PCA算法及其应用
- 主成分分析(PCA)
- 主城成分分析(PCA):常见的降维方法,用于高维数据集的探索与可视化,还可以用作数据压缩和预处理。
- PCA 可以把具有相关性的高维变量合成为线性无关的低维变量,成为主成分,主成分能够保留原始数据的信息。
- 相关知识及术语
- 方差:是各个样本和样本均值的差的平方和的均值,用来度量一维数据的分散程度。
- 协方差:用于度量两个变量之间的线性相关性的程度,若两变量的协方差为0,则可认为二者线性无关。
- 协方差矩阵:协方差矩阵则是由变量的协方差值构成的矩阵(对称阵)。
- 特征向量和特征值 :描述数据集的非零向量,满足公式:
,,A是方阵,
- 方差:是各个样本和样本均值的差的平方和的均值,用来度量一维数据的分散程度。
- PCA原理:
- 矩阵的主成分就是其协方差矩阵对应的特征向量,按照对应的特征值得大小进行排序,最大的特征值就是第一主成分,其次是第二主成分,依次类推。
- sklearn库进行主成分分析,加载sklearn.decomposition.PCA降维,主要参数:
n_components:指定主成分的个数,即降维后数据的维度。
svd_solver:设置特征值分解方法,默认auto,可选full,arpack,randomized。
- 鸢尾花数据降维可视化实例
#实例:鸢尾花数据降维可视化 import matplotlib.pyplot as plt from sklearn.decomposition import PCA from sklearn.datasets import load_iris data=load_iris() y=data.target #数据集中的标签 x=data.data #数据集中的属性数据 pca=PCA(n_components=2) #降维后主成分数目 reduced_x=pca.fit_transform(x) #降维 red_x,red_y=[],[] blue_x,blue_y=[],[] green_x,green_y=[],[] #用于存储类别数据 for i in range(len(reduced_x)): if y[i]==0: red_x.append(reduced_x[i][0]) red_y.append(reduced_x[i][1]) elif y[i]==1: blue_x.append(reduced_x[i][0]) blue_y.append(reduced_x[i][1]) else: green_x.append(reduced_x[i][0]) green_y.append(reduced_x[i][1]) plt.scatter(red_x,red_y,c='r',marker='*') plt.scatter(blue_x,blue_y,c='b',marker='o') plt.scatter(green_x,green_y,c='g',marker='.') plt.show()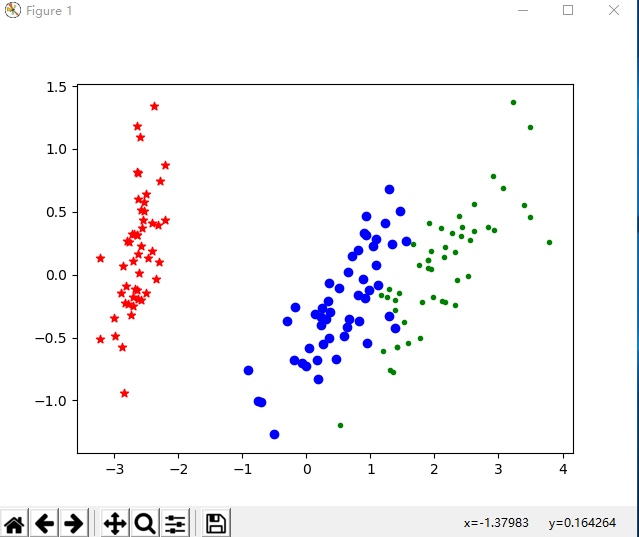
最后
以上就是忐忑音响最近收集整理的关于python-主成分分析-降维-PCA的全部内容,更多相关python-主成分分析-降维-PCA内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复