1. 整体框架
使用多线程来处理不同的连接,对于每个连接,分析Http报文,并执行相应的请求,代码只实现了对GET请求和POST请求。执行CGI的时候,采用了多进程方式。
工作流程
(1) 服务器启动,在指定端口或随机选取端口绑定 httpd 服务。
(2)收到一个 HTTP 请求时(其实就是 listen 的端口 accpet 的时候),派生一个线程运行 accept_request 函数。
(3)取出 HTTP 请求中的 method (GET 或 POST) 和 url,。对于 GET 方法,如果有携带参数,则 query_string 指针指向 url 中 ? 后面的 GET 参数。
(4) 格式化 url 到 path 数组,表示浏览器请求的服务器文件路径,在 tinyhttpd 中服务器文件是在 htdocs 文件夹下。当 url 以 / 结尾,或 url 是个目录,则默认在 path 中加上 index.html,表示访问主页。
(5)如果文件路径合法,对于无参数的 GET 请求,直接输出服务器文件到浏览器,即用 HTTP 格式写到套接字上,跳到(10)。其他情况(带参数 GET,POST 方式,url 为可执行文件),则调用 excute_cgi 函数执行 cgi 脚本。
(6)读取整个 HTTP 请求并丢弃,如果是 POST 则找出 Content-Length. 把 HTTP 200 状态码写到套接字。
(7) 建立两个管道,cgi_input 和 cgi_output, 并 fork 一个进程。
(8) 在子进程中,把 STDOUT 重定向到 cgi_outputt 的写入端,把 STDIN 重定向到 cgi_input 的读取端,关闭 cgi_input 的写入端 和 cgi_output 的读取端,设置 request_method 的环境变量,GET 的话设置 query_string 的环境变量,POST 的话设置 content_length 的环境变量,这些环境变量都是为了给 cgi 脚本调用,接着用 execl 运行 cgi 程序。
(9) 在父进程中,关闭 cgi_input 的读取端 和 cgi_output 的写入端,如果 POST 的话,把 POST 数据写入 cgi_input,已被重定向到 STDIN,读取 cgi_output 的管道输出到客户端,该管道输入是 STDOUT。接着关闭所有管道,等待子进程结束。
(10) 关闭与浏览器的连接,完成了一次 HTTP 请求与回应,因为 HTTP 是无连接的。
2. HTTP报文
首先来看一段tinyhttp接收到的报文:
GET / HTTP/1.1
Host: 1.117.220.169:8080
Connection: keep-alive
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
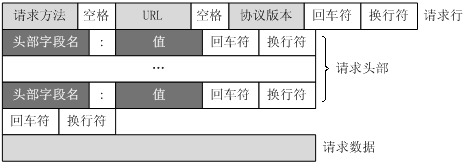
结构如下入所示,第一行是最重要的,称作请求行。 一般包含了这一份报文是要做什么,
-
请求头
请求行由请求方法字段、URL字段和HTTP协议版本字段3个字段组成,它们用空格分隔。例如,GET /index.html HTTP/1.1。
HTTP协议的请求方法有GET、POST、HEAD、PUT、DELETE、OPTIONS、TRACE、CONNECT。(1)GET
最常见的一种请求方式,当客户端要从服务器中读取文档时,当点击网页上的链接或者通过在浏览器的地址栏输入网址来浏览网页的,使用的都是GET方式。GET方法要求服务器将URL定位的资源放在响应报文的数据部分,回送给客户端。使用GET方法时,请求参数和对应的值附加在URL后面,利用一个问号(“?”)代表URL的结尾与请求参数的开始,传递参数长度受限制。例如,/index.jsp?id=100&op=bind,这样通过GET方式传递的数据直接表示在地址中,所以我们可以把请求结果以链接的形式发送给好友。不使用的条件:1. 传送私密数据时,因为在地址栏就能看到GET发送的数据,因此不适合用来传送私密数据。
2.不同的浏览器对地址有一定的字符限制,所以如果需要传送大量数据的时候,也不适合使用GET。(2)POST
对于上面提到的不适合使用GET方式的情况,可以考虑使用POST方式,因为使用POST方法可以允许客户端给服务器提供信息较多。POST方法将请求参数封装在HTTP请求数据中,以名称/值的形式出现,可以传输大量数据,这样POST方式对传送的数据大小没有限制,而且也不会显示在URL中。
(3) 其他
参考连接 -
请求头部
请求头部由关键字/值对组成,每行一对,关键字和值用英文冒号“:”分隔。请求头部通知服务器有关于客户端请求的信息,典型的请求头有:
User-Agent:产生请求的浏览器类型。
Accept:客户端可识别的内容类型列表。
Host:请求的主机名,允许多个域名同处一个IP地址,即虚拟主机。 -
空行
最后一个请求头之后是一个空行,发送回车符和换行符,通知服务器以下不再有请求头。 -
请求数据
请求数据不在GET方法中使用,而是在POST方法中使用。POST方法适用于需要客户填写表单的场合。与请求数据相关的最常使用的请求头是Content-Type和Content-Length。
2.1 小结
- 如果是GET方法,一般可能是请求静态资源,比如说静态网页、表单之类的,这些都是事先准备好的。
- 如果是POST方法,一般是请求CGI动态资源(CGI是什么会在后面指出)此时报文中会附带一个Content-length,这个是用来指出除去HTTP请求报文后,附带的资源长度。在TinyHttp中,并不是用get_line来获取。该资源一般都会交给CGI程序处理。
3. CGI是什么
贴一段百度百科的解释:

实际上这样写有点绕,简单理解就是CGI是网页的表单和你写的程序之间通信的一种协议。你写的CGI程序会处理网页发送的信息(例如POST中的请求数据),然后发送处理完的数据,把这个数据发送给客户端网页(所以发送的数据一般都是html格式。)
3.1 CGI程序把输出发送给网页
TinyHttp中给出了一段CGI的程序,代码如下:
#!/usr/bin/perl -Tw
use strict;
use CGI;
my($cgi) = new CGI;
print $cgi->header;
my($color) = "blue";
$color = $cgi->param('color') if defined $cgi->param('color');
print $cgi->start_html(-title => uc($color),
-BGCOLOR => $color);
print $cgi->h1("This is $color");
print $cgi->end_html;
此段代码阅读略微困难,根据首句可以知道使用perl语言写的,执行后是在网页上显示指定的颜色。便于理解,重新写了一个python语言的CGI程序:
#!/usr/bin/python
print "Content-type:text/htmlrnrn"
print '<html>'
print '<head>'
print '<title>Hello World - First CGI Program</title>'
print '</head>'
print '<body>'
print '<h2>Hello World! This is my first CGI program</h2>'
print '</body>'
print '</html>'
这一段的运行结果:

这一段程序就很简洁明了,也就明白了CGI是将程序的输出发送到网页上。
3.2 CGI接收和处理网页发送的数据
此处用一段TinyHttp附带的程序:
#!/usr/bin/python
#coding:utf-8
import sys,os
import urllib
length = os.getenv('CONTENT_LENGTH')
if length:
postdata = sys.stdin.read(int(length))
print "Content-type:text/htmln"
print '<html>'
print '<head>'
print '<title>POST</title>'
print '</head>'
print '<body>'
print '<h2> POST data </h2>'
print '<ul>'
for data in postdata.split('&'):
print '<li>'+data+'</li>'
print '</ul>'
print '</body>'
print '</html>'
else:
print "Content-type:text/htmln"
print 'no found'
运行
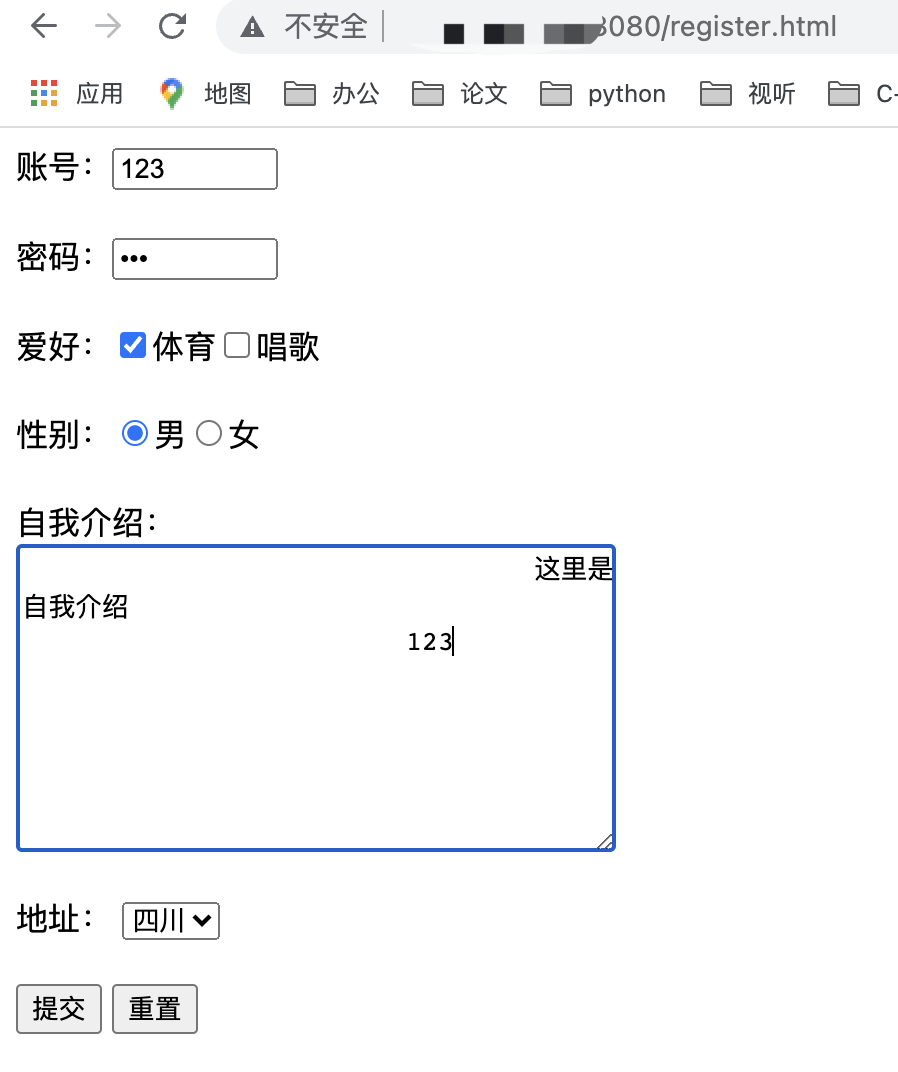
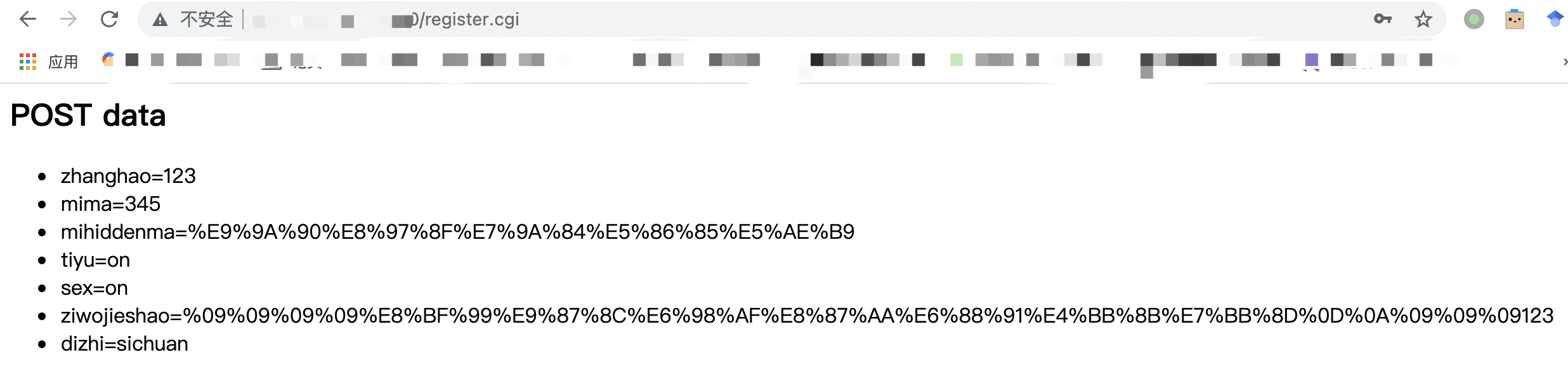
结合python代码,和网页的输出,可以知道POST请求发送的请求数据是什么样的。
那么CGI程序是如何做到上述功能的呢?
3.3 CGI的执行步骤
代码中用到了两个管道和一个子进程。创建两个管道的作用是为了将CGI程序的输入与STDIN绑定(重定向),CGI的输出与STDOUT绑定(重定向),如下图:
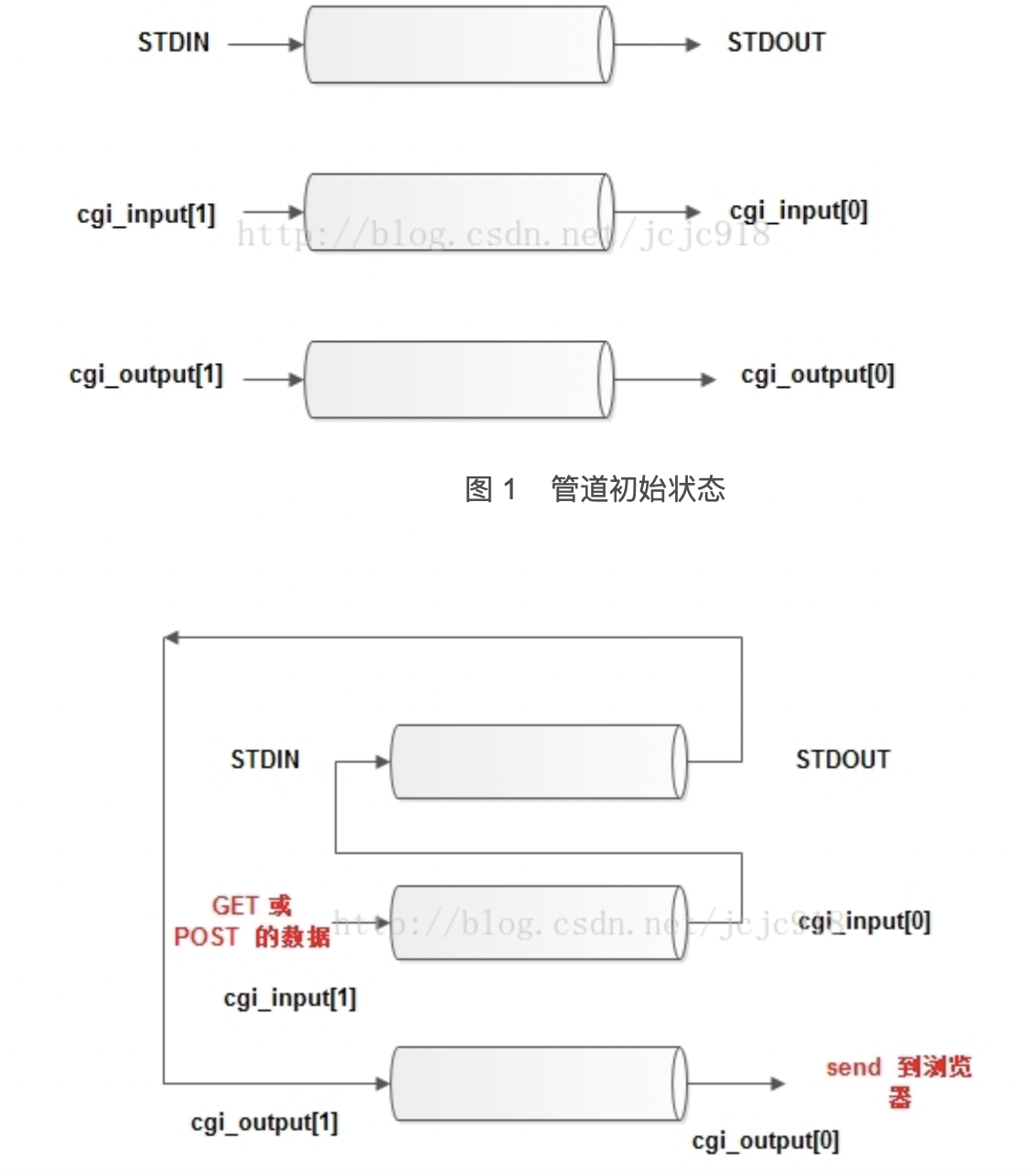
然后用两个进程,即可处理这一部分的数据。
注释代码:
if(pid == 0){
char meth_env[255];
char query_env[255];
char length_env[255];
dup2(cgi_output[1], 1);// 重定向为STDOUT
dup2(cgi_input[0], 0); // 重定向为STDIN
close(cgi_output[0]);
close(cgi_input[1]);
//CGI标准需要将请求的方法存储环境变量中,然后和cgi脚本进行交互
//存储REQUEST_METHOD
sprintf(meth_env, "REQUEST_METHOD=%s", method);
putenv(meth_env);
if (strcasecmp(method, "GET") == 0) {
//存储QUERY_STRING
sprintf(query_env, "QUERY_STRING=%s", query_string);
putenv(query_env);
}
else { /* POST */
//存储CONTENT_LENGTH
sprintf(length_env, "CONTENT_LENGTH=%d", content_length);
putenv(length_env);
}
execl(path, path, NULL);
exit(0);
}
else{
// 父进程
close(cgi_output[1]);
close(cgi_input[0]);
if(strcasecmp(method, "POST" ) == 0){
// 读取POST中的内容,并将其发送给CGI脚本
for(i = 0 ; i < content_length; i++){
recv(client, &c, 1, 0);
write(cgi_input[1], &c, 1);
}
}
// 读取CGI脚本文件执行的输出,并发送到客户端
while(read(cgi_output[0], &c, 1) > 0)
send(client, &c, 1, 0);
close(cgi_output[0]);
close(cgi_input[1]);
waitpid(pid, &status, 0);
}
最后
以上就是自信菠萝最近收集整理的关于Tinyhttp源码阅读笔记的全部内容,更多相关Tinyhttp源码阅读笔记内容请搜索靠谱客的其他文章。








发表评论 取消回复