???? 『精品学习专栏导航帖』
- ????最适合入门的100个深度学习实战项目????
- ????【PyTorch深度学习项目实战100例目录】项目详解 + 数据集 + 完整源码????
- ????【机器学习入门项目10例目录】项目详解 + 数据集 + 完整源码????
- ????【机器学习项目实战10例目录】项目详解 + 数据集 + 完整源码????
- ????Java经典编程100例????
- ????Python经典编程100例????
- ????蓝桥杯历届真题题目+解析+代码+答案????
- ????【2023王道数据结构目录】课后算法设计题C、C++代码实现完整版大全????
文章目录
- 一、引言
- 二、XGBoost算法
- 1.xgboost算法原理
- 2.构造目标函数
- 3.泰勒级数近似目标函数
- 4.将树结构引入目标函数
- 4.1 表示第k棵树的预测值
- 4.2 表示树的模型复杂度
- 4.3 参数化目标函数
- 5.贪心算法构建最优树
2021人工智能领域新星创作者,带你从入门到精通,该博客每天更新,逐渐完善机器学习各个知识体系的文章,帮助大家更高效学习。

一、引言
XGBoost是陈天奇等人开发的一个开源机器学习项目,高效地实现了GBDT算法并进行了算法和工程上的许多改进,它可以称为机器学习树模型中的王牌选手,是各大数据科学比赛的大杀器。
之前我们讲过GBDT,它采用的是数值优化的思维, 用的最速下降法去求解Loss Function的最优解, 其中用CART决策树去拟合负梯度,而XGboost用的解析的思维, 对Loss Function展开到二阶近似, 求得解析解, 用解析解作为Gain来建立决策树, 使得Loss Function最优.
下面我们具体讲解下xgboost算法的详细流程。
二、XGBoost算法
1.xgboost算法原理
xgboost算法同样也是Boosting架构的一种算法实现,同样符合模型函数:
f
m
(
x
)
=
∑
k
=
1
K
f
k
(
x
i
)
=
y
i
f_m(x)=sum_{k=1}^Kf_k(x_i)=y_i
fm(x)=k=1∑Kfk(xi)=yi
这里的K是指K棵树,就是K个基学习器,本文默认基学习器为树模型,其实现在XGBoost内部的基学习器可以使用linear学习器。
它和大部分机器学习模型结构差不多,也是定义了模型损失函数,然后进行优化,只不过是xgboost模型比较复杂,所以直接优化损失函数难度较大,所以才有了一系列的操作来进行简化。
xgboost算法主要有4个流程:
- 构造目标函数
- 将目标函数进行泰勒二阶展开
- 将目标函数参数化,将树结构引入目标函数
- 根据最优目标函数,构建最优树
2.构造目标函数
针对于该算法首先需要定义目标函数用来评估模型的好坏,在GBDT中我们的目标函数就是损失函数
L
(
y
i
,
y
)
L(y_i,y_)
L(yi,y) ,而XGBoost中加入了正则项,用来控制基学习器树的结构,目标函数定义如下:
o
b
j
=
∑
i
=
1
n
L
(
y
i
,
y
)
+
∑
k
=
1
K
Ω
(
f
k
)
obj=sum_{i=1}^nL(y_i,y)+sum_{k=1}^KOmega(f_k)
obj=i=1∑nL(yi,y)+k=1∑KΩ(fk)
- ∑ i = 1 n L ( y i , y ) sum_{i=1}^nL(y_i,y) ∑i=1nL(yi,y) :代表模型的损失函数,每个样本真实值与预测值之间的损失
- ∑ k = 1 K Ω ( f k ) sum_{k=1}^KOmega(f_k) ∑k=1KΩ(fk) :代表树的复杂度,可以用树的层数,叶子节点数进行评估等
我们构造目标函数就是为了用来评估模型的好坏,所以我们希望模型训练过程中这个目标函数的值越小越好。
由于XGBoost是Boosting架构的算法,所以同样遵循叠加式训练:
y
i
(
0
)
=
0
y
i
(
1
)
=
f
1
(
x
i
)
=
y
i
(
0
)
+
f
1
(
x
i
)
y
i
(
0
)
=
f
1
(
x
i
)
+
f
2
(
x
i
)
=
y
i
(
1
)
+
f
2
(
x
i
)
.
.
.
y
i
(
k
)
=
y
i
(
k
−
1
)
+
f
k
(
x
i
)
y_i^{(0)}=0\y_i^{(1)}=f_1(x_i)=y_i^{(0)}+f_1(x_i)\y_i^{(0)}=f_1(x_i)+f_2(x_i)=y_i^{(1)}+f_2(x_i)\...\y_i^{(k)}=y_i^{(k-1)}+f_k(x_i)
yi(0)=0yi(1)=f1(xi)=yi(0)+f1(xi)yi(0)=f1(xi)+f2(xi)=yi(1)+f2(xi)...yi(k)=yi(k−1)+fk(xi)
也就是k个模型的预测值等于前k个模型的预测值+当前正在训练第k个模型的预测值
所以此时我们的目标函数可以写为:
o
b
j
=
∑
i
=
1
n
L
(
y
i
,
y
)
+
∑
k
=
1
K
Ω
(
f
k
)
=
∑
i
=
1
n
L
(
y
i
,
y
i
k
)
+
∑
k
=
1
K
Ω
(
f
k
)
=
∑
i
=
1
n
L
(
y
i
,
y
i
k
−
1
+
f
k
(
x
i
)
)
+
∑
k
=
1
K
Ω
(
f
k
)
=
∑
i
=
1
n
L
(
y
i
,
y
i
k
−
1
+
f
k
(
x
i
)
)
+
∑
k
=
1
K
−
1
Ω
(
f
k
)
+
Ω
(
f
k
)
obj=sum_{i=1}^nL(y_i,y)+sum_{k=1}^KOmega(f_k)\=sum_{i=1}^nL(y_i,y_i^k)+sum_{k=1}^KOmega(f_k)\=sum_{i=1}^nL(y_i,y_i^{k-1}+f_k(x_i))+sum_{k=1}^KOmega(f_k)\=sum_{i=1}^nL(y_i,y_i^{k-1}+f_k(x_i))+sum_{k=1}^{K-1}Omega(f_k)+Omega(f_k)
obj=i=1∑nL(yi,y)+k=1∑KΩ(fk)=i=1∑nL(yi,yik)+k=1∑KΩ(fk)=i=1∑nL(yi,yik−1+fk(xi))+k=1∑KΩ(fk)=i=1∑nL(yi,yik−1+fk(xi))+k=1∑K−1Ω(fk)+Ω(fk)
这里解释一下,我们首先将算法模型y带入,然后获得了
∑
i
=
1
n
L
(
y
i
,
y
i
k
−
1
+
f
k
(
x
i
)
)
sum_{i=1}^nL(y_i,y_i^{k-1}+f_k(x_i))
∑i=1nL(yi,yik−1+fk(xi)) ,然后将后面基学习器树的复杂度进行拆分,拆成前k-1棵树的复杂度加上当前模型树的复杂度,又因为我们当时正在训练第k棵树,所以针对于前k棵树都是常量,所以现在我们的目标函数又可以写成:
m
i
n
∑
i
=
1
n
L
(
y
i
,
y
i
k
−
1
+
f
k
(
x
i
)
)
+
Ω
f
(
k
)
min sum_{i=1}^nL(y_i,y_i^{k-1}+f_k(x_i))+Omega f(k)
min i=1∑nL(yi,yik−1+fk(xi))+Ωf(k)
其中的
y
i
k
−
1
y_i^{k-1}
yik−1 是前k-1棵树模型的预测值,同样也为常数。
3.泰勒级数近似目标函数
根据上面我们就构造好了目标函数,但是为了将其进行简化,我们将其进行泰勒二阶展开
泰勒二阶展开式一般形式如下:
f
(
x
+
Δ
x
)
=
f
(
x
)
+
f
′
(
x
)
Δ
x
+
1
2
f
′
′
(
x
)
Δ
x
2
f(x+Delta x)=f(x)+f'(x)Delta x+frac{1}{2}f''(x)Delta x^2
f(x+Δx)=f(x)+f′(x)Δx+21f′′(x)Δx2
此时我们定义:
f
(
x
+
Δ
x
)
=
L
(
y
i
,
y
i
k
−
1
+
f
k
(
x
i
)
)
f(x+Delta x)=L(y_i,y_i^{k-1}+f_k(x_i))
f(x+Δx)=L(yi,yik−1+fk(xi))
那么就对应:
x
=
y
i
k
−
1
Δ
x
=
f
k
(
x
i
)
x=y_i^{k-1}\Delta x=f_k(x_i)
x=yik−1Δx=fk(xi)
按照泰勒公式的一般形式将其带入得到:
∑
i
=
1
n
L
(
y
i
,
y
i
k
−
1
+
f
k
(
x
i
)
)
+
Ω
f
(
k
)
=
∑
i
=
1
n
[
L
(
y
i
,
y
i
k
−
1
)
+
∂
L
(
y
i
,
y
i
k
−
1
)
∂
y
i
k
−
1
f
k
(
x
i
)
+
1
2
∂
L
(
y
i
,
y
i
k
−
1
)
∂
2
y
i
k
−
1
f
k
2
(
x
i
)
]
+
Ω
(
f
k
)
=
∑
i
=
1
n
[
L
(
y
i
,
y
i
k
−
1
)
+
g
i
f
k
(
x
i
)
+
1
2
h
i
f
k
2
(
x
i
)
]
+
Ω
(
f
k
)
sum_{i=1}^nL(y_i,y_i^{k-1}+f_k(x_i))+Omega f(k)\=sum_{i=1}^n[L(y_i,y_i^{k-1})+frac{partial L(y_i,y_i^{k-1})}{partial y_i^{k-1}}f_k(x_i)+frac{1}{2}frac{partial L(y_i,y_i^{k-1})}{partial^2y_i^{k-1}}f^2_k(x_i)]+Omega(f_k)\=sum_{i=1}^n[L(y_i,y_i^{k-1})+g_if_k(x_i)+frac{1}{2}h_if^2_k(x_i)]+Omega(f_k)
i=1∑nL(yi,yik−1+fk(xi))+Ωf(k)=i=1∑n[L(yi,yik−1)+∂yik−1∂L(yi,yik−1)fk(xi)+21∂2yik−1∂L(yi,yik−1)fk2(xi)]+Ω(fk)=i=1∑n[L(yi,yik−1)+gifk(xi)+21hifk2(xi)]+Ω(fk)
定义:
g
i
=
∂
L
(
y
i
,
y
i
k
−
1
)
∂
y
i
k
−
1
h
i
=
∂
L
(
y
i
,
y
i
k
−
1
)
∂
2
y
i
k
−
1
g_i=frac{partial L(y_i,y_i^{k-1})}{partial y_i^{k-1}}\h_i=frac{partial L(y_i,y_i^{k-1})}{partial^2y_i^{k-1}}
gi=∂yik−1∂L(yi,yik−1)hi=∂2yik−1∂L(yi,yik−1)
因为我们的
g
i
g_i
gi 和
h
i
h_i
hi 都是和前k-1个学习器相关,所以都为常数,那么简化后的目标函数就为:
m
i
n
∑
i
=
1
n
[
L
(
y
i
,
y
i
k
−
1
)
+
g
i
f
k
(
x
i
)
+
1
2
h
i
f
k
2
(
x
i
)
]
+
Ω
(
f
k
)
min sum_{i=1}^n[L(y_i,y_i^{k-1})+g_if_k(x_i)+frac{1}{2}h_if^2_k(x_i)]+Omega(f_k)
min i=1∑n[L(yi,yik−1)+gifk(xi)+21hifk2(xi)]+Ω(fk)
由于
L
(
y
i
,
y
i
k
−
1
)
L(y_i,y_i^{k-1})
L(yi,yik−1) 为常数,与优化第k棵树无关,可以省略:
m
i
n
∑
i
=
1
n
[
g
i
f
k
(
x
i
)
+
1
2
h
i
f
k
2
(
x
i
)
]
+
Ω
(
f
k
)
min sum_{i=1}^n[g_if_k(x_i)+frac{1}{2}h_if^2_k(x_i)]+Omega(f_k)
min i=1∑n[gifk(xi)+21hifk2(xi)]+Ω(fk)
4.将树结构引入目标函数
到了现在我们就获得了简化后的目标函数,但是你会发现函数中的 f k ( x i ) f_k(x_i) fk(xi) 和 Ω ( f k ) Omega(f_k) Ω(fk) 都还是位置的,所以我们需要将其参数化表示,这样我们才可以使用一些方法进行优化,我们就需要考虑使用一些符号表达式来表示这两个未知量。
4.1 表示第k棵树的预测值
首先针对于 f k ( x i ) f_k(x_i) fk(xi) ,它是第k棵树对第i个样本的预测值,那么我们应该怎样表示这个预测值呢?
为了表示它,我们引入了3个变量,分别是:
1. w w w:代表每个叶节点的值,就是预测值
2. q ( x ) q(x) q(x) :代表样本x落在哪个叶子节点上
3. I j I_j Ij :代表第j个节点上有那些样本
为了很好描述这几个变量,我们用幅图描述一下:
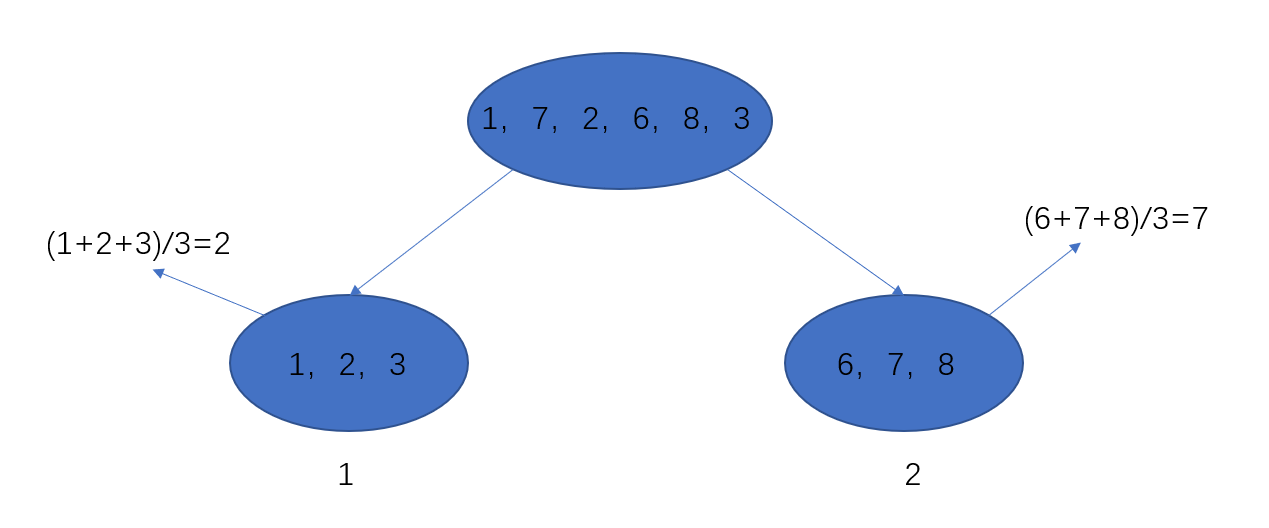
针对于这幅图,我们可以看到存在两个叶子节点,分别为1、2,每个节点的值为2和7,所以用上面三个变量表示:
- w 1 = 2 w 2 = 7 w_1=2quad w_2=7 w1=2w2=7
- q ( x 1 ) = 1 q ( x 8 ) = 2 q ( x 3 ) = 1 q(x_1)=1quad q(x_8)=2quad q(x_3)=1 q(x1)=1q(x8)=2q(x3)=1
- w q ( x 3 ) = 1 w_{q(x_3)}=1 wq(x3)=1
- I 1 = { 1 , 2 , 3 } I 2 = { 6 , 7 , 8 } I_1={1,2,3}quad I_2={6,7,8} I1={1,2,3}I2={6,7,8}
那么我们第k棵树的预测值就可以写成 f k ( x i ) = w q ( x i ) f_k(x_i)=w_{q(x_i)} fk(xi)=wq(xi)
4.2 表示树的模型复杂度
上面的目标函数中我们添加了正则项用来防止模型过拟合,那么针对于树模型,有哪些参数可以定义模型的复杂度呢?
一般情况下,我们的树模型越深越茂密那么复杂度越高,或者叶子节点值越大模型复杂度越高
在xgboost算法的实现中,是采用下式来衡量模型复杂度的:
Ω
(
f
k
)
=
α
T
+
1
2
λ
∑
j
=
1
J
w
j
2
Omega(f_k)=alpha T+frac{1}{2}lambdasum_{j=1}^Jw^2_j
Ω(fk)=αT+21λj=1∑Jwj2
- T:代表叶子节点个数
- ∑ j = 1 J w j 2 sum_{j=1}^Jw^2_j ∑j=1Jwj2 :各个叶子节点值的求和
- α , λ alpha ,lambda α,λ :超参数,控制惩罚程度
4.3 参数化目标函数
解决了上面两个问题,接下来就是如何将刚才定义的变量带入目标函数,现在目标函数为:
m
i
n
∑
i
=
1
n
[
g
i
f
k
(
x
i
)
+
1
2
h
i
f
k
2
(
x
i
)
]
+
Ω
(
f
k
)
min sum_{i=1}^n[g_if_k(x_i)+frac{1}{2}h_if^2_k(x_i)]+Omega(f_k)
min i=1∑n[gifk(xi)+21hifk2(xi)]+Ω(fk)
将其带入,目标函数为:
∑
i
=
1
n
[
g
i
w
q
(
x
i
)
+
1
2
h
i
w
q
(
x
i
)
2
]
+
α
T
+
1
2
λ
∑
j
=
1
J
w
j
2
sum_{i=1}^n[g_iw_{q(x_i)}+frac{1}{2}h_iw^2_{q(x_i)}]+alpha T+frac{1}{2}lambda sum_{j=1}^Jw^2_j
i=1∑n[giwq(xi)+21hiwq(xi)2]+αT+21λj=1∑Jwj2
这个式子还可以进一步简化,我们观察上面我们还定义了一个
I
j
I_j
Ij 的变量还没有用到,现在就要使用,我们发现计算损失函数时是以样本索引来遍历的
∑
i
=
1
n
sum_{i=1}^n
∑i=1n 总共n个样本,那么我们能不能换种遍历方式,因为我们样本最终肯定是要落在叶子节点上的,所以我们按照每个叶子节点进行遍历,每个叶子节点样本之后就为所有的样本。
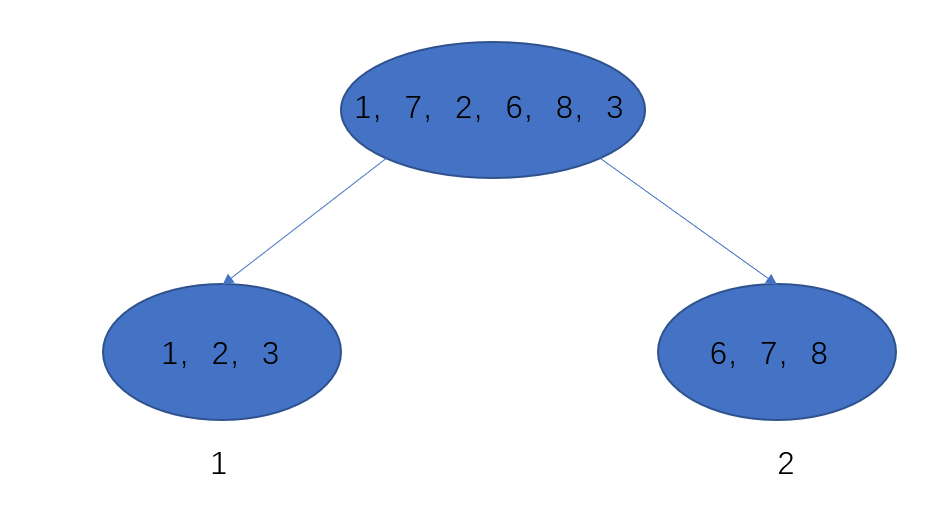
比如我们计算所有叶子节点1上样本的损失,按照上面定义的应该为:
g
1
w
q
(
x
1
)
+
g
2
w
q
(
x
2
)
+
g
3
w
q
(
x
3
)
g_1w_{q(x_1)}+g_2w_{q(x_2)}+g_3w_{q(x_3)}
g1wq(x1)+g2wq(x2)+g3wq(x3)
但是现在可以使用下式:
∑
i
∈
I
1
g
i
w
1
sum_{iin I_1}g_iw_1
i∈I1∑giw1
我们的
I
1
I_1
I1 代表所以在1叶子节点上的样本
所以此时目标函数就可以写为:
∑
j
=
1
J
[
(
∑
i
∈
I
j
g
i
)
w
j
+
(
1
2
∑
i
∈
I
j
h
i
)
w
j
2
]
+
α
T
+
1
2
λ
∑
j
=
1
J
w
j
2
=
∑
j
=
1
J
[
(
∑
i
∈
I
j
g
i
)
w
j
+
1
2
(
∑
i
∈
I
j
h
i
+
λ
)
w
j
2
]
+
α
T
sum_{j=1}^J[(sum_{iin I_j}g_i)w_j+(frac{1}{2}sum_{iin I_j}h_i)w^2_j]+alpha T+frac{1}{2}lambda sum_{j=1}^Jw^2_j\=sum_{j=1}^J[(sum_{iin I_j}g_i)w_j+frac{1}{2}(sum_{iin I_j}h_i+lambda)w^2_j]+alpha T
j=1∑J[(i∈Ij∑gi)wj+(21i∈Ij∑hi)wj2]+αT+21λj=1∑Jwj2=j=1∑J[(i∈Ij∑gi)wj+21(i∈Ij∑hi+λ)wj2]+αT
其中
J
J
J 代表叶子节点数,这里的
∑
i
∈
I
j
g
i
sum_{iin I_j}g_i
∑i∈Ijgi 和
∑
i
∈
I
j
h
i
+
λ
sum_{iin I_j}h_i+lambda
∑i∈Ijhi+λ 都为常数,所以我们用个符号代替:
G
j
=
∑
i
∈
I
j
g
i
H
j
+
λ
=
∑
i
∈
I
j
h
i
+
λ
G_j=sum_{iin I_j}g_i\ H_j+lambda=sum_{iin I_j}h_i+lambda
Gj=i∈Ij∑giHj+λ=i∈Ij∑hi+λ
我们观察目标函数
G
j
w
j
+
1
2
(
H
j
+
λ
)
w
j
2
G_jw_j+frac{1}{2}(H_j+lambda)w^2_j
Gjwj+21(Hj+λ)wj2 为一个二次函数,针对于一般的二次函数
y
=
a
x
2
+
b
x
+
c
y=ax^2+bx+c
y=ax2+bx+c ,我们取得极值点在对称轴处,为
x
∗
=
−
b
2
a
x^*=-frac{b}{2a}
x∗=−2ab ,所以此时我们目标函数的最优解为:
w
j
∗
=
−
∑
i
∈
I
j
g
i
2
1
2
(
∑
i
∈
I
j
h
i
+
λ
)
=
−
G
j
H
j
+
λ
w_j^*=-frac{sum_{iin I_j}g_i}{2frac{1}{2}(sum_{iin I_j}h_i+lambda)}=-frac{G_j}{H_j+lambda}
wj∗=−221(∑i∈Ijhi+λ)∑i∈Ijgi=−Hj+λGj
所以,当我们的树模型结构一定时,模型的目标函数最优为:
o
b
j
∗
=
−
1
2
∑
j
=
1
J
G
j
2
H
j
+
λ
+
α
T
obj^*=-frac{1}{2}sum_{j=1}^Jfrac{G^2_j}{H_j+lambda}+alpha T
obj∗=−21j=1∑JHj+λGj2+αT
注意前提是树结构已知时,模型的最优目标函数值才为上面的式子,但是针对于一棵树,模型的结构可能有很多种,我们如何获取一棵最优的树呢?
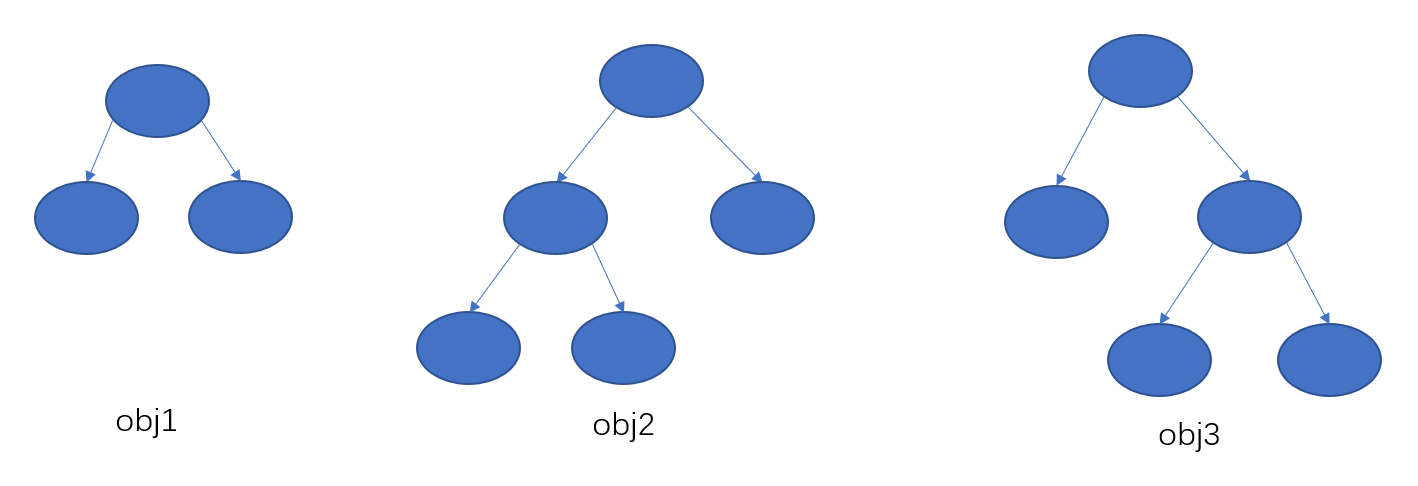
我们最容易想到,我们遍历所以可能的树结构,然后针对于不同棵树的最优obj,然后选取obj最小的一棵树,但是我们的树结构很复杂,这个复杂度是成指数的,显然不可能遍历所以可能结构的树,这就引出了贪心算法,去构建一颗最优的树。
5.贪心算法构建最优树
上面我们获得了给定一棵树模型,我们可以计算针对该棵树的最优目标函数值,但问题是我们现在正在生成第k棵树,我们不知道树的结构,然而又很显然不能遍历所以可能树的结构去计算obj,所以我们考虑使用贪心算法。
其实到了这里就和构造普通的cart决策树差不多了,都是选取不同的特征然后计算信息增益判断当前树的结构是否优秀,然而对于ID3中的决策树是使用了熵来进行评估不确定度的,CART中使用的是基尼系数的概念,我们这里不同的就是使用了上面定义的obj进行衡量,也就是判断一个特征是否是最优的切分特征,需要看切分后的obj是否小于切分前的obj。
我们选取每个特征,然后计算信息增益,这里信息增益使用
o
b
j
n
e
w
−
o
b
j
o
l
d
obj_{new}-obj_{old}
objnew−objold 。
o
b
j
=
−
1
2
∑
j
=
1
J
G
j
2
H
j
+
λ
+
α
T
obj=-frac{1}{2}sum_{j=1}^Jfrac{G^2_j}{H_j+lambda}+alpha T
obj=−21j=1∑JHj+λGj2+αT
下面举了例子如何计算信息增益:
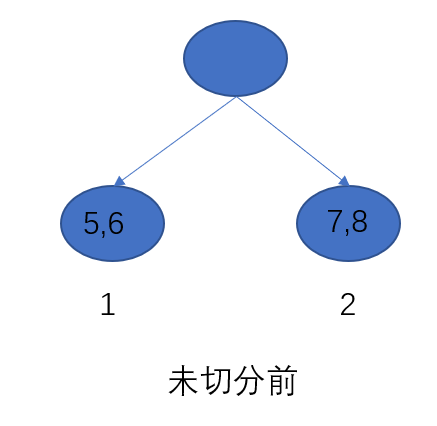
o
b
j
o
l
d
=
−
1
2
[
(
g
5
+
g
6
)
2
h
5
+
h
6
+
λ
+
(
g
7
+
g
8
)
2
h
7
+
h
8
+
λ
]
+
2
α
=
−
1
2
(
G
1
2
H
1
+
λ
+
G
2
2
H
2
+
λ
)
+
2
α
obj_{old}=-frac{1}{2}[frac{(g_5+g_6)^2}{h_5+h_6+lambda}+frac{(g_7+g_8)^2}{h_7+h_8+lambda}]+2alpha\=-frac{1}{2}(frac{G^2_1}{H_1+lambda}+frac{G^2_2}{H_2+lambda})+2alpha
objold=−21[h5+h6+λ(g5+g6)2+h7+h8+λ(g7+g8)2]+2α=−21(H1+λG12+H2+λG22)+2α
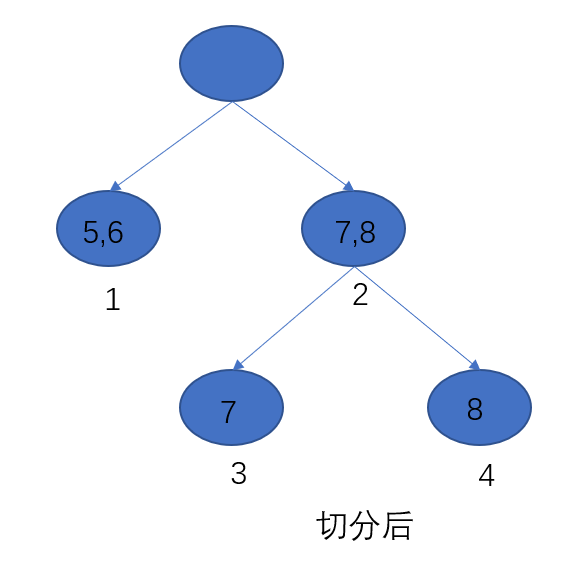
o
b
j
n
e
w
=
−
1
2
[
(
g
5
+
g
6
)
2
h
5
+
h
6
+
λ
+
(
g
7
)
2
h
7
+
λ
+
(
g
8
)
2
h
8
+
λ
]
+
3
α
=
−
1
2
(
G
1
2
H
1
+
λ
+
G
3
2
H
3
+
λ
+
G
4
2
H
4
+
λ
)
+
3
α
obj_{new}=-frac{1}{2}[frac{(g_5+g_6)^2}{h_5+h_6+lambda}+frac{(g_7)^2}{h_7+lambda}+frac{(g_8)^2}{h_8+lambda}]+3alpha\=-frac{1}{2}(frac{G^2_1}{H_1+lambda}+frac{G^2_3}{H_3+lambda}+frac{G^2_4}{H_4+lambda})+3alpha
objnew=−21[h5+h6+λ(g5+g6)2+h7+λ(g7)2+h8+λ(g8)2]+3α=−21(H1+λG12+H3+λG32+H4+λG42)+3α
所以我们的信息增益为:
o
b
j
n
e
w
−
o
b
j
o
l
d
=
1
2
[
G
L
2
H
L
+
λ
+
G
R
2
H
R
+
λ
+
(
G
L
+
G
R
)
2
H
L
+
H
R
+
λ
]
−
α
obj_{new}-obj_{old}=frac{1}{2}[frac{G^2_L}{H_L+lambda}+frac{G^2_R}{H_R+lambda}+frac{(G_L+G_R)^2}{H_L+H_R+lambda}]-alpha
objnew−objold=21[HL+λGL2+HR+λGR2+HL+HR+λ(GL+GR)2]−α
其中:
G
L
=
g
7
G
R
=
g
8
G_L=g_7\G_R=g_8
GL=g7GR=g8
我们是要获得最大信息增益,就需要遍历所以特征计算增益,选取增益大的进行切分构造树模型
m
a
x
o
b
j
n
e
w
−
o
b
j
o
l
d
maxquad obj_{new}-obj_{old}
maxobjnew−objold
根据这个原理我们就可以构造一棵使目标函数最小的树模型,然后按照这个逻辑,一次构造K棵树,然后最终将所有的树加权就是我们最终的模型:
f
K
(
x
)
=
f
K
−
1
(
x
)
+
f
k
(
x
)
=
∑
k
=
1
K
f
k
(
x
)
f_K(x)=f_{K-1}(x)+f_k(x)\=sum_{k=1}^Kf_k(x)
fK(x)=fK−1(x)+fk(x)=k=1∑Kfk(x)
写在最后
大家好,我是阿光,觉得文章还不错的话,记得“一键三连”哦!!!

最后
以上就是认真小天鹅最近收集整理的关于【机器学习】集成学习(Boosting)——XGBoost算法(理论+图解+公式推导)一、引言二、XGBoost算法的全部内容,更多相关【机器学习】集成学习(Boosting)——XGBoost算法(理论+图解+公式推导)一、引言二、XGBoost算法内容请搜索靠谱客的其他文章。








发表评论 取消回复