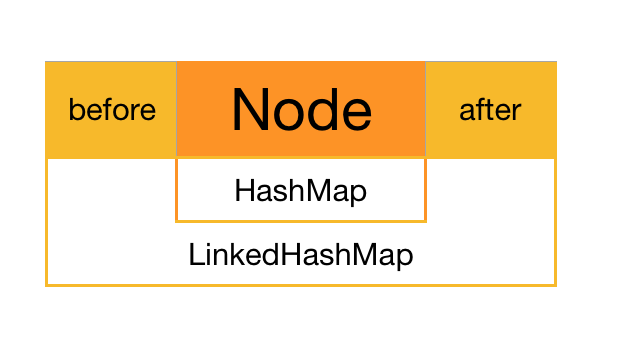
LinkedHashMap=双向链表+HashMap,存储相比HashMap会多了一个前节点,后节点.
LinkedHashMap简介
LinkedHashMap主要是通过HashMap+双向链表来实现的,主要作用目前就个人使用来看,可以主要有插入排序,访问排序.有了这两个排序就可以很简单的实现LRU,FIFO缓存算法.至于怎么用,就看个人的改造能力了.下面将会分析源码,以及用它来实现各种缓存算法.
LinkedHashMap源码分析
在jdk1.8的HashMap中多了三个方法里面什么都没做,为的就是留给LinkedHashMap去实现
void afterNodeAccess(Nodep) { }节点访问后:重复插入相同的key值或者get过该key,都会将该元素移动至队列尾部
void afterNodeInsertion(boolean evict) { }节点插入后:节点插入后做什么操作呢?队列满的时候删除队列头部的元素
void afterNodeRemoval(Nodep) { }节点移除后:移除节点后操作
这三个方法实在HashMap中定义的,但是具体的实现是在LinkedHashMap中实现的,这也是LinkedHashMap的意义所在.
源码分析
public class LinkedHashMap
extends HashMap
implements Map{
//在HashMap的节点上包装了一个前节点,尾节点
static class Entry extends HashMap.Node {
Entry before, after;
Entry(int hash, K key, V value, Node next) {
super(hash, key, value, next);
}
}
//Linked是一个双向链表的,这个是链表头节点,下面是尾节点
transient LinkedHashMap.Entry head;
transient LinkedHashMap.Entry tail;
// true:按访问顺序存储(LRU),false:按存入顺序存储(FIFO,先进先出)
final boolean accessOrder;
}
调用put方法时,其实调用的是HashMap的方法,HashMap在newNode时,LinkeHashMap重写了该方法.
Node newNode(int hash, K key, V value, Node e) {
LinkedHashMap.Entry p =
new LinkedHashMap.Entry(hash, key, value, e);
linkNodeLast(p); //将该节点拼接为一个linkNode
return p;//返回node节点
}
//这里就是组装一个双向链表哦.
private void linkNodeLast(LinkedHashMap.Entry p) {
LinkedHashMap.Entry last = tail;
tail = p;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
}
从上面可以看出同一个node,被用来存储到HashMap中,又被用来组成一个链表.相当于双重数据结构.并不意味着数据就是两份,要知道node只有一个哦,Java里面通过引用多个值引用同一个对象.就如:
Object o=new Object();
Object a=o;
Object b=o;
这里始终只有一个对象.他们三个都引用了o这个对象.
afterNodeInsertion
在HashMap的put方法最后有这么一句:afterNodeInsertion(evict);LinkedHashMap重写了之后
void afterNodeInsertion(boolean evict) { // 是否移除头部元素
LinkedHashMap.Entry first;
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
//是否删除元素
protected boolean removeEldestEntry(Map.Entry eldest) {
return false;
}
afterNodeAccess
在put方法中还调用了afterNodeAccess(e);都知道HashMap可以重复添加元素(重复key相当于更新value,key始终是唯一的),在HashMap中已经有key1了,这个时候在put(key1,..)那就是更新value值,不管是get,还是put更新都会触发afterNodeAccess(访问后)方法,不管是更新还是访问都是一种访问.
HashMap--put方法中出发:
void afterNodeAccess(Node e) { // 将访问的元素e移动到队列尾部
LinkedHashMap.Entry last;
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry p =
(LinkedHashMap.Entry)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
LinkedHashMap中重写了HashMap的get方法,简单明了
public V get(Object key) {
Node e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder) //是否按访问排序,如果等于true则调整顺序
afterNodeAccess(e);
return e.value;
}
这段代码自己画个图更一下就会明白.
node1 node2 node3 node4
访问了node2或者更新了node2,都会出发afterNodeAccess方法,该方法就是将node2移动值链表尾部.移动后变成
node1 node3 node4 node2
奇怪点解说
void afterNodeAccess(Node e){
LinkedHashMap.Entry p = (LinkedHashMap.Entry)e
}
在put是,newNode的时候LinkedHashMap创建的是一个LinkedHashMap.Entry但是返回的是一个Node数据给HashMap,HashMap拿到的这个Node其实里面隐藏了Entry的前节点后节点.只不过通过Node无法直接访问.
当节点传递过来之后(LinkedHashMap.Entry)e 强转义之后,before,after节点就会自动回来的.
afterNodeRemoval
LinkedHashMap继承了HashMap, LinkedHashMap只在有需要的地方重写了HashMap的方法,其他都是原用HashMap的方法的,同时它并没有改变HashMap的任何结构.只是自己扩展了一个链表.在LinkedHashMap中删除操作就没有任何重写操作,所以HashMap中删除一个元素时,同时也需要在LinkedHashMap中的链表中删除该节点.这个时候就有了扩展方法afterNodeRemoval,只是为了HashMap删除的同时删除在链表中也将该元素删除.
void afterNodeRemoval(Node e) { // unlink
LinkedHashMap.Entry p =
(LinkedHashMap.Entry)e, b = p.before, a = p.after;
p.before = p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a == null)
tail = b;
else
a.before = b;
}
FIFO算法
FIFO(先进先出)的思想是基于队列。如果一个数据是最先进入的,那么可以认为在将来它被访问的可能性很小。空间满的时候,最先进入的数据会被最早置换(淘汰)掉。
适合热点数据为新数据,最先存入的数据为最老的数据,最后存入的为新数据,当超过队列长度时,删除队列头部数据(老数据)即可.
private static class MyFIFO extends LinkedHashMap {
protected int maxElements;
public MyFIFO(Integer maxSize) {
super(maxSize, 0.75f, false); //FIFO false:访问元素时,不移动。
this.maxElements = maxSize;
}
//当总数大于最大值时,执行删除队列头的动作
protected boolean removeEldestEntry(Map.Entry eldest) {
return this.size() > this.maxElements;
}
}
private static void test(Map map) {
//true表示如果最近访问的,将数据移动到队列尾部。
for (int i = 0; i < 20; i++) {
if (i == 11) {
map.get("k8");//访问后,元素被移动到队列尾部去了。
}
if (i == 18) {
map.get("k14");
}
map.put("k" + i, i);
}
System.out.println("===开始遍历元素====");
for (Map.Entry m : map.entrySet()) {
System.out.println(m.getKey() + "," + m.getValue());
}
}
LRU算法
LRU(The Least Recently Used,最近最久未使用算法)的思想是基于时间,如果一个元素最久没有使用到,那么在将来中使用到的几率也最少,可以将最久未使用的元素从容器中剔除。
可以利用LinkedHashMap的访问顺序存储.被访问过元素移动到队列尾部,长时间未被访问的元素自然在队列头部了,当存入的元素大于队列时,只需要移除队列头的元素即可.
private static class MyLRU extends LinkedHashMap {
protected int maxElements;
public MyLRU(Integer maxSize) {
super(maxSize, 0.75f, true); //区分点true:每次访问元素,都将元素移动到队列尾部
this.maxElements = maxSize;
}
//当总数大于最大值时,执行删除队列头的动作
protected boolean removeEldestEntry(Map.Entry eldest) {
return this.size() > this.maxElements;
}
}
LFU算法
这个如果用redis来实现就会更简单了。
LFU(Least Frequently Used ,最近最少未使用算法)的思想是基于频率,如果一个元素的使用频率最少,那么在将来使用到的情况也最少.这个算法需要记录元素的访问次数,然后淘汰访问次数最少的元素.
LFU和LRU看似相同,但其实不同,不同点在于新加入的元素。
LRU是每次访问都把元素插入到队列尾,新加入的元素也在队列尾巴,超出队列规定长度后淘汰队列头部。
缺点比如:1,2,3,4,5,6,7,8,9,10都是经常被访问的数据,但是队列大小只有10,这个时候插入11也许并不是热点数据,但是规则的问题还是会把1给删掉.
LFU是把每次访问的元素值+1,淘汰count值最小的。根据访问量排序,把访问量少的给淘汰掉。
LFU也有缺点,那就是新加入的元素由于没有访问量,也许就被误杀了.
private static class MyLFU extends HashMap {
public PriorityQueue> queue = new PriorityQueue<>();
protected int maxElements;
public MyLFU(Integer maxSize) {
this.maxElements = maxSize;
}
public V put(K k, V v) {
queue.add(new Node<>(k, 1));//初始值为1
if (size() > maxElements) {
//poll弹出队列头
remove(queue.poll().key);
}
return super.put(k, v);
}
public V get(Object k) {
for (Node kNode : queue) {
if (k != null && k.equals(kNode.key)) {
kNode.setCount(kNode.getCount() + 1);
}
}
return super.get(k);
}
}
//排序后,count值小的排在最前面,当执行poll时,count值最小的也就会被最先弹出。
private static class Node implements Comparable> {
private K key;
private int count;
public Node(K key, int count) {
this.key = key;
this.count = count;
}
public K getKey() {
return key;
}
public int getCount() {
return count;
}
public void setCount(int count) {
this.count = count;
}
@Override
public String toString() {
return "[key=" + key + ", count=" + count + "]";
}
@Override
public int compareTo(Node o) {
return this.count - o.count;
}
}
private static void testLFU() {
MyLFU map = new MyLFU<>(10);
for (int i = 0; i < 20; i++) {
if (i == 9) {
map.get("k8");//访问后,元素被移动到队列尾部去了。
}
if (i == 6) {
map.get("k5");
map.get("k3");
}
map.put("k" + i, i);
}
for (int i = 0, n = map.queue.size(); i < n; i++) {
System.out.println(map.queue.poll());
}
}
最后
以上就是孝顺路人最近收集整理的关于java lru lfu_Java集合之LinkedHashMap实现LRU,LFU,FIFO算法的全部内容,更多相关java内容请搜索靠谱客的其他文章。








发表评论 取消回复