这里就大数据生态中几种典型的方案,从数据规模,时效性,查询性能与并发,灵活性,运维,扩容迁移容灾等几个关键维度进行深度对比分析,来探讨构建实现一个高性能的交互式查询与分析引擎的思路。
SQL-on-Hadoop方案(Hive、Spark SQL、Impala)
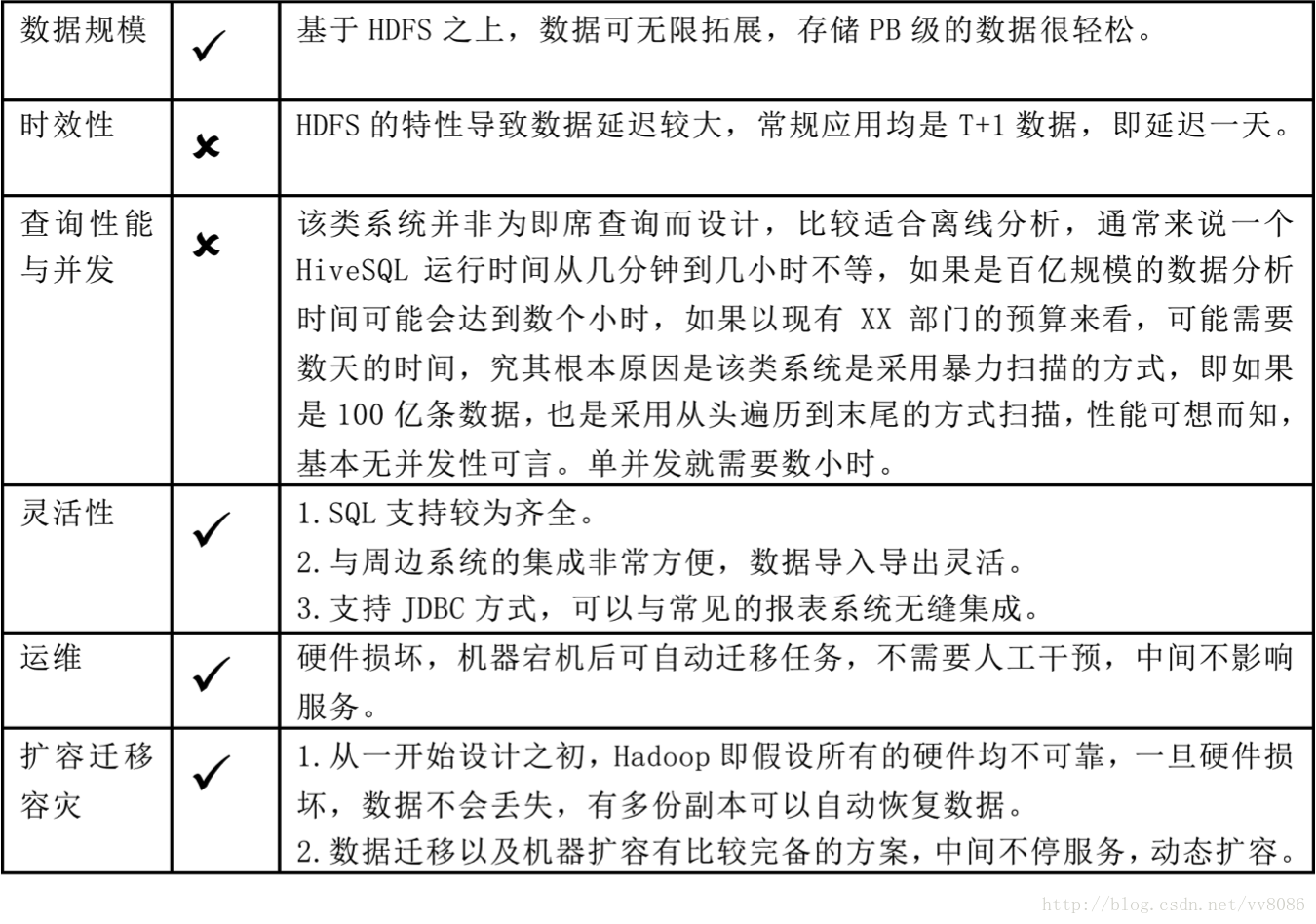
流计算方案(Storm、Spark Streaming)

全文检索方案(Solr、ElasticSearch)
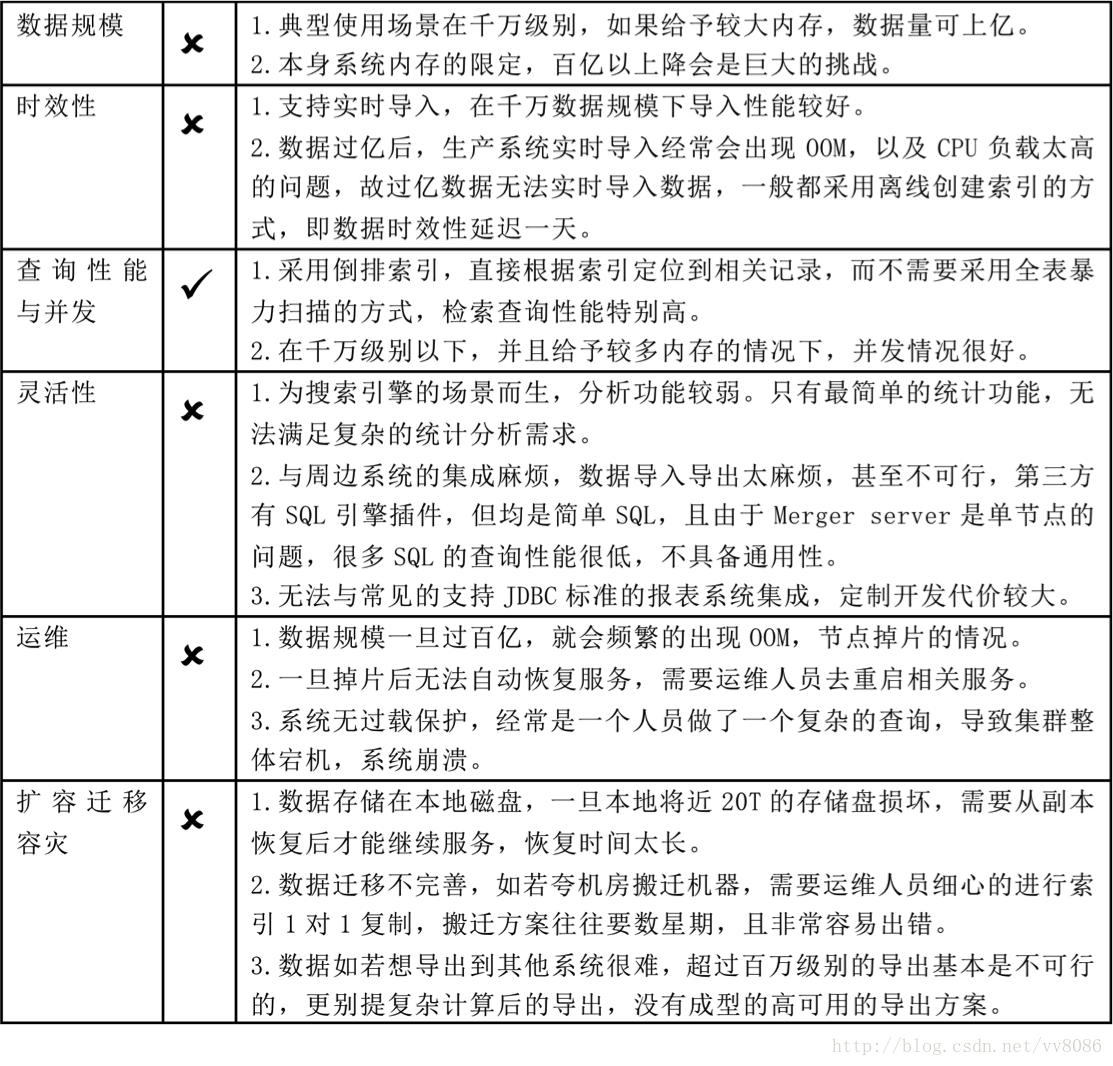
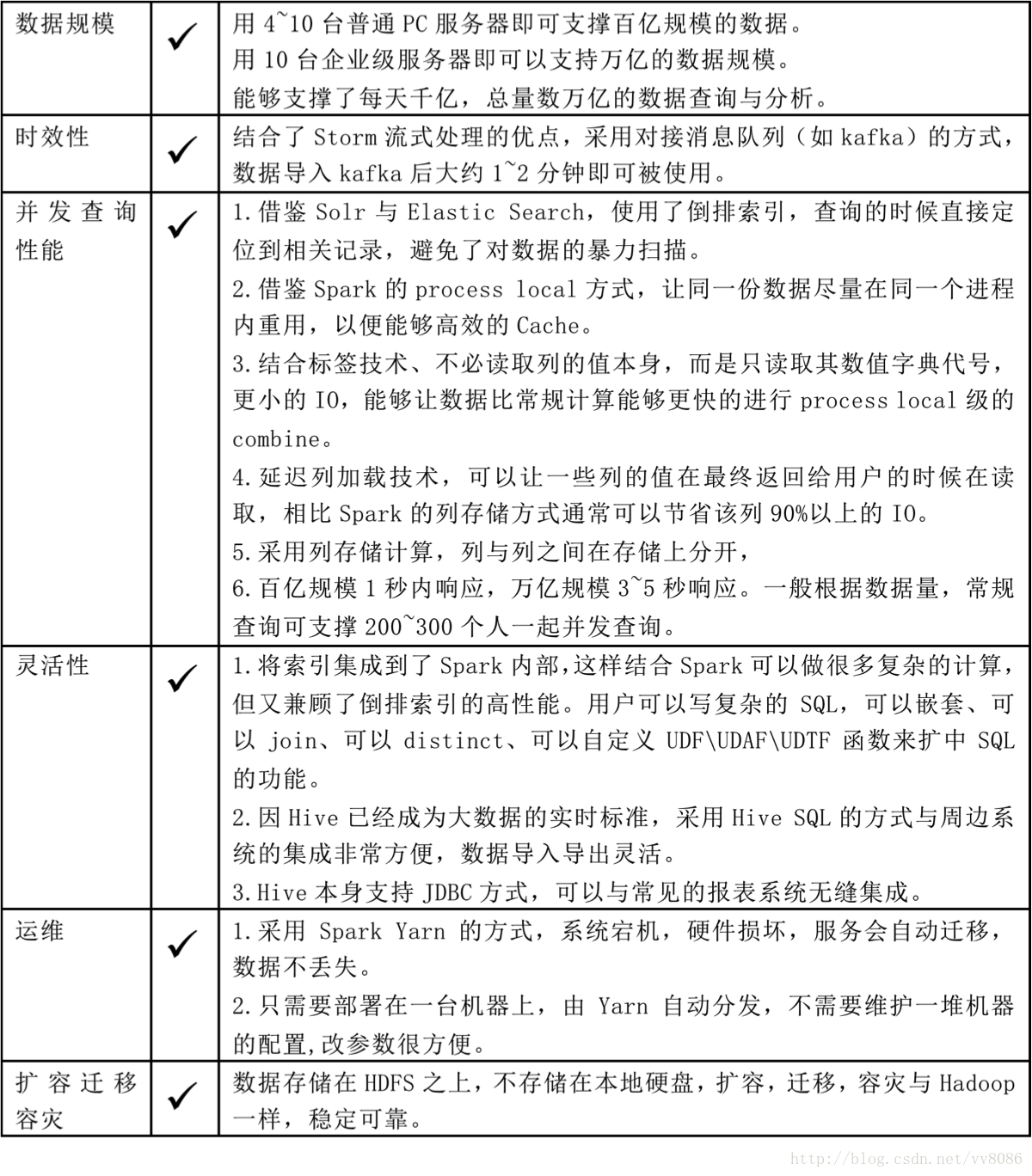
最优方案(一个万亿数据秒级查询与分析引擎)
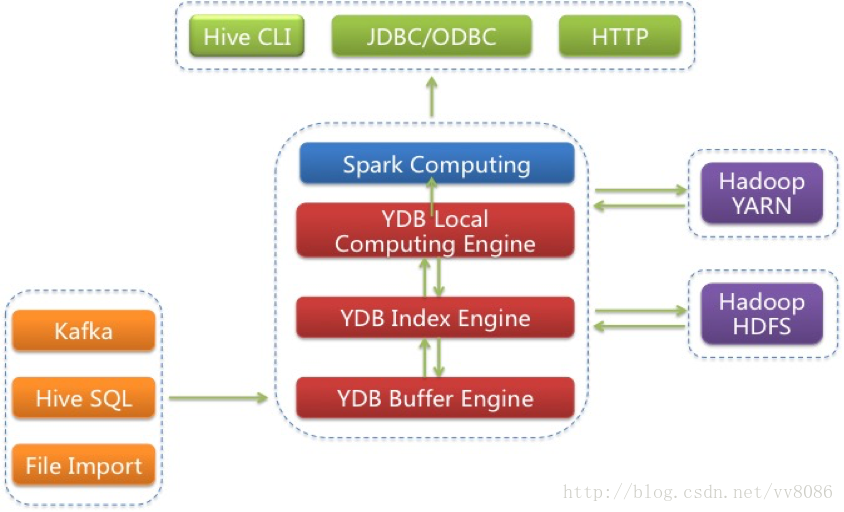
构建实现一个基于Hadoop分布式架构下的实时的、多维的、交互式的查询、统计、分析引擎,具有万亿数据规模下的万级维度秒级统计分析能力,并具备企业级的稳定可靠表现。 通过细粒度的索引,精确粒度的索引。数据即时导入,索引即时生成,通过索引高效定位到相关数据。能够与Spark深度集成,Spark直接对检索结果集分析计算,同样场景让Spark性能加快百倍。 整体技术架构如下:
最后
以上就是幸福黄蜂最近收集整理的关于一个高性能交互式查询与分析引擎的设计思路的全部内容,更多相关一个高性能交互式查询与分析引擎内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。







![[原创]工作流自适应引擎的设计思想(初步)](https://www.shuijiaxian.com/files_image/reation/bcimg19.png)
发表评论 取消回复