【概述】
在hadoop中,客户端与namenode、datanode与namenode、dfsadmin与namenode、客户端与resourcemanager等模块之间的交互都采用rpc的方式进行,本文就来聊聊hadoop中rpc的实现。
【客户端】
从模块分层的角度来看,RPC客户端通常可以分为如下几层:
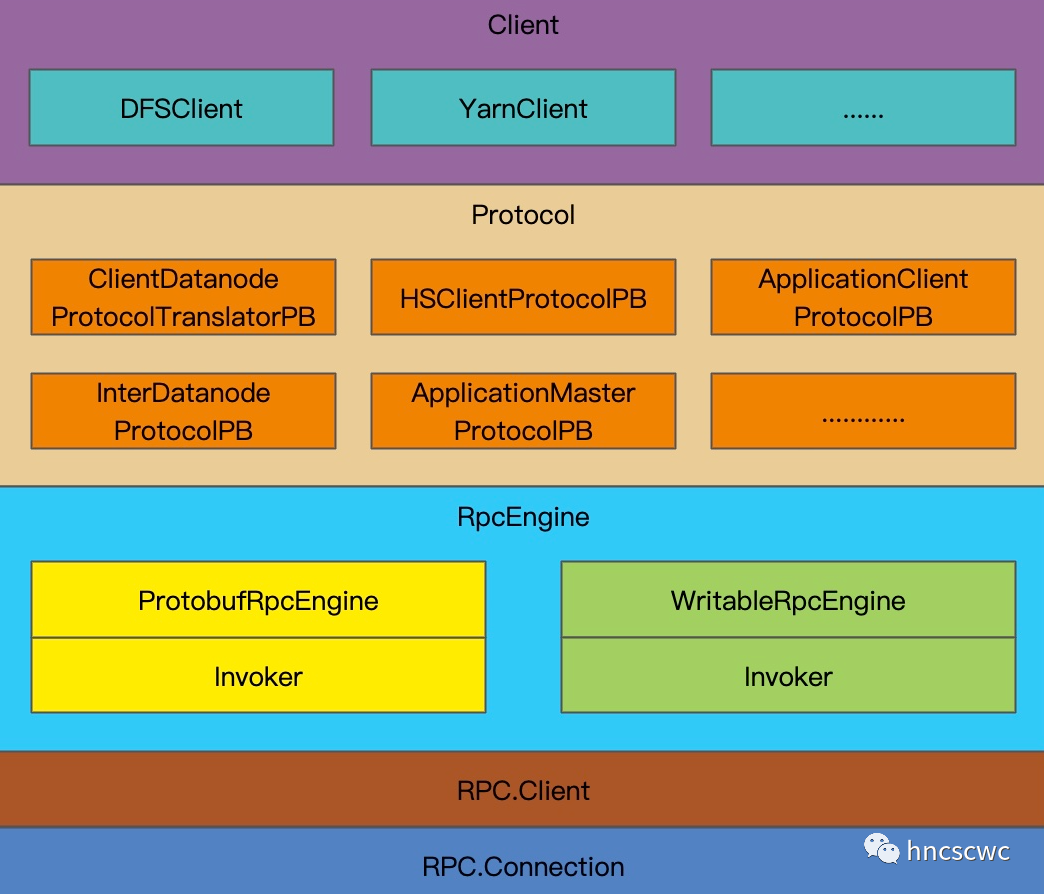
最上层的客户端封装层:例如DFSClient,YarnClient,DFSAdmin等等,对外暴露接口调用,内部调用下层接口实现功能。
中间为协议转换层:不同的请求本质上是不同的协议。因此,有众多不同的协议实现类。在这些实现类中,主要负责对各自请求的结构体进行序列化与反序列化的操作。另外,每个协议实现类中,都会有一个代理(RPCProxy)的成员对象,请求通过调用代理的接口向下透传,最终向服务段发送请求并获取到响应内容。
代理层:也可以理解为是RPC引擎层,因为向上提供了通用的代理对象和处理类,向下调用通信层的接口向服务端发送请求。RPCEngine本身是一个接口,具体实现类为ProtobufRpcEngine和WritableRpcEngine,两个引擎中各自都包含了一个invoker类,实现了java动态代理框架中处理类的接口,在invoker内部,则封装了对RPCClient的操作。
网络通信层:RPC的网络通信,具体包括RPC连接(hadoop中均采用tcp的方式)的建立,请求的发送与响应的接收。RPCClient内部维护了一个连接(Connection)列表,每个连接都是一个独立的线程,在线程内部负责正常请求的发送与响应的接收。
对于采用了高可用的模块而言,例如namenode,resourcemanager,对应的客户端其整体结构,会在协议层与RPC引擎层之间再多加一层抽象,称为重试代理(RetryProxy)。
在该层,会进行请求失败的重试,因为向standby的节点发送请求,或者active的节点异常情况,均无法得到响应,因此需要进行重试。
同样,向上仍旧是通过java动态代理的方式返回代理对象,向下则调用对应引擎层的接口,获取代理对象,并调用对应的方法完成请求。
这样对于上层的客户端,则不需要感知下面的重试逻辑,完全是透明的处理逻辑。
从逻辑流程上来看,RPC请求会分为两个步骤:
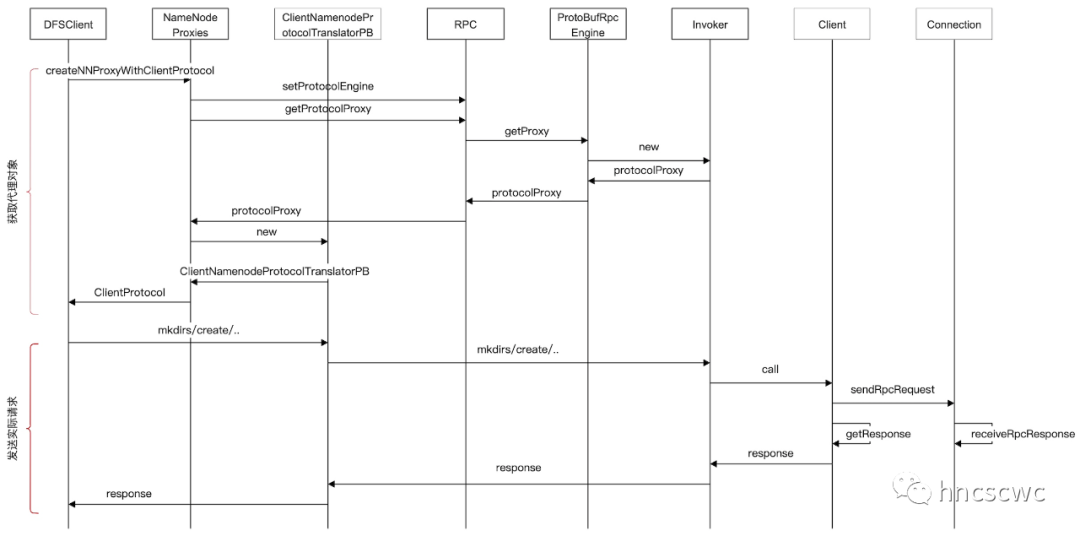
获取代理对象
客户端的请求流程中,首先是获取一个接口协议的代理对象。该代理对象通常是由RPC引擎提供的,具体通过java的动态代理方式,返回代理对象。
通过代理对象发送请求
上面讲到了,代理对象是通过java动态代理的方式构建出来的,因此,所有的方法调用最终会调用到invoker的invoke方法中。在invoke方法中,根据不同的请求序列化成不同的请求头,同时对请求也进行序列化,然后通过RPC的Client将序列化的内容发送给服务端。最后从服务端收到请求的响应,反序列化后返回实际结果。
【服务端】
服务端采用了reactor的设计,以多线程的方式负责RPC请求的处理,线程与类的逻辑如下图所示(纵向表示线程内的调用流程,横向表示不同的类提供的不同接口)
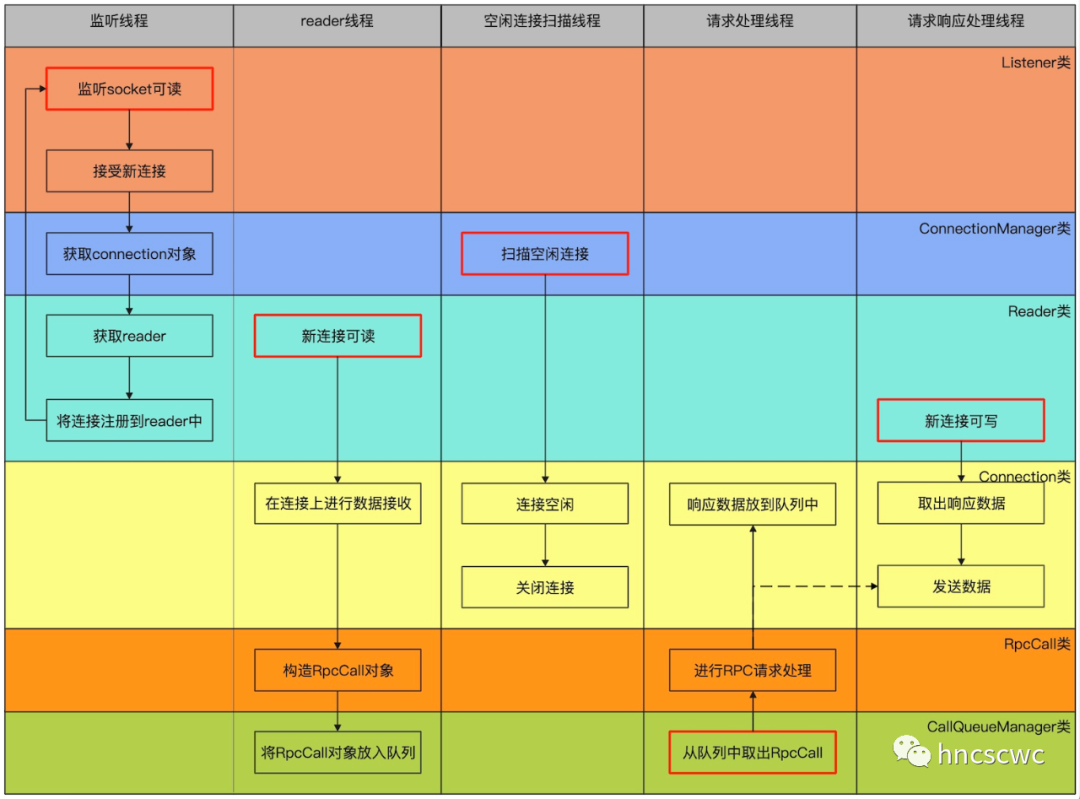
有几点需要注意的地方:
请求处理线程从Call队列中取出RPC请求,并回调完成RPC请求处理后,会根据线程的繁忙程度,将响应数据放到队列中,由另外的线程从队列中取出响应结果发送给客户端,或者是直接进行数据的发送。
所谓空闲连接指的就是当前连接上没有任何RPC请求。
【总结】
本文总结了hadoop中rpc相关的原理,其实rpc客户端与服务端分别都还有诸多的配置项,例如服务端reader的线程数,请求处理线程数,call队列长度,空闲连接数等等,有兴趣的可以阅读相关源码。

最后
以上就是威武砖头最近收集整理的关于Hadoop中的RPC的全部内容,更多相关Hadoop中内容请搜索靠谱客的其他文章。








发表评论 取消回复