这段时间学习了python和hadoop,主要用于数据处理方面,因此打算写几篇这方面的博客。不过不是我的原创,我也是利用前辈的工作展示给大家。把自己学到的东西,也是比较初级的东西展示给需要的同学。
首先说一说hadoop的安装和配置。这里我不打算把怎么配置怎么安装一步一步的说,我这里给出一些资料和视频,大家可以下载下来,视频里面详细讲述了如何安装和配置hadoop。
链接: http://pan.baidu.com/s/1kTxZxQJ 密码: 8974
该链接下包含了视频、以及视频中所用到的全部软件和视频笔记。
有了上面的资料,完全可以完成hadoop的安装和配置工作。下面就是使用eclipse进行开发。关于eclipse开发mapreduce,可以配置eclipse的mapreduce插件。我也给出链接如下:http://www.ithao123.cn/content-1384302.html
该链接下说明了如何编译hadoop的eclipse插件,然后把编译好的jar放在eclipse的plugins目录下即可。然后重新启动eclipse
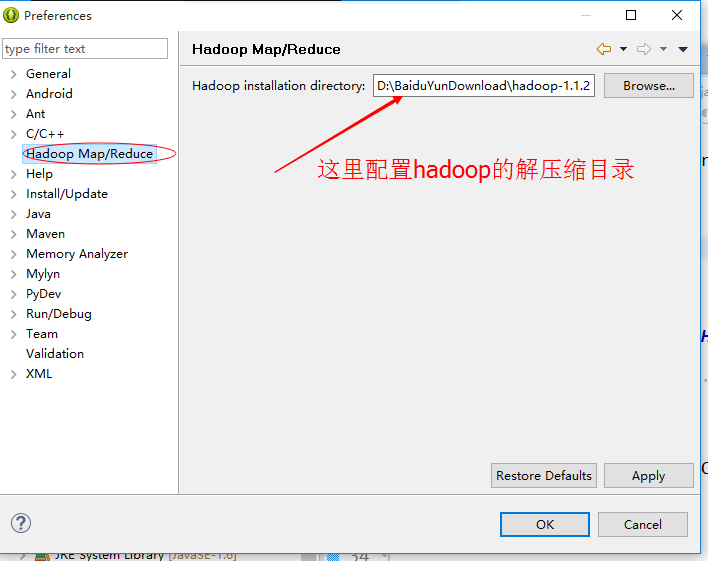
如图所示即可。
然后,在eclipse->window->showview
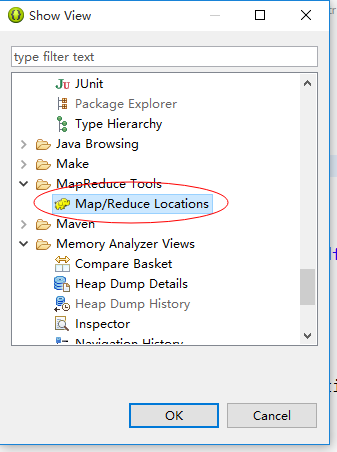
打开mapreduce locations
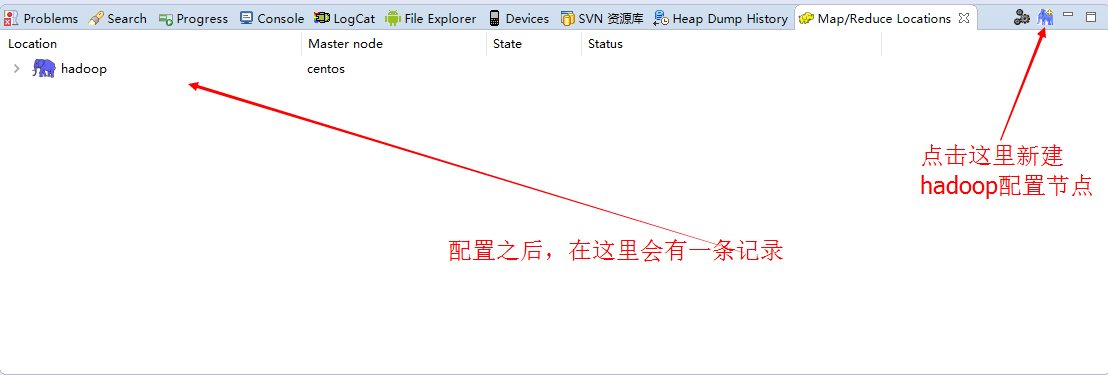
这里配置好之后就可以了。
这里我也给出视频的所使用的hadoop1.1.2版本的eclipse 插件下载:请猛戳这里!
到此,基本完成了所有的准备工作。
现在就在Windows下的eclipse中进行hadoop的开发。下面我把项目目录结构截图如下:
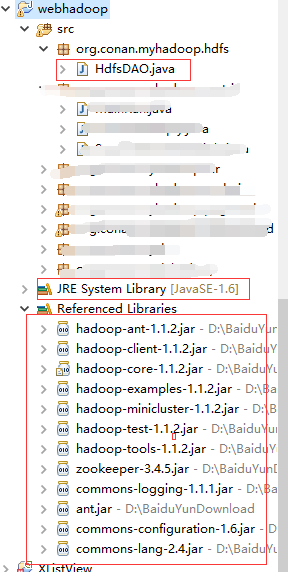
朦胧的地方是本节内容不需要的部分,配置的依赖包比较多,其中关于hadoop的jar包是必不可少的,commons的三个包也不可少。ant.jar在上面的下载资料中已经有了,可以单独下载下来添加进来。
以上的包在hadoop的解压目录里面都有。
创建目录:
/**
* 创建目录
* @param folder
* @throws IOException
*/
public void mkdirs(String folder) throws IOException {
Path path = new Path(folder);
FileSystem fs = FileSystem.get(URI.create(hdfsPath), conf);
if (!fs.exists(path)) {
fs.mkdirs(path);
System.out.println("Create: " + folder);
}
fs.close();
}FileSystem类是hadoop中的类,mkdirs方法创建目录。
类似于命令:
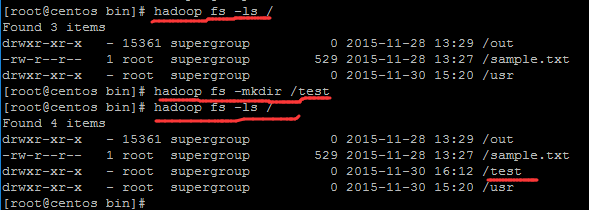
以上是命令行方式实现创建文件。实现在根目录下创建test文件夹
删除文件:
/**
* 删除文件或目录
* @param folder
* @throws IOException
*/
public void rmr(String folder) throws IOException {
Path path = new Path(folder);
FileSystem fs = FileSystem.get(URI.create(hdfsPath), conf);
fs.deleteOnExit(path);
System.out.println("Delete: " + folder);
fs.close();
}hadoop命令如下:
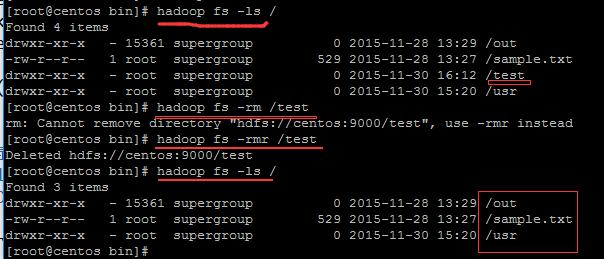
命令行方式删除文件。提示我删除目录使用命令:
hadoop fs -rmr 路径
方式删除目录。
重命名文件:
/**
* 重命名文件
* @param src
* @param dst
* @throws IOException
*/
public void rename(String src, String dst) throws IOException {
Path name1 = new Path(src);
Path name2 = new Path(dst);
FileSystem fs = FileSystem.get(URI.create(hdfsPath), conf);
fs.rename(name1, name2);
System.out.println("Rename: from " + src + " to " + dst);
fs.close();
}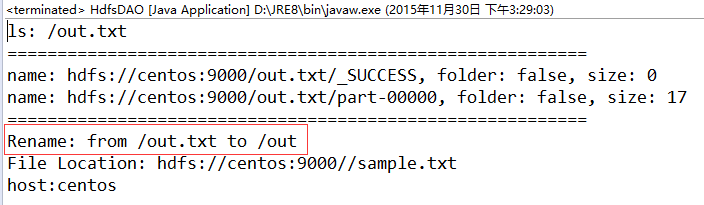
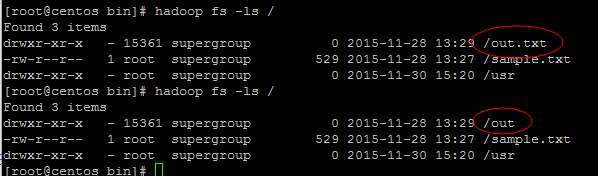
把out.txt文件重命名为out文件名。
遍历文件:
/**
* 遍历文件
* @param folder
* @throws IOException
*/
public void ls(String folder) throws IOException {
Path path = new Path(folder);
FileSystem fs = FileSystem.get(URI.create(hdfsPath), conf);
FileStatus[] list = fs.listStatus(path);
System.out.println("ls: " + folder);
System.out
.println("==========================================================");
for (FileStatus f : list) {
System.out.printf("name: %s, folder: %s, size: %dn", f.getPath(),
f.isDir(), f.getLen());
}
System.out
.println("==========================================================");
fs.close();
}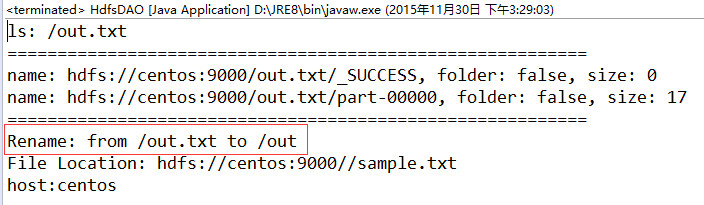
上面是遍历了out.txt文件夹下面的文件======分割线内为out.txt文件夹下的文件。
hadoop命令行结果:hadoop fs -ls /out

返回指定文件的位置以及主机信息:
/**
* Return an array containing hostnames, offset and size of
* portions of the given file.
*/
public void location() throws IOException {
String folder = hdfsPath + "/";
String file = "sample.txt";
FileSystem fs = FileSystem.get(URI.create(hdfsPath),
new Configuration());
FileStatus f = fs.getFileStatus(new Path(folder + file));
BlockLocation[] list = fs.getFileBlockLocations(f, 0, f.getLen());
System.out.println("File Location: " + folder + file);
for (BlockLocation bl : list) {
String[] hosts = bl.getHosts();
for (String host : hosts) {
System.out.println("host:" + host);
}
}
fs.close();
}结果:

本节内容关于HDFS的部分,只有一个类,算不得mapreduce的代码,全部代码如下:
package org.conan.myhadoop.hdfs;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.OutputStream;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.BlockLocation;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.mapred.JobConf;
/**
* 利用HDFS java API操作文件
*
*/
public class HdfsDAO {
//修改成自己的HDFS主机地址
private static final String HDFS = "hdfs://centos:9000/";
/**
* 两个构造器
* @param conf
*/
public HdfsDAO(Configuration conf) {
this(HDFS, conf);
}
public HdfsDAO(String hdfs, Configuration conf) {
this.hdfsPath = hdfs;
this.conf = conf;
}
private String hdfsPath;
private Configuration conf;
/**
* 测试方法入口
*/
public static void main(String[] args) throws IOException {
JobConf conf = config();
HdfsDAO hdfs = new HdfsDAO(conf);
/**
* 测试拷贝文件
*/
//
hdfs.copyFile("datafile/item.csv", "/tmp/new");
/**
* 测试遍历文件目录
*/
hdfs.ls("/out");
/**
* 测试重命名文件
*/
//
hdfs.rename("/out.txt", "/out");
/**
* 测试获取给定文件的主机名,偏移量,大小
*/
hdfs.location();
}
public static JobConf config() {
JobConf conf = new JobConf();
conf.setJobName("HdfsDAO");
//
conf.addResource("classpath:/hadoop/core-site.xml");
//
conf.addResource("classpath:/hadoop/hdfs-site.xml");
//
conf.addResource("classpath:/hadoop/mapred-site.xml");
return conf;
}
/**
* 创建目录
* @param folder
* @throws IOException
*/
public void mkdirs(String folder) throws IOException {
Path path = new Path(folder);
FileSystem fs = FileSystem.get(URI.create(hdfsPath), conf);
if (!fs.exists(path)) {
fs.mkdirs(path);
System.out.println("Create: " + folder);
}
fs.close();
}
/**
* 删除文件或目录
* @param folder
* @throws IOException
*/
public void rmr(String folder) throws IOException {
Path path = new Path(folder);
FileSystem fs = FileSystem.get(URI.create(hdfsPath), conf);
fs.deleteOnExit(path);
System.out.println("Delete: " + folder);
fs.close();
}
/**
* 重命名文件
* @param src
* @param dst
* @throws IOException
*/
public void rename(String src, String dst) throws IOException {
Path name1 = new Path(src);
Path name2 = new Path(dst);
FileSystem fs = FileSystem.get(URI.create(hdfsPath), conf);
fs.rename(name1, name2);
System.out.println("Rename: from " + src + " to " + dst);
fs.close();
}
/**
* 遍历文件
* @param folder
* @throws IOException
*/
public void ls(String folder) throws IOException {
Path path = new Path(folder);
FileSystem fs = FileSystem.get(URI.create(hdfsPath), conf);
FileStatus[] list = fs.listStatus(path);
System.out.println("ls: " + folder);
System.out
.println("==========================================================");
for (FileStatus f : list) {
System.out.printf("name: %s, folder: %s, size: %dn", f.getPath(),
f.isDir(), f.getLen());
}
System.out
.println("==========================================================");
fs.close();
}
/**
* 创建文件
* @param file
* @param content
* @throws IOException
*/
public void createFile(String file, String content) throws IOException {
FileSystem fs = FileSystem.get(URI.create(hdfsPath), conf);
byte[] buff = content.getBytes();
FSDataOutputStream os = null;
try {
os = fs.create(new Path(file));
os.write(buff, 0, buff.length);
System.out.println("Create: " + file);
} finally {
if (os != null)
os.close();
}
fs.close();
}
/**
* 拷贝文件到HDFS
* @param local
* @param remote
* @throws IOException
*/
public void copyFile(String local, String remote) throws IOException {
FileSystem fs = FileSystem.get(URI.create(hdfsPath), conf);
fs.copyFromLocalFile(new Path(local), new Path(remote));
System.out.println("copy from: " + local + " to " + remote);
fs.close();
}
/**
* 从HDFS中下载文件到本地中
* @param remote
* @param local
* @throws IOException
*/
public void download(String remote, String local) throws IOException {
Path path = new Path(remote);
FileSystem fs = FileSystem.get(URI.create(hdfsPath), conf);
fs.copyToLocalFile(path, new Path(local));
System.out.println("download: from" + remote + " to " + local);
fs.close();
}
/**
* 查看文件中的内容
* @param remoteFile
* @return
* @throws IOException
*/
public String cat(String remoteFile) throws IOException {
Path path = new Path(remoteFile);
FileSystem fs = FileSystem.get(URI.create(hdfsPath), conf);
FSDataInputStream fsdis = null;
System.out.println("cat: " + remoteFile);
OutputStream baos = new ByteArrayOutputStream();
String str = null;
try {
fsdis = fs.open(path);
IOUtils.copyBytes(fsdis, baos, 4096, false);
str = baos.toString();
} finally {
IOUtils.closeStream(fsdis);
fs.close();
}
System.out.println(str);
return str;
}
//返回给定文件的位置
/**
* Return an array containing hostnames, offset and size of
* portions of the given file.
*/
public void location() throws IOException {
String folder = hdfsPath + "/";
String file = "sample.txt";
FileSystem fs = FileSystem.get(URI.create(hdfsPath),
new Configuration());
FileStatus f = fs.getFileStatus(new Path(folder + file));
BlockLocation[] list = fs.getFileBlockLocations(f, 0, f.getLen());
System.out.println("File Location: " + folder + file);
for (BlockLocation bl : list) {
String[] hosts = bl.getHosts();
for (String host : hosts) {
System.out.println("host:" + host);
}
}
fs.close();
}
}
以上内容,并非我的原创,代码来源地址:https://github.com/bsspirit/maven_hadoop_template
该项目下包含了很多代码实例,本文中的hdfs操作,只是其中之一。我这里调试通过才有了这篇简单的文章。再次感谢作者!
学习~~!!
原作者本人的github地址:https://github.com/bsspirit
本项目的代码地址:请猛戳这里(欢迎关注我的GITHUB)
项目使用eclipse构建。方便易用,代码注释详细。
最后
以上就是炙热树叶最近收集整理的关于Hadoop-利用java API操作HDFS文件的全部内容,更多相关Hadoop-利用java内容请搜索靠谱客的其他文章。








发表评论 取消回复