作为微软的粉丝,最后终于向Python低头了,拖了两三个月终于下定决心学习Python了。不过由于之前受到C/C#等语言影响的思维定式,前期有些东西理解起来还是很费了些功夫的。
零.先抄书:
1.Python是解释型语言:
计算机是不能够识别高级语言的,所以当我们运行一个高级语言程序的时候,就需要一个"翻译机”来从事把高级语言转变成计算机能读懂的机器语言的过程。这个过程分成两类,第一种是编译,第二种是解释。
编译型语言在程序执行之前,先会通过编译器对程序执行一个编译的过程,把程序转变成机器语言。运行时就不需要翻译,而直接执行就可以了。最典型的例子就是C语言。
解释型语言就没有这个编译的过程,而是在程序运行的时候,通过解释器对程序逐行作出解释,然后直接运行,最典型的例子是Ruby。
通过以上的例子,我们可以来总结一下解释型语言和编译型语言的优缺点,因为编译型语言在程序运行之前就已经对程序做出了"翻译”,所以在运行时就少掉了"翻译”的过程,所以效率比较高。但是我们也不能一概而论,一些解释型语言也可以通过解释器的优化来在对程序做出翻译时对整个程序做出优化,从而在效率上超过编译型语言。
此外,随着Java等基于虚拟机的语言的兴起,我们又不能把语言纯粹地分成解释型和编译型这两种。
用Java来举例,Java首先是通过编译器编译成字节码文件,然后在运行时通过解释器给解释成机器文件。所以我们说Java是一种先编译后解释的语言。
再换成C#,C#首先是通过编译器将C#文件编译成IL文件,然后在通过CLR将IL文件编译成机器文件。所以我们说C#是一门纯编译语言,但是C#是一门需要二次编译的语言。同理也可等效运用到基于.NET平台上的其他语言。
2.与大多数语言不同,python最具特色的就是使用缩进来表示代码块,不需要使用大括号 {} 。
缩进的空格数是可变的,但是同一个代码块的语句必须包含相同的缩进空格数。这也就是游标卡尺的梗的来源。
一.第一个Python程序:
先输出Hello World,然后调用排序函数对一个list进行冒泡的升序排序,尽管程序结构简单,但是包含了大多数的基础语法
## coding=utf-8
##冒泡排序与HelloWorld
list = [8,1,2,66,5,123]defBubbleSort():for i inrange(len(list)):for j inrange(i):if list[j] > list[j+1]:
list[j],list[j+1] = list[j+1],list[j]returnlistif __name__ == "__main__":print("hello world")
list=BubbleSort()print(list)
程序的运行结果如下:
hello world
[1, 2, 5, 8, 66, 123]
为了方便对比,我们再使用C#的代码实现同样的功能:
classProgram
{static void Main(string[] args)
{
Console.WriteLine("Hello World");
BubbleSort();
}private static voidBubbleSort()
{int[] data = { 8, 1, 2, 66, 5, 123};for (int i = 0; i < data.Length - 1; i++)
{for (int j = data.Length - 1; j > i; j--)
{if (data[j] > data[j - 1])
{
data[j]= data[j] + data[j - 1];
data[j- 1] = data[j] - data[j - 1];
data[j]= data[j] - data[j - 1];
}
}
}foreach (int i indata)
{
Console.Write(i+ ",");
}
Console.ReadLine();
}
二.Python程序的程序结构
从上面我们可以大概看出,一个完整的py程序结构大概如下:

我们知道,对于C/C++/C#等编程语言来说,程序的入口一定是main()函数,但是如果沿用这种思路来理解python的话就很容易踩坑。
Python使用缩进对齐组织代码的执行,所有没有缩进的代码(非函数定义和类定义),都会在载入时自动执行,这些代码,都可以可以认为是Python的main函数。每个文件(模块)都可以任意写一些没有缩进的代码,并且在载入时自动执行,为了区分主执行文件还是被调用的文件,Python引入了一个变量__name__,当文件是被调用时,__name__的值为模块名,当文件被执行时,__name__为'__main__'。因此,在之前的代码中,我们基本上可以使用这种方式来设置main函数的调用。
三.常量与变量
1 常量:
py并没有提供const关键字来定义变量,哭……
2 变量:
python的变量定义不需要声明类型,直接name=value 就可以了,比如:
a=1 ##整型变量ab=0.02 ##浮点型变量bstr= "Hello World" ##字符串cd=true ##布尔值d
py个人理解应该是故意在弱化变量的概念,当使用C#的思想去理解就出现了很大的偏差。
C/C++中的变量的概念是面向内存的,所以你要声明一个变量,表明空间大小,存储的格式(整数,浮点),以及一个永久不变的名字指向这个变量。而python只有name和object,比如a=1的语句,实际上做了三件微小的工作:
创建name a
创建object 1
将name a 关联到1这个object
然后,就能够直接使用a来调用1这个对象。至于强弱类型什么的,别纠结了吧……
py提供了type()函数来判断变量的类型,如:
a, b, c, d = 20, 5.5, True, 4+3j
print(type(a), type(b), type(c), type(d))
执行结果如下:
3 数值类型:
python支持int(整型),longint(长整型),float(浮点)和complex(负数)四种类型的数值。
//碎碎念一句浮点只有float精度真的够用么……
举例:
a=10 ##int
b=51924361L ##长整型,用大写L结尾
c=15.20 ## 浮点
d=1+2j ##复数,用a+bj或complex(a,b)表示
4 字符串:
str = "Hello World" ##定义字符串
str1 = str[0:4] ##截取字符串,从上标到下标,注意下标从0开始
转义符:
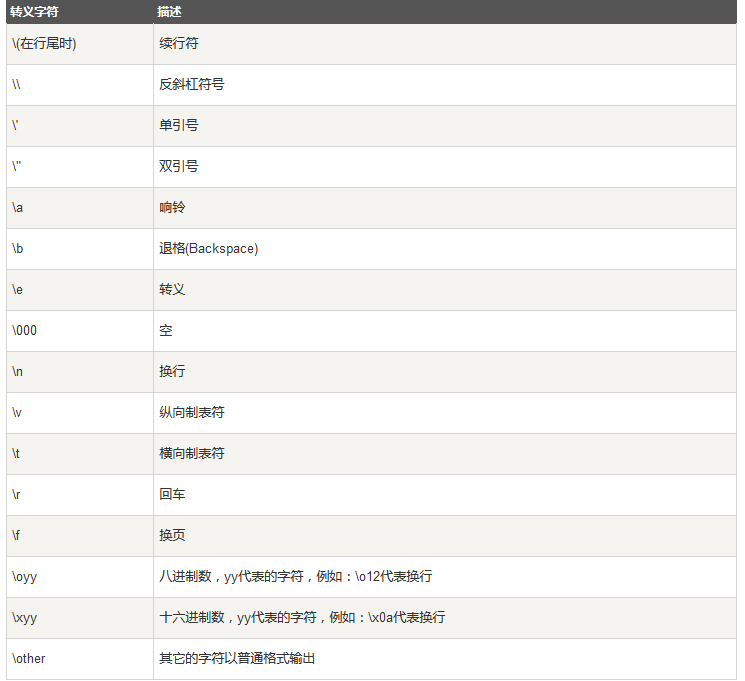
格式化输出:py的格式化输出用法与C语言的printf函数一样:
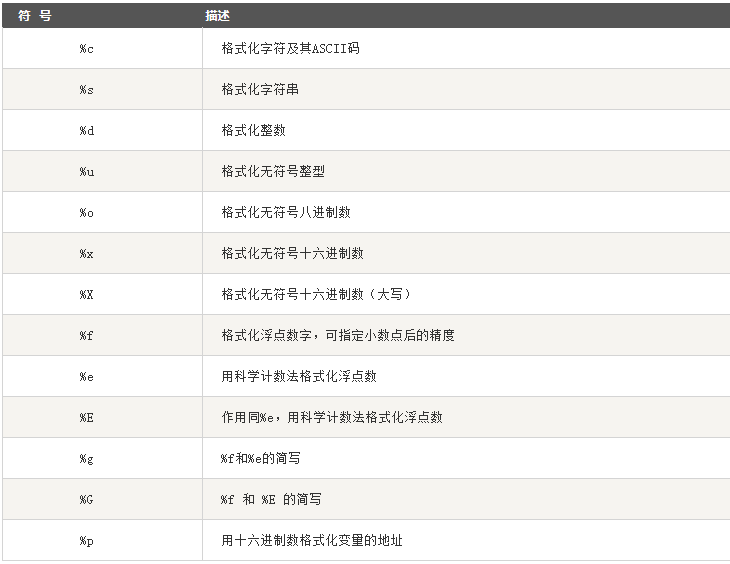
四.列表与字典:
1.列表:
与声明其他变量一样,python在定义列表时不需要
List list = new List();
直接赋值即可:
list1 = ['physics', 'chemistry', 1997, 2000]
list2= [1, 2, 3, 4, 5]
list3= ["a", "b", "c", "d"]
与字符串的索引一样,列表索引从0开始。列表可以进行截取、组合等。
常见的列表操作函数如下:

2.元组:元组类似于静态列表,其中的元素不能修改。
3.字典:字典是键值对的集合,声明字典时一样不需要定义字典类型,也不需要new操作:
dict = {'Alice': '2341', 'Beth': '9102', 'Cecil': '3258'}
PS:1.字典的键不能重复,同时键是不会发生变化的。
2.python中向字典中增加值无需使用add方法,直接操作其键值即可:
dict = {'Name': 'Zara', 'Age': 7, 'Class': 'First'}
dict['Age'] = 8; #更新值
dict['School'] = "DPS School"; #添加一个键值对
常见的字典函数如下:

最后
以上就是过时春天最近收集整理的关于python中的基础语法-Python学习笔记(Ⅰ)——Python程序结构与基础语法的全部内容,更多相关python中内容请搜索靠谱客的其他文章。








发表评论 取消回复