Pandas之DataFrame
- 1 DataFrame介绍
- 2 创建DataFrame
- 3 常用属性
- 4 访问数据
- 5 处理重复数据
- 6 删除数据
- 7 添加数据
- 8 修改数据
- 9 缺失值处理
- 10 分组
- 11 聚合
- 12 排序
- 13 统计
- 14 数据表关联
- 15 索引设置
- 16 数据的读取与存储
1 DataFrame介绍
DataFrame是一个类似于二维数组或表格(如excel)的对象,既有行索引,又有列索引
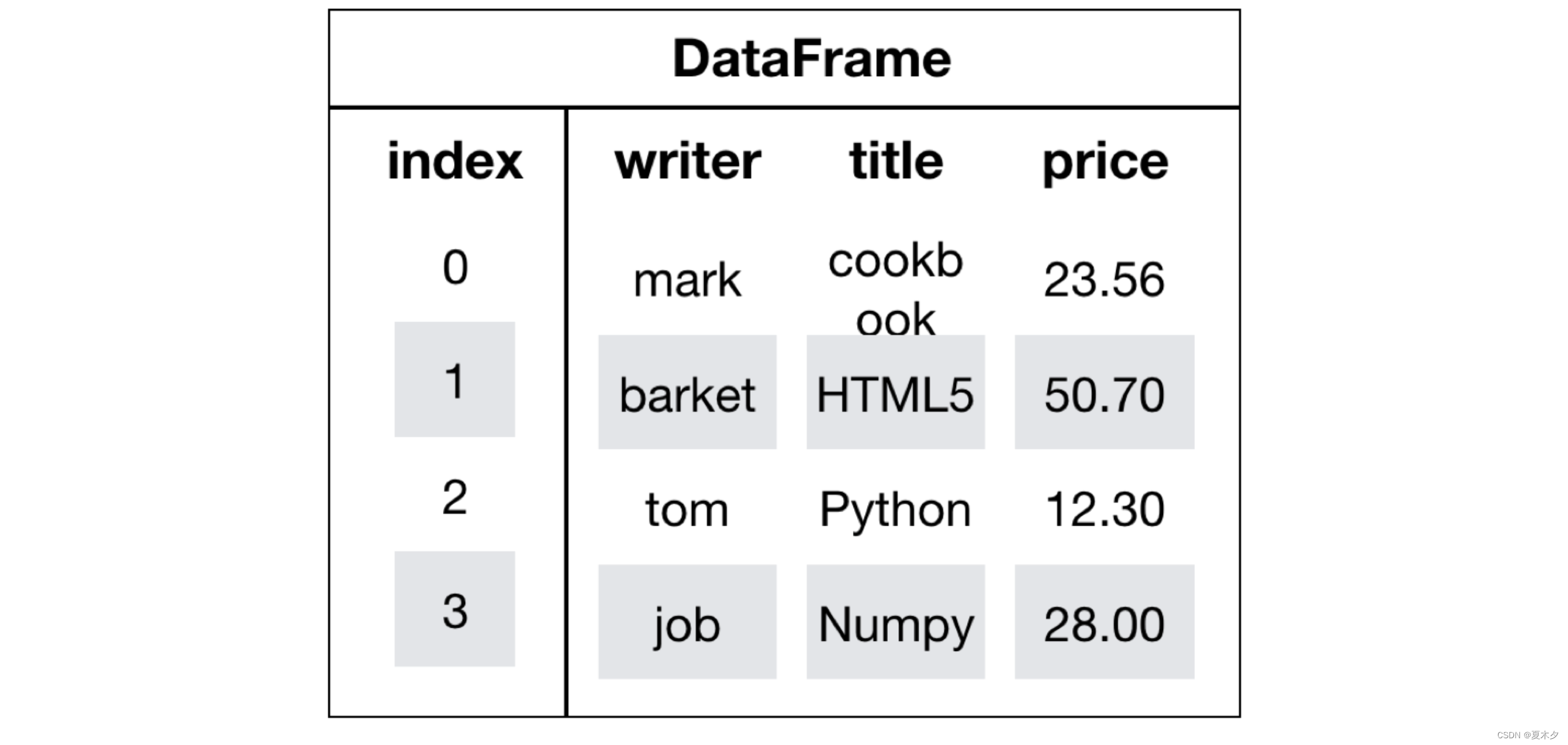
2 创建DataFrame
(1)从列表创建DataFrame
import pandas as pd
data = [1,2,3,4,5]
df = pd.DataFrame(data=data)
df

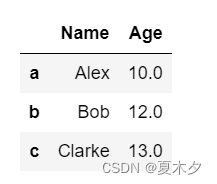
data = [['Alex',10],['Bob',12],['Clarke',13]]
df = pd.DataFrame(data,columns=['Name','Age'],index=['a','b','c'],dtype=float)
df
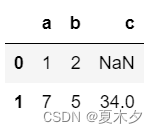
data=[{'a':1,'b':2},{'a':7,'b':5,'c':34}]
df = pd.DataFrame(data)
df
(2)从字典来创建DataFrame
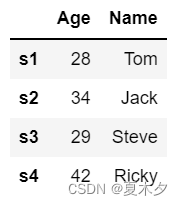
data = {'Name':['Tom', 'Jack', 'Steve', 'Ricky'],
'Age':[28,34,29,42]}
df = pd.DataFrame(data, index=['s1','s2','s3','s4'])
df
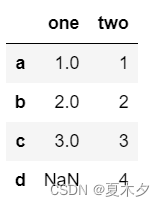
data = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
df = pd.DataFrame(data)
df
(3)导入外部文件创建DataFrame
df=pd.read_csv('./bikes.csv',sep=';')
3 常用属性
(1)查看前n行数据
df.head(n)
df.head() # 默认查看前5行
(2)查看后n行数据(默认后5行)
df.tail(n)
df.tail() # 默认查看后5行
(3)查看各列信息
df.info()
(4)查看数据形状
df.shape
(5)查看每一列的数据类型
df.dtypes
# 查看one这一列的数据类型
# df["one"].dtype
(6)查看数据值
df.values
(7)查看数据的列名
df.columns
(8)查看数据的索引
df.index
将索引转换为列使用reset_index()函数
- drop:bool,default False
- 删除索引并将其转化成列,默认是False:转化成列;True:删除的索引直接丢弃,不转化成列
- inplace:bool,defualt False
- 是否在原数据上做更改,默认False:不在源数据上做更改,此时有返回值DataFrame需要变量进行赋值;True无返回值
(9)查看行/列标签列表
df.axes
(10)判断空系列
# 如果系列为空,则返回True
df.empty
(11)返回底层数据的维数,默认定义:1
df.ndim
(12)返回基础数据中的元素数
df.size
4 访问数据
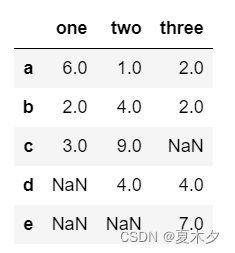
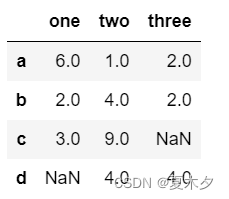
data = {'one' : pd.Series([6, 2, 3], index=['a', 'b', 'c']),
'two' : pd.Series([1, 4, 9, 4], index=['a', 'b', 'c', 'd']),
'three' : pd.Series([2, 2, 7, 4], index=['a', 'b', 'e', 'd'])}
df=pd.DataFrame(data)
df
对于loc选取行列数据, loc是select by label(name):
- 行根据行标签,也就是索引筛选,列根据列标签,列名筛选
- 如果选取的是所有行或者所有列,可以用
:代替- 行标签选取的时候,两端都包含,比如[0:5]指的是0,1,2,3,4,5
对于iloc选取行列数据,iloc是select by position,仅接受整数作为参数。
- iloc基于位置索引,简言之,就是第几行第几列,这里的行列都是从0开始的
- iloc的0:X中不包括X,只能到X-1
df.loc的第一个参数是行标签,第二个参数为列标签(可选参数,默认为所有列标签),两个参数既可以是列表也可以是单个字符,df.iloc同理
(1)行访问
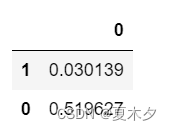
t=pd.DataFrame(np.random.rand(2),index=[1,0])
t
np.random.rand详细用法见:https://blog.csdn.net/qq_40130759/article/details/79535575
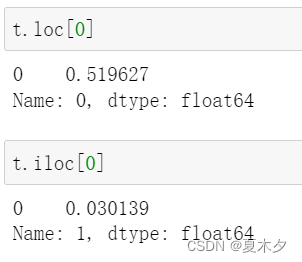
返回 df 位置索引为1和3的数据,即第二条和第四条数据
df.iloc[[1,3]]
df.loc[['b','d']]

df.iloc[[0,1],[0,1]]
df.loc[["a","b"],["one","two"]]

df.loc["a":"d"]
(2)列访问
# 查看one列数据
df['one']
# 查看one列的前3行数据
df['one'][:3]
# 查看one、two列数据
df[['one','two']]
(3)条件访问
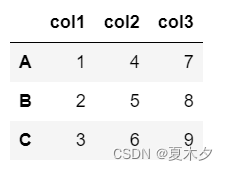
d={'col1':[1,2,3],'col2':[4,5,6],'col3':[7,8,9]}
d=pd.DataFrame(data=d,index=['A','B','C'])
d
① 直接筛选
直接使用列需要满足的条件,如果需要多个列同时满足条件,使用"&"符号连接即可;如果只需要某一列满足条件,则使用"|"连接多个列的条件。
# 返回col1列值大于1的数据
d[d['col1']>1]
# 返回col1列值等于1且col2列值等于4的数据
d[(d['col1'] == 1) & (d['col2']==4)]
② 使用query函数
# 查询col1列中数值为2的行记录
d.query('col1==2')
# 查询col1列数值小于col2列的行记录
d.query('col1 < col2')
# 等价于
d[d.col1 < d.col2]
③ 使用map函数
这个筛选方式和直接筛选唯一不同的就是,把筛选条件给隔离出来了
# 返回col1列值等于1且col2列值等于4的数据
a = d['col1'].map(lambda x : x==1)
b = d['col2'].map(lambda x : x==4)
some = d[a & b]
some
5 处理重复数据
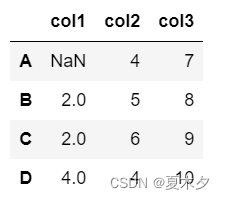
from numpy import NAN
d={'col1':[NAN,2,2,4],'col2':[4,5,6,4],'col3':[7,8,9,10]}
d=pd.DataFrame(data=d,index=['A','B','C','D'])
d
(1)检查是否有重复记录
① 某一列的数据是否唯一
# col1列的数据是否唯一
d.col1.is_unique # False,不唯一
# unique函数可以返回唯一值
unqiue=d.col1.unique()
unqiue # array([nan, 2., 4.])
# nunique函数返回的是唯一值的个数(不计空缺值)
d.col1.nunique() # 2
② 整个数据表是否有重复记录
DataFrame的duplicated方法返回一个布尔型Series,表示各行是否是重复行
d.duplicated()

is_unique与duplicated都可以用于判断是否存在重复记录,区别在于:
- is_unique:是Series的属性,即只能对系列应用该属性
- duplicated:是DataFrame的函数,Series和DataFrame都可以使用
(2)删除重复记录
drop_duplicates()
subset参数选择以哪个列为去重基准,默认所有的列。keep参数则是保留方式,first是保留第一个,删除后余重复值,last是删除前面,保留最后一个,默认firstinplace参数,布尔值,默认为False,指的是直接在原来数据上修改还是保留一个副本
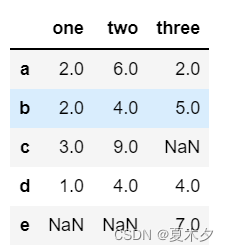
d = {'one' : pd.Series([2, 2, 3,1], index=['a', 'b', 'c','d']),
'two' : pd.Series([6, 4, 9, 4], index=['a', 'b', 'c', 'd']),
'three' : pd.Series([2, 5, 7, 4], index=['a', 'b', 'e', 'd'])}
df=pd.DataFrame(d)
df
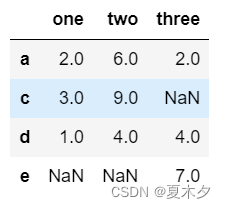
df.drop_duplicates(subset='two',keep='last')
# df.drop_duplicates(subset=["one","two"])
6 删除数据
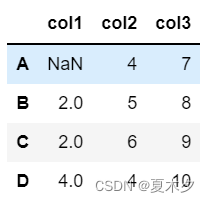
d={'col1':[NAN,2,2,4],'col2':[4,5,6,4],'col3':[7,8,9,10]}
d=pd.DataFrame(data=d,index=['A','B','C','D'])
d
(1)列删除
① del
del(d['col1'])
② pop
d.pop('col2')
注意:
del和pop进行删除操作时会改变原数据,另外pop会返回删除的数据
(2)行删除
d.drop('A') # 删除索引为A的行数据
d.drop(['A','B']) # 删除索引为A、B的行数据
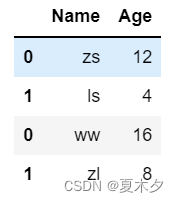
df = pd.DataFrame([['zs', 12], ['ls', 4]], columns = ['Name','Age'])
df2 = pd.DataFrame([['ww', 16], ['zl', 8]], columns = ['Name','Age'])
df = df.append(df2)
df
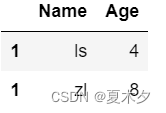
# 删除index为0的行
df.drop(0)
注意:对于
drop()删除,如果不加axis=1,则默认axis=0按照行号进行删除。如果不设置参数inplace=True,则只能在生成的新数据块中实现删除效果,而不能删除原有数据块的相应行。
7 添加数据
(1)添加列
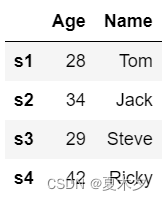
data = {'Name':['Tom', 'Jack', 'Steve', 'Ricky'],'Age':[28,34,29,42]}
df = pd.DataFrame(data, index=['s1','s2','s3','s4'])
df
① 直接添加新列
# 添加score列
df['score']=pd.Series([90, 80, 70, 60], index=['s1','s2','s3','s4'])
# 或者index=df.index
df
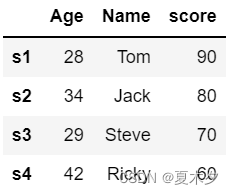
注意:添加列数据时,若行索引不是默认的,则需要指定index
② insert()
另外,Insert用于在DataFrame的指定位置中插入新的数据列。默认情况下新列是添加到末尾的,但可以更改位置参数,将新列添加到任何位置。
Dataframe.insert(loc, column, value, allow_duplicates=False)
参数作用:
loc: int型,表示插入位置在第几列;若在第一列插入数据,则 loc=0column: 给插入的列取名,如 column=‘新的一列’value:新列的值,数字、array、series等都可以allow_duplicates: 是否允许列名重复,选择Ture表示允许新的列名与已存在的列名重复
③ loc()
df.loc[:,新列名]=值
(2)添加行
df2 = pd.DataFrame([['ww', 16,77], ['zl', 8,99]], columns = ['Name','Age','score'],index=['s5','s6'])
df = df.append(df2)
df
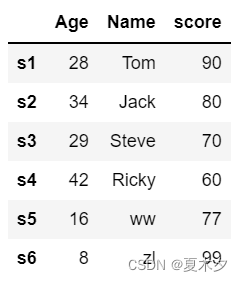
注意:即使原数据的行索引为默认值,添加行数据时也要按顺序指定索引,否则添加数据的行索引会默认重新从0开始
8 修改数据
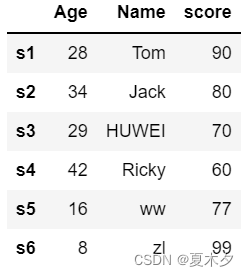
# 将Name列的第三行数据修改成“HUWEI”
df['Name'][2]='HUWEI'
df
9 缺失值处理
df=pd.DataFrame([[1,4,9],[NAN,NAN,NAN],[8,0,NAN]])
df
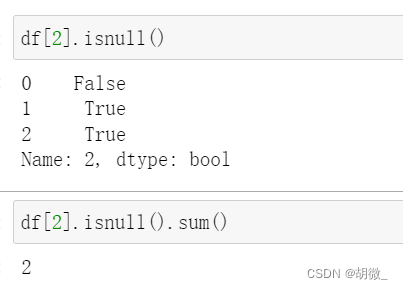
(0)查找缺失值
isnull()可以用于判断 dataframe 或者 series 的空值
notnull()判断非空值
空值包括
查找第3列是否有缺失值,有多少个缺失值
(1)删除缺失值
DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
# axis=0: 删除包含缺失值的行(默认)
df.dropna()
# axis=1: 删除包含缺失值的列
df.dropna(axis=1)
# how='all': 所有的值都缺失,才删除行或列
df.dropna(how='all')
# how=‘any’ :只要有缺失值出现,就删除该行或列
df.dropna(how='any')
(2)填充缺失值
fillna()
- 传入
method=" "重新索引时选择插值处理方式:method='ffill'或'pad'前向填充(看前一个是什么,它就填充什么)method='bfill'或'backfill'后向填充(看后一个是什么,它就填充什么)
- 传入
limit参数限制填充个数 - 传入
axis参数修改填充方向,默认axis=0纵向填充,axis=1横向填充 - 置
inplace=True改变原数据
10 分组
ipl_data = {'Team': ['Riders', 'Riders', 'Devils', 'Devils', 'Kings',
'kings', 'Kings', 'Kings', 'Riders', 'Royals', 'Royals', 'Riders'],
'Rank': [1, 2, 2, 3, 3,4 ,1 ,1,2 , 4,1,2],
'Year': [2014,2015,2014,2015,2014,2015,2016,2017,2016,2014,2015,2017],
'Points':[876,789,863,673,741,812,756,788,694,701,804,690]}
df = pd.DataFrame(ipl_data)
df
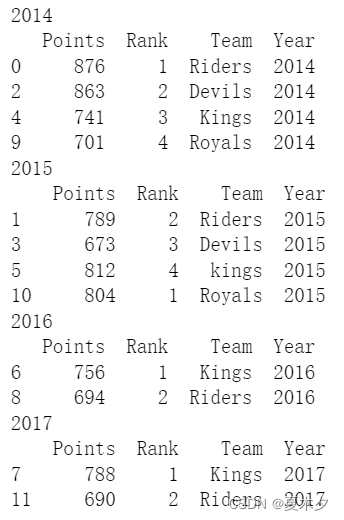
groupby返回可迭代对象,可以使用for循环遍历
grouped=df.groupby('Year')
grouped
# <pandas.core.groupby.DataFrameGroupBy object at 0x000001BD6977B3C8>
grouped.groups
"""
{2014: Int64Index([0, 2, 4, 9], dtype='int64'),
2015: Int64Index([1, 3, 5, 10], dtype='int64'),
2016: Int64Index([6, 8], dtype='int64'),
2017: Int64Index([7, 11], dtype='int64')}
"""
for year,group in grouped:
print(year)
print(group)
获得一个分组细节
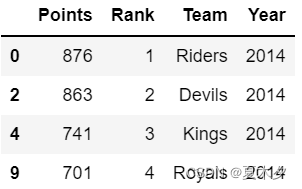
grouped.get_group(2014)
11 聚合
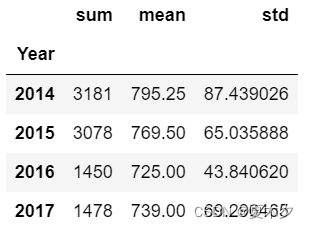
聚合每一年的分数之和、平均分、标准差
agg = grouped['Points'].agg([np.sum, np.mean, np.std])
agg
12 排序
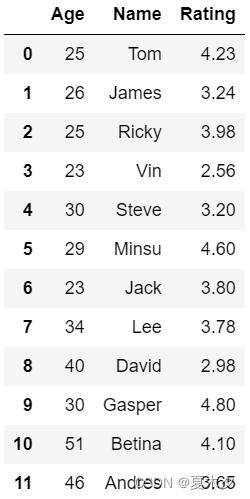
d = {'Name':pd.Series(['Tom','James','Ricky','Vin','Steve','Minsu','Jack',
'Lee','David','Gasper','Betina','Andres']),
'Age':pd.Series([25,26,25,23,30,29,23,34,40,30,51,46]),
'Rating':pd.Series([4.23,3.24,3.98,2.56,3.20,4.6,3.8,3.78,2.98,4.80,4.10,3.65])}
unsorted_df = pd.DataFrame(d)
unsorted_df
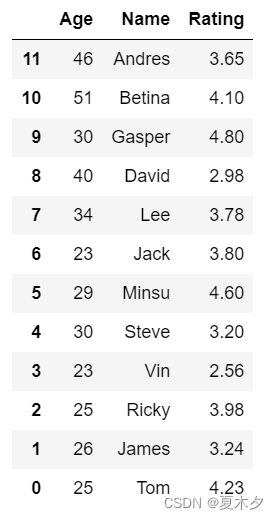
(1)降序
# ascending=False表降序,默认ascending=True升序,默认按行标签排序
sorted_df = unsorted_df.sort_index(ascending=False)
sorted_df
(2)按列标签排序
sorted_df=unsorted_df.sort_index(axis=1)
sorted_df
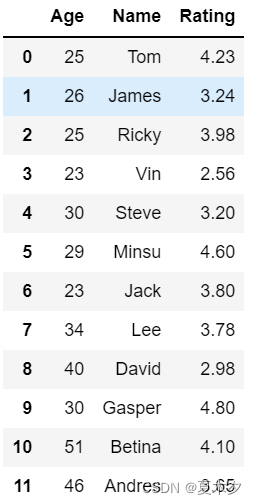
(3)按实际值排序
sort_values()是按值排序的方法,参数inplace=True可以改变原数据,它还接受一个by参数,它将使用要与其排序值的DataFrame的列名称。
# 按照年龄排序(升序)
sorted_df = unsorted_df.sort_values(by='Age')
sorted_df
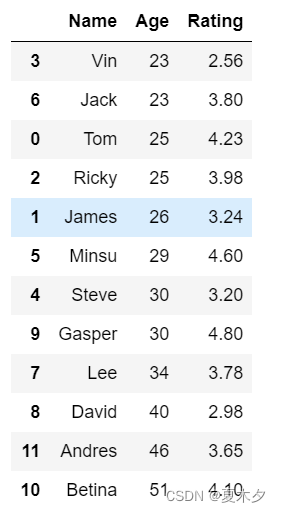
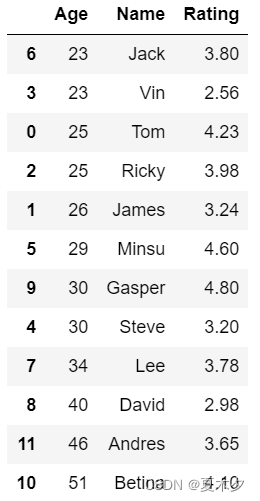
# 先按Age进行升序排序,然后按Rating降序排序
sorted_df = unsorted_df.sort_values(by=['Age', 'Rating'], ascending=[True, False])
sorted_df
13 统计
数值型数据的描述性统计主要包括了计算数值型数据的完整情况、最小值、均值、中位 数、最大值、四分位数、极差、标准差、方差、协方差等。在NumPy库中一些常用的统计学函数也可用于对数据框进行描述性统计。

pandas提供了统计相关函数:

# 测试描述性统计函数
df.sum() # 默认计算纵向数据的和
df.sum(1) # 计算横向数据的和
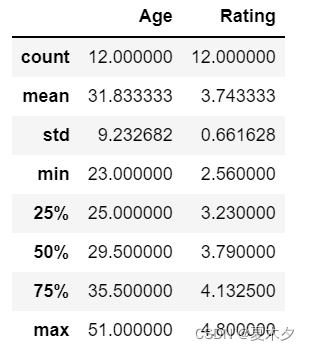
一般分类数据用value_counts(),数值数据用describe(),这是最常用的两个统计函数
value_counts() 方法是Series拥有的方法,它返回一个序列 Series,该序列包含每个值的数量。也就是说,对于数据框中的任何列,value-counts () 方法会返回该列每个项的计数。
df.describe()
# 该函数可以对某一列进行分析
# df["Age"].describe()
include参数:包含哪类数据。默认只包含连续值,不包含离散值;include = ‘all’ 设置全部类型percentiles参数:设置输出的百分位数,默认为[.25,.50,.75],返回第25,50,75百分位数
对连续值来说:
- count:每一列非空值的数量
- mean: 每一列的平均值
- std:每一列的标准差
- min:最小值
- 25%:25%分位数,排序之后排在25%位置的数
- 50%:50%分位数
- 75%:75%分位数
- max:最大值
对离散值来说特有的:
- unique:不重复的离散值数目,去重之后的个数
- top: 出现次数最多的离散值
- freq: 上述的top出现的次数
df.Age.value_counts()

14 数据表关联
(1)merge()合并
pd.merge(left, right, how = ‘inner’, on = None, left_on = None, right_on = None,
left_index = False, right_index = False, sort = True, suffixes = (‘_x’,’_y’),
copy = True, indicator = False, validate = None)
参数:
left、right:需要连接的两个DataFrame或Series,一左一右how:两个数据连接方式,可设置inner、outer、left或right,默认的方式是inner join,取交集,也就是保留左右表的共同内容;如果是left join,左边表中所有的内容都会保留;如果是right join,右表全部保留;如果是outer join,则左右表全部保留。关联不上的内容为NaNon:作为连接键的字段,左右数据中都必须存在,否则需要用left_on和right_on来指定left_on:左表的连接键字段right_on:右表的连接键字段left_index:为True时将左表的索引作为连接键,默认为Falseright_index:为True时将右表的索引作为连接键,默认为Falsesuffixes:如果左右数据出现重复列,新数据表头会用此后缀进行区分,默认为_x和_y
① 连接键 on
在数据连接时,如果没有指定根据哪一列(连接键)进行连接,Pandas会自动找到相同列名的列进行连接,并按左边数据的顺序取交集数据。为了代码的可阅读性和严谨性,推荐通过on参数指定连接键
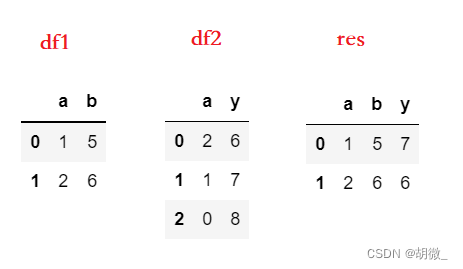
df1 = pd.DataFrame({'a':[1,2],'b':[5,6]})
df2 = pd.DataFrame({'a':[2,1,0],'y':[6,7,8]})
# 按a列进行连接,数据顺序取df1的顺序
res = pd.merge(df1, df2, on='a')
② 索引连接
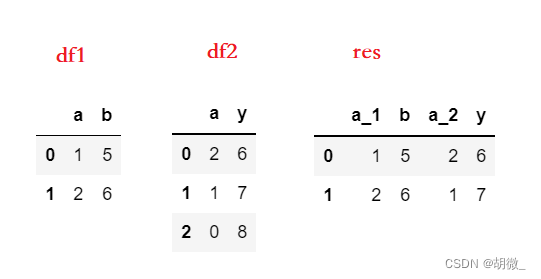
可以直接按索引进行连接,将left_index和right_index设置为True,会以两个表的索引作为连接键
df1 = pd.DataFrame({'a':[1,2],'b':[5,6]})
df2 = pd.DataFrame({'a':[2,1,0],'y':[6,7,8]})
# 两个表都有同名的a列,用suffixes参数设置后缀来区分
res = pd.merge(df1, df2, left_index=True, right_index=True, suffixes=('_1','_2'))
③ 多连接键
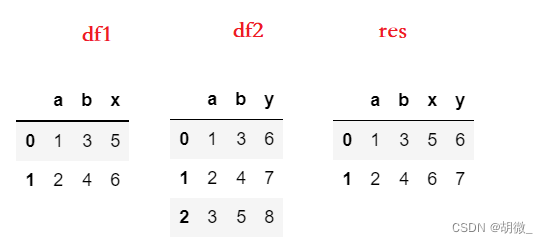
如果在合并数据时需要用多个连接键,可以以列表的形式将这些连接键传入on中
df1 = pd.DataFrame({'a':[1,2],'b':[3,4],'x':[5,6]})
df2 = pd.DataFrame({'a':[1,2,3],'b':[3,4,5],'y':[6,7,8]})
# a和b列中的(1,3)和(2,4)作为连接键将两个数据进行了连接
res = pd.merge(df3, df4, on=['a','b'])
④ 连接指示
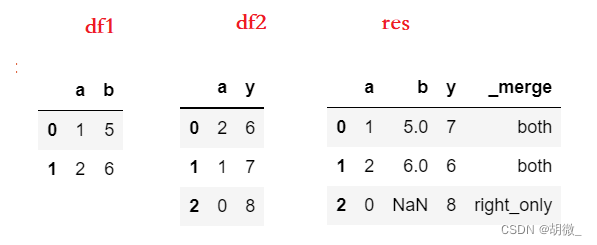
如果想知道数据连接后是左表内容还是右表内容,可以使用indicator参数显示连接方式
如果将indicator设置为True,则会增加名为_merge的列,显示这列是从何而来
_merge有以下三个值:
- left_only:只在左表中
- right_only:只在右表中
- both:两个表都有
import pandas as pd
df1 = pd.DataFrame({'a':[1,2],'b':[5,6]})
df2 = pd.DataFrame({'a':[2,1,0],'y':[6,7,8]})
# 显示连接指示列
res = pd.merge(df1, df2, on='a', how='outer', indicator=True)
(2)concat()合并
concat()函数可以沿着指定的轴将多个dataframe或者series拼接到一起。
pd.concat( objs, axis=0, join=‘outer’, join_axes=None,ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, sort=None, copy=True)
参数:
- objs 表示需要连接的对象,比如:[df1, df2],需要将合并的数据用方括号包围;
- axis=0 表拼接方式是上下堆叠,当axis=1表示左右拼接;
- join 参数控制的是外连接还是内连接,inner,outer,这里默认值是outer并集
- ignore_index,连接后原来两个DF的index值会被保存,设置true,合并的两个表就会重新整理一个新的index
15 索引设置
(1)将某一列设置为索引
rs=rs.set_index('student_name')
rs
(2)重新设置索引
reset_index()
- drop: 重新设置索引后是否将原索引作为新的一列并入DataFrame,默认为False
- inplace: 是否在原DataFrame上改动,默认为False
16 数据的读取与存储
(1)读取与存储csv
pd.read_table(
filepath_or_buffer, sep='t', header='infer', names=None,
index_col=None, dtype=None, engine=None, nrows=None)
pd.read_csv(
filepath_or_buffer, sep=',', header='infer', names=None,
index_col=None, dtype=None, engine=None, nrows=None)
参数:
- filepath 文件路径。该字符串可以是一个URL。有效的URL方案包括http,ftp和file
- sep 分隔符。read_csv默认为“,”,read_table默认为制表符“[Tab]”。
- header 接收int或sequence。表示将某行数据作为列名。默认为infer,表示自动识别。
- names 接收array。表示列名。
- index_col 表示索引列的位置,取值为sequence则代表多重索引。
- dtype 代表写入的数据类型(列名为key,数据格式为values)。
- engine 接收c或者python。代表数据解析引擎。默认为c。
- nrows 接收int。表示读取前n行。
df.to_csv(excel_writer=None, sheetname=None, header=True, index=True, index_label=None, mode=’w’, encoding=None)
(2)读取与存储excel
pd.read_excel(io, sheetname=0, header=0, index_col=None, names=None, dtype=None)
参数:
- io 表示文件路径。
- sheetname 代表excel表内数据的分表位置。默认为0。
- header 接收int或sequence。表示将某行数据作为列名。默认为infer,表示自动识别。
- names 表示索引列的位置,取值为sequence则代表多重索引。
- index_col 表示索引列的位置,取值为sequence则代表多重索引。
- dtype 接收dict。数据类型。
DataFrame.to_excel(excel_writer=None, sheetname=None, header=True, index=True, index_label=None, mode=’w’, encoding=None)
(3)读取与存储JSON
# 通过json模块转换为字典,再转换为DataFrame
df = pd.read_json('./test.json')
print(df)
with open("test.json","r") as f:
data = json.loads(f.read())
df = pd.DataFrame(data)
print(df)
最后
以上就是怕孤单电源最近收集整理的关于科学计算库 —— Pandas之DataFrame1 DataFrame介绍2 创建DataFrame3 常用属性4 访问数据5 处理重复数据6 删除数据7 添加数据8 修改数据9 缺失值处理10 分组11 聚合12 排序13 统计14 数据表关联15 索引设置16 数据的读取与存储的全部内容,更多相关科学计算库内容请搜索靠谱客的其他文章。








发表评论 取消回复