文章目录
- 【题目链接】
- 【前言】
- 【题目大意】
- 【解题思路】
- 一、优先暴力
- 二、记忆化
- 三、unordered_map以及思维优化
- 四、乘法逆元(拓展内容)
- 【后记】
【题目链接】
https://nanti.jisuanke.com/t/42403
【前言】
不得不说这真的是一道毒瘤题,算法众多而且难想,不看题解想不出来系列
【题目大意】
有n个点,每个点都有能量ai,你的初始能量为a0,从0出发,每次你只能到达能量低于你自身能量的点,问你有多少种路径可以经过所有点
数据范围:
1 <= n <= 100000
0 <= ai <= 50
【解题思路】
一、优先暴力
首先很容易想到暴力dfs,可以设置三个参数,分别表示当前位置,当前剩余能量,以及剩余未路过的点(实际上当前位置可以忽略),遍历数组a,找到所有可以达到的点递归处理,然后考虑剪枝,我们可以将数组a排序,如果我们此时的rest < ai,那么显然后面的点均无法到达,直接return,最后加上各种卡常优化
代码如下:
#include <bits/stdc++.h>
using namespace std;
const int maxn = 100010;
const int mod = 1e9 + 7;
int a[maxn];
bool vis[maxn];
int n, ans = 0;
inline void dfs(register int pos, register int rest, register int cnt) {
if (cnt == n) {
ans = (ans + 1) % mod;
return;
}
for (register int i = 1; i <= n; ++i) {
if (vis[i]) continue;
if(rest < a[i]) return;
vis[i] = true;
dfs(i, rest + a[i], cnt + 1);
vis[i] = false;
}
}
int main() {
ios::sync_with_stdio(0);
cin.tie(0), cout.tie(0);
cin >> n;
for (register int i = 0; i <= n; ++i) cin >> a[i];
sort(a + 1, a + n + 1);
cout << dfs(a[0], 0) << endl;
}
但是时间复杂度为O(n2)显然会超时
二、记忆化
既然dfs超时,我们考虑能不能记忆化以减少重复计算,由于数据过大,不能使用二维数组,考虑用map + pair进行记忆化
代码如下:
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
#define endl 'n'
const int maxn = 100010;
const int mod = 1e9 + 7;
int a[maxn];
bool vis[maxn];
int n;
map<pair<int, int>, ll> dp; //记录每种情况的搜索结果
map<pair<int, int>, bool> ed; //记录此种情况是否被搜索过
inline ll dfs(register int rest, register int cnt)
{
if (cnt == n) return 1;
register pair<int, int> pp(rest, cnt);
register ll& x = dp[pp];
register bool& y = ed[pp];
if (y) return x;
y = true;
for (register int i = 1; i <= n; ++i) {
if (vis[i]) continue;
if (rest < a[i]) break;
vis[i] = true;
x = (x + dfs(rest + a[i], cnt + 1)) % mod;
vis[i] = false;
}
return x;
}
int main() {
ios::sync_with_stdio(0);
cin.tie(0), cout.tie(0);
cin >> n;
for (register int i = 0; i <= n; ++i) cin >> a[i];
sort(a + 1, a + n + 1);
cout << dfs(a[0], 0) << endl;
return 0;
}
本来以为这样就可以过了,但是1 / 76的正确率果然没有让我失望,仍然显示超时,感觉也没有什么优化空间了,只好上网搜索题解,搜了半天终于找到了一篇正解
https://blog.csdn.net/qq_43202683/article/details/104099322
但是你会发现这TM写的是啥,main函数里面那一大坨是什么东西,没事,咱先不管它
三、unordered_map以及思维优化
首先,正解里面的想法很聪明,由于ai最大只有50,而n却有100000,他并不记录ai而是将ai映射到数组中,用b[ai]记录ai出现的次数,那么dfs函数里面的for循环就可以不用从1 - n了,而是从0 - rest,这样枚举时间就大大下降了,然后,当我的rest大于50的时候,由于从一个点到达另一个点并不消耗任何能量,所以现在可以到达任意的未到达的点,即直接返回 (cnt!)
其次,正解里面用的不是map,而是unordered_map,百度告诉我unordered_map内部并不是红黑树而是Hash算法实现的查找结构,好像也有人叫hash_map,正解里面将参数Hash后再经过unordered_map的二次Hash保证了状态的唯一
正解里的Hash
for(int i = 50; i > 0; --i) ha = ha*sed+state.a[i];
if(mp.find(ha) != mp.end()) return mp[ha];
一开始我不理解为什么要这么做,于是我的程序变成了这个样子
#include <unordered_map>
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef unsigned long long ull;
#define endl 'n'
const int maxn = 100010;
const int mod = 1e9 + 7;
ll a[51];
ll m[maxn]; //记录阶乘
int n;
ll rem[maxn][51];
inline void Hash() { //保证每个状态唯一
int cnt = 0;
for (int i = 0; i <= 100000; ++i) {
for (int j = 0; j <= 50; ++j) {
rem[i][j] = ++cnt;
}
}
}
unordered_map<ull , ll> dp;
inline ll dfs(register int rest, register int cnt) {
if (!cnt) return 1;
if (rest >= 50) return m[cnt];
register ll hash = rem[rest][cnt];
if (dp.find(hash) != dp.end()) return dp[hash];
register ll res = 0;
for (register int i = 0; i <= rest; ++i) {
if (!a[i]) continue;
--a[i];
res = (res + (a[i] + 1) * dfs(rest + i, cnt - 1) % mod) % mod;
++a[i];
}
return dp[hash] = res;
}
int main() {
ios::sync_with_stdio(0);
cin.tie(0), cout.tie(0);
cin >> n;
register int rest;
cin >> rest;
m[0] = 1;
for (int i = 1; i <= 100000; ++i) {
m[i] = m[i - 1] * i % mod;
}
Hash();
for (register int i = 1; i <= n; ++i) {
register int x;
cin >> x;
++a[x];
}
cout << dfs(rest, n) << endl;
return 0;
}
该代码只跑了68ms,是不是很快,但是WA的不要不要的
这TM是为什么,陷入沮丧无法自拔,想了好久,发现由rest和cnt不能唯一代表一种状态,比如说有两条不同的路径可以到达相同的rest和cnt,但是由于dp[rest,cnt]已经记录过了,所以你不会继续往下搜索,导致结果错误
那么正解提供的Hash方法为什么可以呢?
注意看这句话
for(int i = 50; i > 0; --i) ha = ha*sed+state.a[i];
这个Hash值记录了所有的ai,也就是说它将所有有可能影响该状态的参数统统参与了Hash值得计算,所以能够保证其状态的唯一性
好了,略微修改一下,代码长这个样子:
#include <unordered_map>
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef unsigned long long ull;
#define endl 'n'
const int maxn = 100010;
const int mod = 1e9 + 7;
ll a[51];
ll m[maxn];
ull seed = 131;
int n;
unordered_map<ull , ll> dp;
inline ll dfs(register int rest, register int cnt) {
if (cnt == n) return 1;
if (rest >= 50) return m[n - cnt];
register ull hash = 0;
for (int i = 50; i >= 0; --i) hash = hash * seed + a[i]; //唯一修改处
if (dp.find(hash) != dp.end()) return dp[hash];
register ll res = 0;
for (register int i = 0; i <= rest; ++i) {
if (!a[i]) continue;
--a[i];
res = (res + ((a[i] + 1) * dfs(rest + i, cnt + 1) + mod) % mod) % mod;
++a[i];
}
return dp[hash] = res;
}
int main() {
ios::sync_with_stdio(0);
cin.tie(0), cout.tie(0);
cin >> n;
register int rest;
cin >> rest;
m[0] = 1;
for (int i = 1; i <= 100000; ++i) {
m[i] = (m[i - 1] * i + mod) % mod;
}
for (register int i = 1; i <= n; ++i) {
register int x;
cin >> x;
++a[x];
}
cout << dfs(rest, 0) << endl;
return 0;
}
这次,我满怀信心的又交了一次,mdTLE,险些弃题,冷静下来,分析正解,发现它将所有ai = 0的点从dfs中除去了,想了想,发现确实ai = 0对于答案的贡献是可以推导出来的
假设numof(ai == 0) = z,ansof(dfs) = res,那么
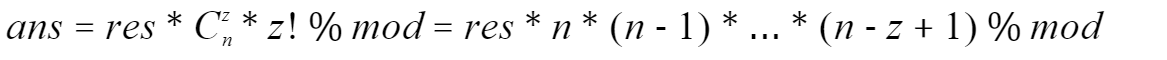
应该很好理解,能经过所有点的路径应该是1 - n的一个排列,那么我现在将所有的ai = 0插入到这条路径中一共有 Czn * z! 条不同的插法,然后将这个值乘上res就是答案了,化简一下就是上面的式子
最后我们只要将res乘上n * n - 1 * … * (n - z + 1)就可以得到答案
那么现在代码变成了这个样子:
#include <unordered_map>
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef unsigned long long ull;
#define endl 'n'
const int maxn = 100010;
const int mod = 1e9 + 7;
ll a[51];
ll fac[maxn];
ull seed = 131;
unordered_map<ull, ll> dp;
inline ll dfs(register int rest, register int cnt) {
if (!cnt) return 1;
if (rest >= 50) return fac[cnt];
register ull hash = 0;
for (int i = 50; i >= 0; --i) hash = hash * seed + a[i];
if (dp.find(hash) != dp.end()) return dp[hash];
register ll res = 0;
for (register int i = 1; i <= rest; ++i) {
if (!a[i]) continue;
--a[i];
res = (res + (a[i] + 1) * dfs(rest + i, cnt - 1) % mod) % mod;
++a[i];
}
return dp[hash] = res;
}
int main() {
ios::sync_with_stdio(0);
cin.tie(0), cout.tie(0);
register int n, rest;
cin >> n >> rest;
fac[0] = 1;
for (register int i = 1; i <= n; ++i) {
fac[i] = fac[i - 1] * i % mod;
}
register int zero = 0, num = 0;
for (register int i = 1; i <= n; ++i) {
register int x;
cin >> x;
if (!x) ++zero; //单独记录x = 0
else ++a[x], ++num;
}
register ll ans = dfs(rest, num); //由于去除了x = 0,那么dfs的总点数也就不是n了
for (int i = n; i >= n - zero + 1; --i) {
ans = (ans * i) % mod;
}
cout << ans << endl;
return 0;
}
呼,长呼一口气,代码写到这里终于AC了,真是历经千辛万苦
但是正解里main函数前面那一大坨是什么?
四、乘法逆元(拓展内容)
请先自行百度何为乘法逆元
乘法逆元的求法(5种)
正解中求n * n - 1 * … * (n - z + 1)的方法并不是low到爆的for循环,而是巧妙运用了乘法逆元的特性,应该是数论里面的一个结论
首先我们可以求出 (i!) % mod= fac[i],然后求出 ((n!) % mod)-1 = ifac[n],那么其递推式为
ifac[i] = ifac[i + 1] * (i + 1) % mod = ((i + 1)! % mod)-1 * (i + 1) % mod = (i! % mod)-1 = ifac[i]
那么n * n - 1 * … * (n - z + 1) % mod= (n! % mod) * ((n - z)! % mod)-1 = fac[n] * ifac[n - z]
是不是和正解里的ans表达式有点相似
没错,正解main函数里面前面那一坨实际上就是在求1 - n在mod的下的阶乘和阶乘逆元
【后记】
终于写完了,不得不说这题是真的毒瘤,翻了南京赛的榜单发现这题果然没几个做出来的,写了一下午,咱也不敢问,咱也不敢说
最后
以上就是淡然棉花糖最近收集整理的关于2019 ICPC Asia Nanjing Regional I. Space Station题解的全部内容,更多相关2019内容请搜索靠谱客的其他文章。








发表评论 取消回复