房价还受周边群体收入影响,例如后厂村这种地方,房价高企应该是被腾讯、百度托起来的。
所以,我们还要获取一份北京大公司的收入和位置的数据。
基本的数据还是靠搜索。能把房价抬起来,得具备两个条件,薪酬丰厚,人数多,企业和行业需要有规模效应。
规模效应有两种表现形式,一个是像后厂村,有腾讯、百度两家大厂;一个是像金融街,虽然没有特别大的公司,但金融从业者聚集于此。
一、公司名录与工资
不管如何,我们也需要在网上找到一个获取各企业工资的数据源,找了半天,找到一个不那么不靠谱的网址,职友网:
https://www.jobui.com/rank/company/salary/beijing/all/2020/?n=1
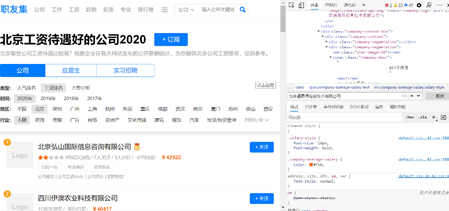
将排名靠前的公司的名称和工资爬下来,写入gongzi.txt文件中。
import requests
from bs4 import BeautifulSoup
def getpage(i):
url = 'https://www.jobui.com/rank/company/salary/beijing/all/2020/?n='+str(i)
# 请求头,避免403
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36'}
req = requests.get(url, headers=header, timeout=5, verify=False)
html = req.text
soup = BeautifulSoup(html)
companys = soup.findAll(name='div', attrs={'class': 'c-company-list'})
resultlist=[]
for c in companys:
result = ['','']
if len(c.findAll(name='h3', attrs={})) > 0:
name = c.findAll(name='h3', attrs={})[0].get_text()
result[0] = name
if len(c.findAll(name='em', attrs={'class': 'company-average-salary salary-style'}))>0:
money = c.findAll(name='em', attrs={'class': 'company-average-salary salary-style'})[0].get_text()
result[1] = money
resultlist.append(result)
return resultlist
if __name__ =='__main__':
fnew = open(r'gongzi.txt','a',encoding='utf-8')
for i in range(1,10):
result = getpage(i)
for r in result:
fnew.write('t'.join(r)+'n')
fnew.close()
二、位置数据获取
有了工资名称,位置数据就很好获取了,调用地理编码服务即可。
但是有些公司根据公司名获取不到坐标,那就手动查询获取地址,把坐标补充一下吧。
import requests
from requests.adapters import HTTPAdapter
s = requests.Session()
s.mount('http://', HTTPAdapter(max_retries=3))#设置重试次数为3次
s.mount('https://', HTTPAdapter(max_retries=3))
def geo(key,name):
url = 'https://restapi.amap.com/v3/geocode/geo?city=北京&address=' + name + '&output=JSON&key=' + key
location=''
try:
r = s.get(url, timeout=5)
data = r.json()
if 'status' in data:
if data['status'] == '1':
location = data['geocodes'][0]['location']
except BaseException as e:
print(e)
return location
if __name__ =='__main__':
key =
f = open(r'gongzi.txt','r',encoding='utf-8')
fnew = open(r'gongzilocation.txt','a',encoding='utf-8')
flines = f.readlines()
for l in flines:
llist = l.strip('n').split('t')
if len(llist) > 1:
print(llist[0])
location = geo(key,llist[0])
fnew.write(llist[0]+'t'+llist[1]+'t'+location+'n')
f.close()
fnew.close()三、坐标拾取器
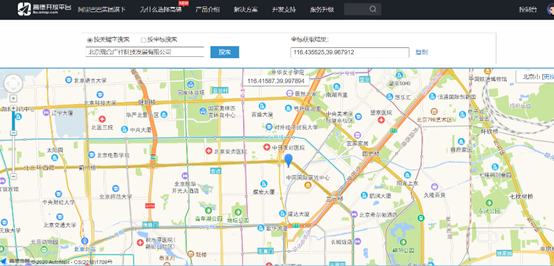
地理编码没有获取到的坐标,可以用坐标拾取器获取一下。
https://lbs.amap.com/console/show/picker
四、IP代理
在爬取北京房价的那篇里已经说过了,爬虫频繁访问,是会被限制的,解决方法有两个,一个是降低访问频率,一个是换IP。
爬虫IP代理的方案有很多,这里说一个我觉得比较简单的。
我使用的是代理蚂蚁,http://www.proxyant.com/,在网站上下载一个压缩包,包里有ProxyAnt5.exe可执行文件,注册后买一些蚁币,选择好服务类型,例如10~35分钟(扣10蚁币),选择好浏览器,例如谷歌Chrome浏览器。
选择好服务类型后,程序就启动了,从Chrome发出的请求就会不停的更换IP。
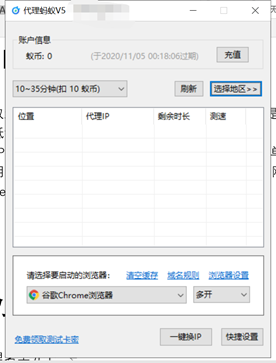
我们只要确定,我们的py脚本请求是从chrome浏览器发出的就行。
既如下:
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36'}
req = requests.get(url, headers=header, timeout=5, verify=False)
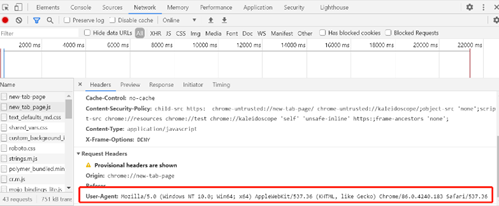
可以从chrome的网络响应中获取User-Agent。
五、小结
行百里者半九十。
到这里,分析用的数据应该获取完了,接下来就应该把这些数据关联起来,做分析了。
最后
以上就是坦率铃铛最近收集整理的关于空间分析:1-5.爬取北京大公司名称工资位置一、公司名录与工资二、位置数据获取三、坐标拾取器四、IP代理五、小结的全部内容,更多相关空间分析:1-5内容请搜索靠谱客的其他文章。








发表评论 取消回复