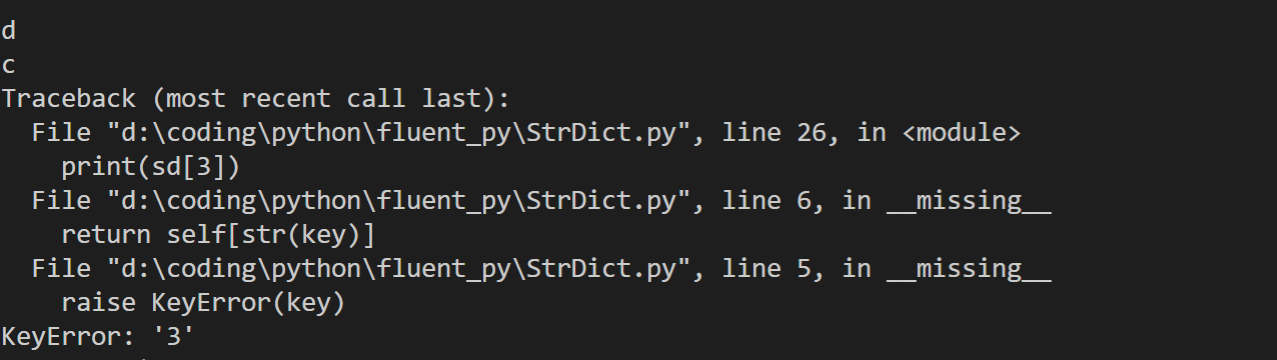
运行逻辑;

collections.OrderedDict
在添加键的同时保持顺序,键的迭代次序是一致的;
collections.ChainMap
容纳多个不同的Map,可以用来合并两个或者更多个字典,当查询的时候,从前往后依次查询;
而在修改时只会对第一个字典进行修改;
collections.Counter
用来给可散列表对象计数;

collections.UserDict
主要用来创造自定义Dict类;
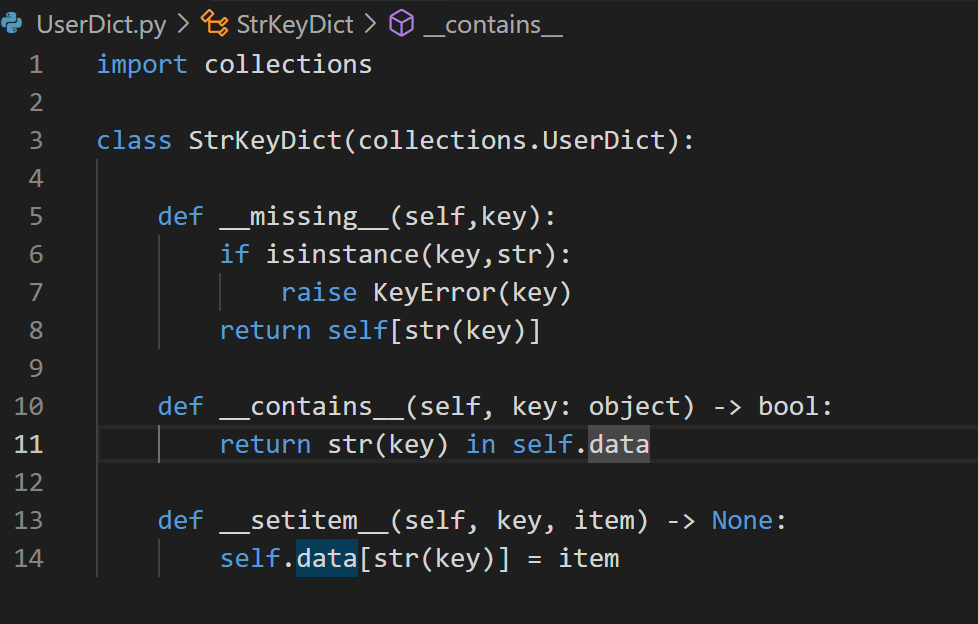
其中的data属性时UserDict中存放数据的地方;

集合
集合是许多唯一对象的聚集,主要用于去重;
集合中的元素是可散列的;
set类型是不可散列的,但f’rozenset是可以散列的;
常见操作有a&b、a-b、a|b;
创建空集合必须使用set();
{1,2,3}比set([1,2,3])速度更快;
集合的一些操作
效率
用in操作符在5个不同大小的haystack(支持散列表)上查找1000个元素花费的时间;
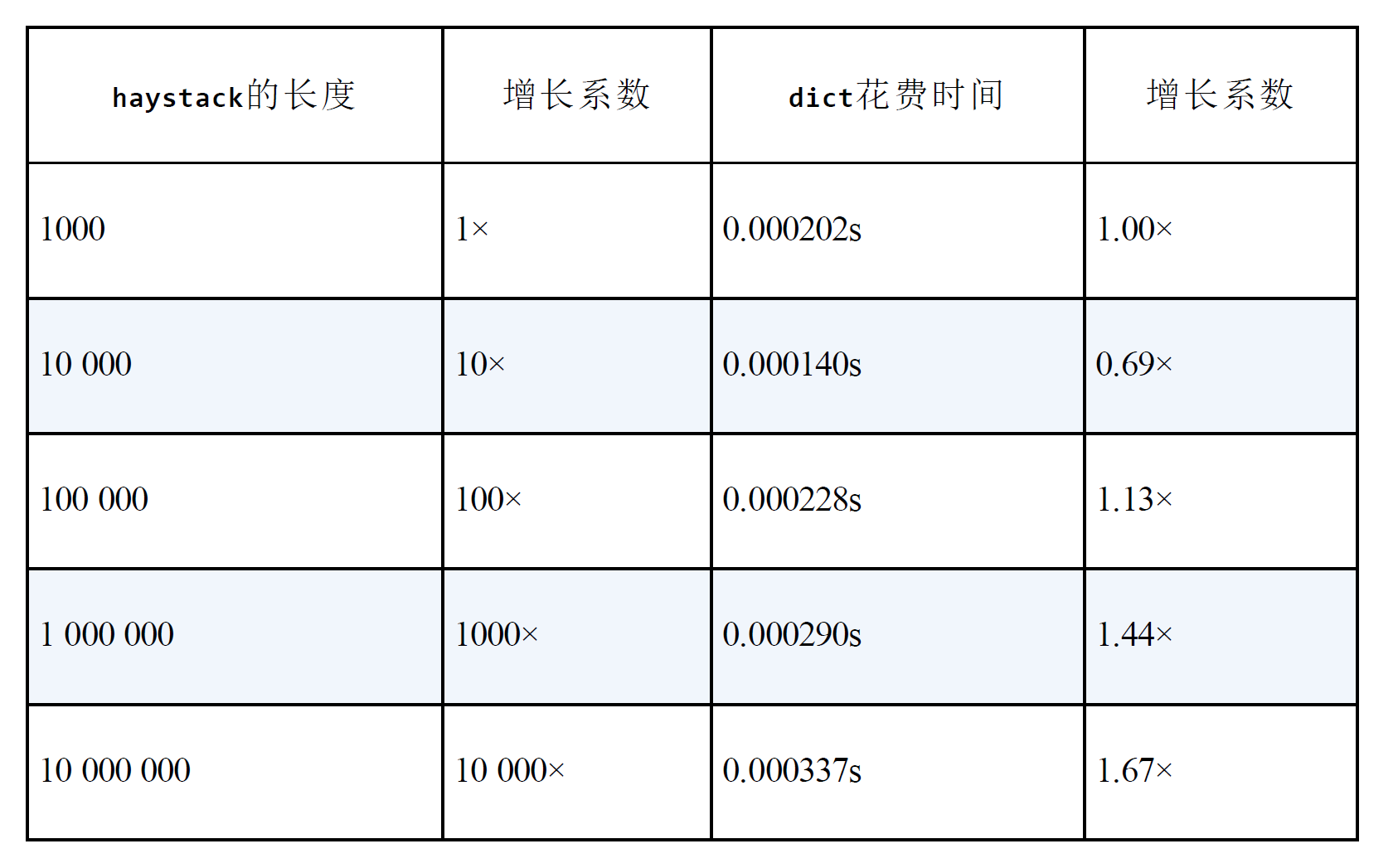
如果在不支持散列表的列表上进行查找,那么所花费时间将会线性增长;
散列表算法
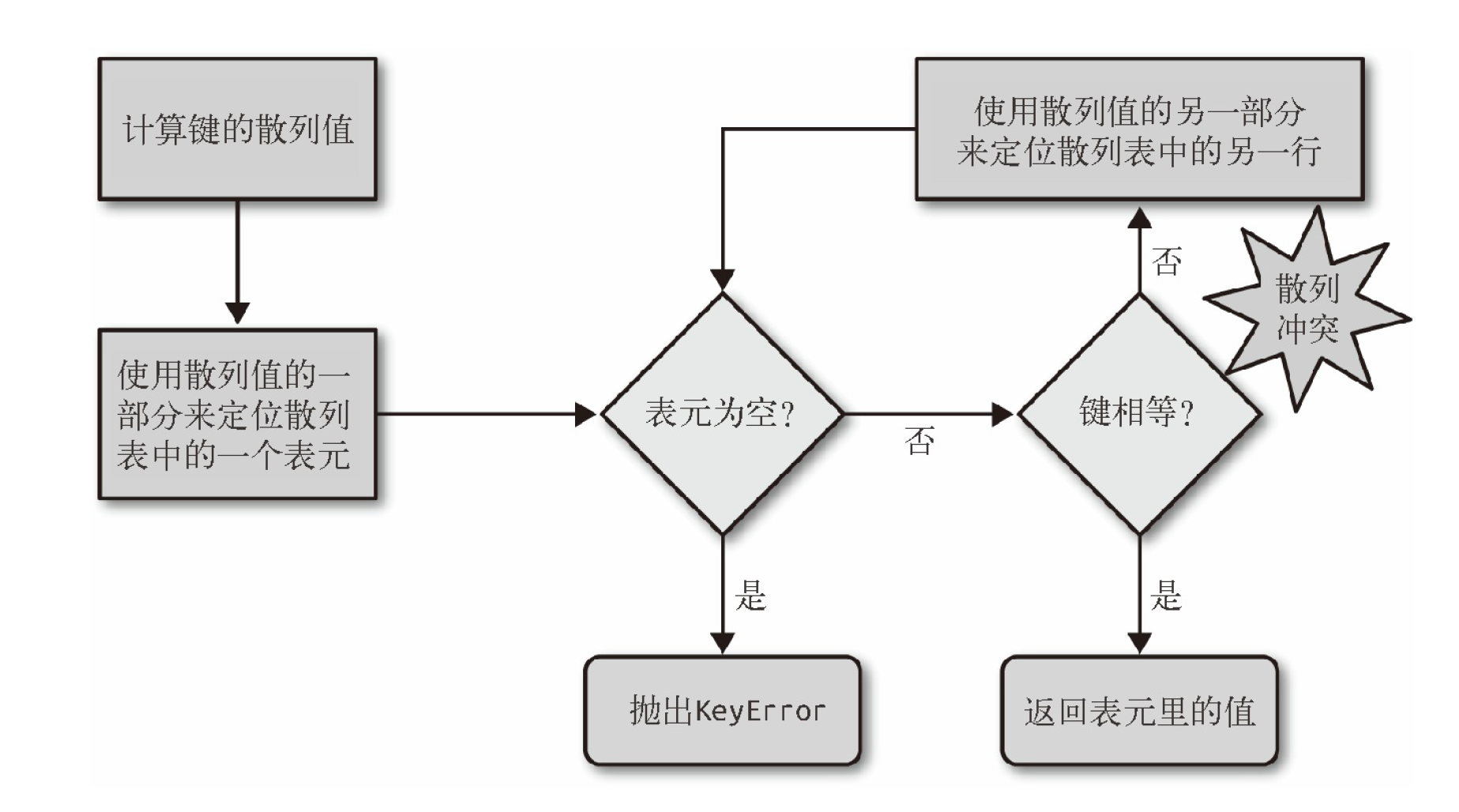
在dict的散列表表当中,每个键值对都占用一个表元;
一个表元都由两个部分组成;
一部分是对键的引用,另一部分是对值的引用;
所有表元大小一致,可以通过偏移量来进行读取;
Python会设法保证还有三分之一的表元是空的,在到达这个阈值时原有的散列表会被复制到一个更大的空间里去;
hash
hash保证两个对象在比较时相同则hash值相同;
相似但不相同的两个对象hash值差异尽可能大;

添加新元素时,找到空表元插入值;
更新元素时,找到对应表元并插入值;
为防止散列冲突的出现,Python会根据散列表的拥挤程度来决定是否为其扩容;
字典的实现与后果
条件

字典在内存上会产生巨大开销;
存放巨大数据量适合采用元组或者具名元组;
dict是空间换时间;
键的次序取决于添加的次序;
集合的实现与后果
集合在散列表中只存放引用而不存放值;
集合中元素必须是可散列的;
集合很消耗内存;
元素次序取决于添加次序;
往集合里添加次序会改变集合原有的次序;
最后
以上就是微笑老虎最近收集整理的关于集合与字典的全部内容,更多相关集合与字典内容请搜索靠谱客的其他文章。








发表评论 取消回复