一、读取文件
import pandas as pd
flie_path1 = 'xxx.xlsx'
flie_path2 = 'xxx.csv'
df = pd.read_excel(flie_path1,header=2) # 读取excel文件,header默认为0,为2则将第三行作为标题,flie_path文件路径
# df = pd.read_excel(flie_path1, sheet_name='信息表') # 按表名读取
df = pd.read_csv(flie_path2,index_col=False) # 读取csv文件,index_col=False为去掉索引列
print(df.head(10)) # 打印前10行内容
二、创建内容
1、列表法list
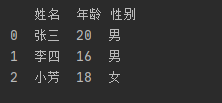
a = [['张三',20,'男'],
['李四',16,'男'],
['小芳',18,'女']]
df = pd.DataFrame(data=a,columns=['姓名','年龄','性别'])
2、字典法dict
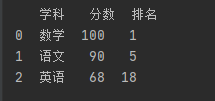
a = {'学科':['数学','语文','英语'],
'分数':[100,90,68],
'排名':[1,5,18]}
df = pd.DataFrame(data=a)
三、获取内容
1、获取标题 (即第一行内容)
title = df.columns.values.tolist() # title = ['学科','分数','排名']
2、获取第一列所有元素
rows = df.iloc[:, 0].values.tolist()
3、获取行数、列数
row_column_num = df.shape # row_column_num = (行数,列数)
4、获取某列、多列内容
# 单列
subject = df['学科'].values.tolist() # subject = ['数学','语文','英语']
# 多列方法一
subject = df[['学科','分数','排名']]
# 多列方法二
subject = df.iloc[:,0:3] # 读取1~3列
5、按条件读取一整行数据(条件取行)
content = df[df['学科']=='语文'].values[0].tolist() # content = ['语文',90,5]
6、获取某行某列内容(条件取值)
score = df.loc[df['学科']=='语文','分数'].values[0] # score = 90
7、按坐标获取内容(坐标取值)
content = df.iloc[0,0] # content = 数学
8、提取某列前10个内容
content = df.loc[:10,'学科']
# 或者 content = df['学科'][:10]
四、修改内容
1、按坐标修改
df.iloc[0,0] = '物理' # 修改该坐标值为物理
2、按条件修改
df.loc[df['学科'] == '语文','分数'] = 66 # 修改满足该条件内容为 66
五、删除内容
1、增加一列数据
df['学分'] = ['3','2','2']
2、删除某行、某列
df.drop(1,inplace=True) # 删除索引为1的行
df.drop('分数',axis=1,inplace=True) # 删除分数整列,axis=1表示对列操作
df.drop(columns=['排名'],inplace=True) # inplace=True 表示在当前df中删除数据,改变原始数据
2、按条件删除某行
df.drop(df[df['分数'] == 90].index, inplace=True) # 删除分数为90的行
六、消除重复
new_df = df.drop_duplicates(['标题1'], keep='first') # 根据标题消重,且保留第一项,keep='last'则保留最后一个
new_df = df.drop_duplicates(subset=['标题1','标题2'],keep='first') # 根据两个标题内容作为唯一键,两个内容都一样就消重
new_df.to_excel('文件.xlsx',index=None)
七、保存为文件
df.to_excel('file_name.xlsx') # 保存为excel文件
df.to_csv('file_name.csv',index=False) # 保存为csv文件,index=False为去掉索引列
八、将日期转为字符串、字符串转日期
1、日期转字符串
subject = df.iloc[:,0].astype(str).values.tolist() # 将第一列日期转为字符串
2、Excel的数字形式日期转字符串(如:44957,44958,44960)
from datetime import datetime
date_int = 44957
date_str = datetime.fromordinal(datetime(1900, 1, 1).toordinal() + int(date_int) - 2).strftime("%Y-%m-%d")
print(date_str)
3、字符串转日期
subject = pd.to_datetime(df1.iloc[:,0]) # 将第一列字符串转为日期
最后
以上就是还单身月亮最近收集整理的关于python之pandas库基本使用方法的全部内容,更多相关python之pandas库基本使用方法内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复