作者:胡雨霄 (伦敦政治经济学院)
Stata 连享会: 知乎 | 主页 | 码云 | CSDN
连享会 - 与君分享 lianxh.cn
文章目录
- 1. statsby 命令简介
- Stata 中的返回值
- Stata 循环语句
- statsby 的语法格式
- 连享会计量方法专题……
- 2. 实例 1:输出 `r-class` 留存值
- 2. 实例 2:输出不同组别的估计系数
- 参考文献
- 附:文中主要 Stata 命令
- 关于我们
Note:本文根据连玉君老师的 Stata 初级班讲义 A1_intro.do 整理而得。
本篇推文介绍命令 statsby,该命令被广泛用于分组汇报单值 (scalar) 或者系数。
1. statsby 命令简介
顾名思义,statsby 就是分组 (bysort) 进行统计分析 (statstics)。它是 Stata 的官方命令,能够高效快捷地实现多种循环计算和统计功能。
在介绍 statsby 命令前,先简要介绍如下两个概念,作为铺垫,以便更好理解 statsby 命令。
Stata 中的返回值
Stata 中多数命令都以计算和统计分析为主要目的。命令执行后,除了在屏幕上以表格或图形的方式呈现一些核心结果,内存中还保留了大量的结果。这些结果统称为返回值,包括 统计量 (如 样本数,R-square,F 统计量等)、文件路径、命令名称,甚至还包括 矩阵 和 函数 等。这些返回值可以很方便地在后续程序中调用。
若希望对返回值有更为全面的了解,可以在 Stata 命令窗口中输入 help stored_results 以及 help return
Stata 命令主要可以分为四种类型:(1)r-class 与模型估计无关的命令,如,summary; (2)e-class 与模型估计有关的命令,如,regress;(3)s-class 其他命令,如,list;(4)c-class 存储系统参数。
相应地,显示留存值的方法也分别为:return list, ereturn list, sreturn list, 以及 creturn list。
留存值也可分为四种类型:(1) 单值,如,r(mean), r(max), r(N), e(r2), e(F);(2) 矩阵,如,e(b), e(V);(3) 暂元,如,e(cmd), e(depvar); (4) 函变量,如,e(sample)。
举两个简单的例子 (受限于篇幅,仅展示部分结果):
例1:return list
. sysuse "auto.dta", clear
. summarize price
Variable | Obs Mean Std. Dev. Min Max
-------------+---------------------------------------------------------
price | 74 6165.257 2949.496 3291 15906
. dis "方差 (price) = " r(Var)
方差 (price) = 8699526
. dis "range: `r(max)', `r(min)'" // 放在双引号中的返回值,需要使用暂元方式引用
range: 15906, 3291
. return list // 列示所有返回值,请找找对应关系
scalars:
r(N) = 74
r(sum_w) = 74
r(mean) = 6165.256756756757
r(Var) = 8699525.974268789
r(sd) = 2949.495884768919
r(min) = 3291
r(max) = 15906
r(sum) = 456229
例2:ereturn list
. sysuse "auto.dta", clear
. reg price weight mpg
. matrix list e(V) // 列示系数的方差-协方差矩阵
symmetric e(V)[3,3]
weight mpg _cons
weight .41133468
mpg 44.601659 7422.863
_cons -2191.9032 -292759.82 12938766
. ereturn list // 列示所有返回值。Note:这里仅列出了一部分
scalars:
e(N) = 74
e(F) = 14.73981538538409
e(r2) = .2933891231947527
e(rss) = 448744116.3821706
e(r2_a) = .2734845914537599
macros:
e(cmdline) : "regress price weight mpg"
e(title) : "Linear regression"
e(depvar) : "price"
e(cmd) : "regress"
e(estat_cmd) : "regress_estat"
matrices:
e(b) : 1 x 3
e(V) : 3 x 3
functions:
e(sample)
Stata 循环语句
相关介绍请参照推文 「普林斯顿Stata教程 - Stata编程」。
statsby 的语法格式
statsby 命令的基本语法十分简单。
statsby [exp_list], by(varlist): command
其中,by(varlist) 用于设定分组变量,例如 公司代码、行业分类等。[exp_list] 用于指定返回值。
连享会计量方法专题……
2. 实例 1:输出 r-class 留存值
sysuse auto, clear
statsby mean=r(mean) sd=r(sd) size=r(N), by(rep78): summarize mpg
statsby 命令保存了不同 rep78 组别中 mpg 变量的平均值 (mean)、标准差 (sd) 以及观察值个数 (N)。
. list
+------------------------------------+
| rep78 mean sd size |
|------------------------------------|
1. | 1 21 4.24264 2 |
2. | 2 19.125 3.758324 8 |
3. | 3 19.43333 4.141325 30 |
4. | 4 21.66667 4.93487 18 |
5. | 5 27.36364 8.732385 11 |
+------------------------------------+
上述命令等价于如下基于 forvalues 命令编写的循环语句:
sysuse "auto.dta", clear
forvalues i =1/5{
qui summarize mpg if rep78==`i' // 第 i 组
dis "`i'" ///
_col(4) "mean=" r(mean) /// // 在第 4 列列示结果
_col(20) "sd=" r(sd) ///
_col(40) "N=" r(N)
}
输出结果如下:
1 mean=21 sd=4.2426407 N=2
2 mean=19.125 sd=3.7583241 N=8
3 mean=19.433333 sd=4.1413252 N=30
4 mean=21.666667 sd=4.9348699 N=18
5 mean=27.363636 sd=8.7323849 N=11
显然,使用 forvalues 语句不但语法繁琐,输出结果也不容易控制。
2. 实例 2:输出不同组别的估计系数
实例 1 所介绍的 statsby 命令的应用其实并不常用。一个更具有实证价值的应用为输出不同组别的系数。 Opler et al. (1999, JFE, [PDF]) 中图 3 的绘制就是一个很好的例子。
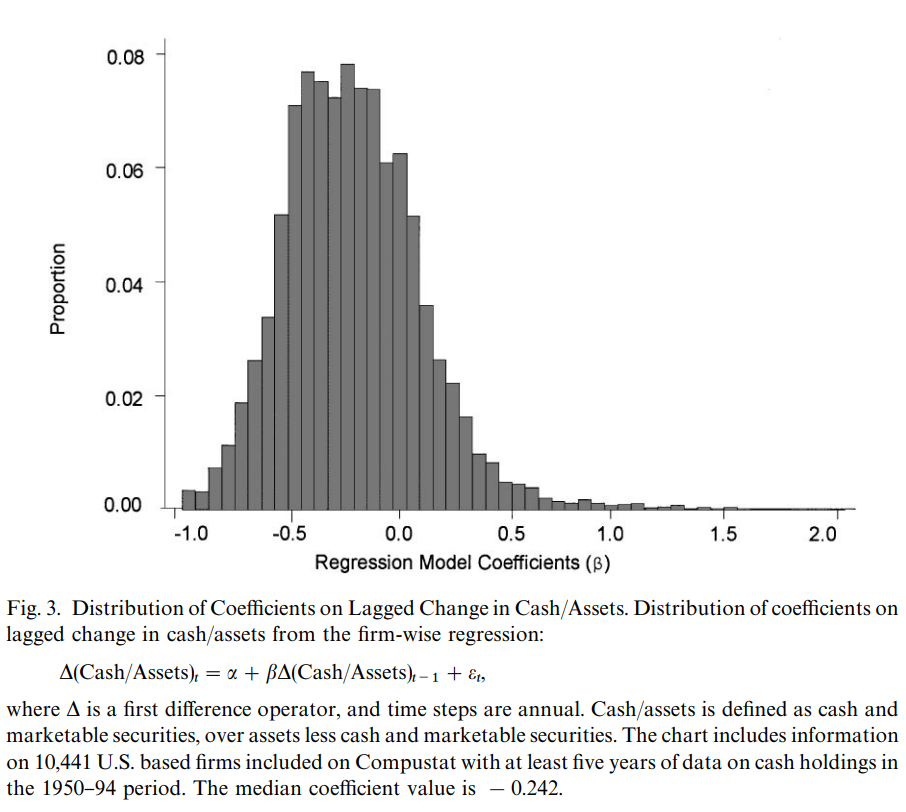
该文研究资本结构的动态调整速度。动态资本结构理论认为企业的最优资本结构并不是固定的股权债务比例,而是一个变化的股权债务比例范围,企业设定目标资本结构,并依据各种条件的变化不断地进行着资本结构的调整。
其基本模型为:
y i t − y i , t − 1 = λ ( y i t ∗ − y i , t − 1 ) y_{it}-y_{i,t-1}=lambda(y^*_{it}-y_{i,t-1}) yit−yi,t−1=λ(yit∗−yi,t−1)
y i t ∗ = θ x i t y^*_{it}=theta x_{it} yit∗=θxit
y i t y_{it} yit 为公司 i i i 在 t t t 期的资本结构, y i t ∗ y^*_{it} yit∗ 为目标资本结构。我们可以将 λ lambda λ 理解为每家公司的调整系数。
设定数据模拟情形
y i t = 0.6 ∗ y i , t − 1 + 1.3 ∗ x i t + a i + e i t y_{it}=0.6*y_{i,t-1}+1.3*x_{it}+a_i+e_{it} yit=0.6∗yi,t−1+1.3∗xit+ai+eit
x i t = 0.2 ∗ x i , t − 1 + v i t x_{it}=0.2*x_{i,t-1}+v_{it} xit=0.2∗xi,t−1+vit
c o r r ( x i t , a i ) = 1 corr(x_{it},a_i) = 1 corr(xit,ai)=1
命令如下:
xtarsim y x eta, n(1000) t(10) gamma(0.6) beta(1.3) rho(0.2) ///
one(corr 3) sn(9) seed(1234)
数据结构如下
. list in 1/10
+--------------------------------------------------+
| ivar tvar y x eta |
|--------------------------------------------------|
1. | 1 1 13.862633 2.5646089 2.6616445 |
2. | 1 2 8.3913755 -2.0077635 2.6616445 |
3. | 1 3 11.940121 2.6233153 2.6616445 |
4. | 1 4 14.46718 3.0163007 2.6616445 |
5. | 1 5 10.069268 -.78471857 2.6616445 |
|--------------------------------------------------|
6. | 1 6 12.524141 2.3777554 2.6616445 |
7. | 1 7 14.268779 2.3195181 2.6616445 |
8. | 1 8 15.289451 2.9322523 2.6616445 |
9. | 1 9 10.236962 -1.5005251 2.6616445 |
10. | 1 10 8.8389802 .74967746 2.6616445 |
+--------------------------------------------------+
接下来,运用 statsby 命令估计每家公司的调整系数
xtset ivar tvar
statsby _b[L.D.y], by(ivar) saving("$DLev_speed", replace): ///
reg D.y L.D.y
该命令将回归 reg D.y L.D.y 的系数(_b[L.D.y])存储在新数据集中。为了输出 Opler et al. (1999, JFE, [PDF]) 图 3 类似的图形,采取如下的命令。
use "$DLev_speed.dta", clear
rename _stat_1 speed
sum speed, d
histogram speed
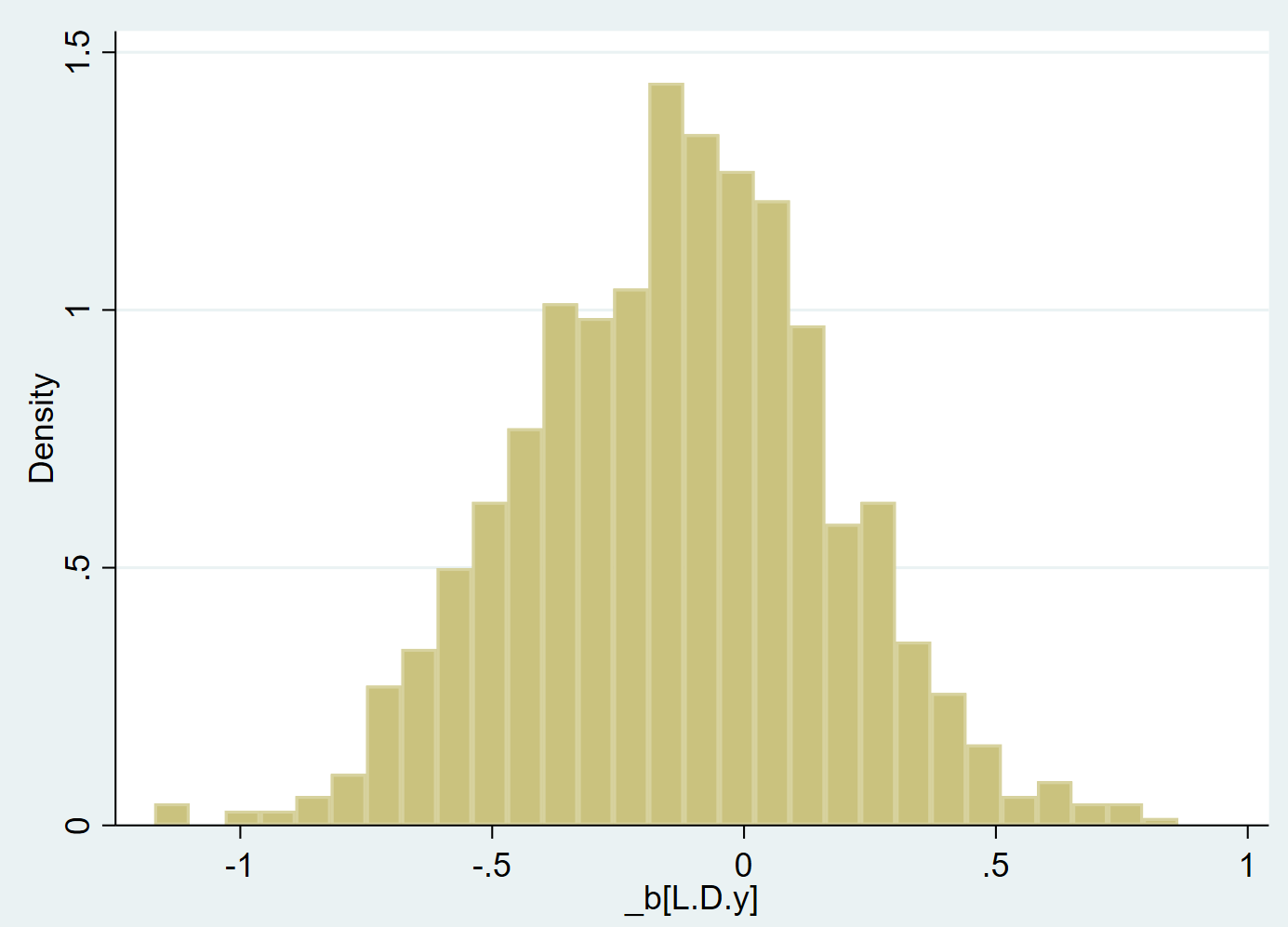
speed 表示资本动态结构调整的速度,其描述性统计结果如下。
. sum speed, d
_b[L.D.y]
-------------------------------------------------------------
Percentiles Smallest
1% -.8351784 -1.170866
5% -.6367424 -1.130177
10% -.5305484 -1.103174 Obs 1,000
25% -.3444118 -1.017748 Sum of Wgt. 1,000
50% -.1253898 Mean -.1340506
Largest Std. Dev. .3053147
75% .063599 .7306181
90% .2565345 .7385662 Variance .0932171
95% .3583316 .7686451 Skewness -.0333423
99% .6108425 .8620657 Kurtosis 3.120044
-------------------------------------------------------------
直方图如下。我们可以看到,与 Opler et al. (1999, JFE, [PDF]) 的图 3 是非常类似的,汇报了资本动态结构调整速度的直方图。
参考文献
Opler, T., Pinkowitz, L., Stulz, R., & Williamson, R. (1999). The determinants and implications of corporate cash holdings. Journal of Financial Economics, 52(1), 3-46.
附:文中主要 Stata 命令
. sysuse "auto.dta", clear
. summarize price
. dis "方差 (price) = " r(Var)
. dis "range: `r(max)', `r(min)'" // 放在双引号中的返回值,需要使用暂元方式引用
. return list // 列示所有返回值
. reg price weight mpg
. matrix list e(V) // 列示系数的方差-协方差矩阵
. ereturn list // 列示所有返回值
*-Stata 范例 1:
sysuse "auto.dta", clear
statsby mean=r(mean) sd=r(sd) N=r(N), by(rep78): summarize mpg
list, clean noobs //执行 statsby 后,内存中的原始数据会被清空,代以 statsby 的返回值
*-上述命令的等价命令
sysuse "auto.dta", clear
forvalues i =1/5{
qui summarize mpg if rep78==`i' // 第 i 组
dis "`i'" ///
_col(4) "mean=" r(mean) /// // 在第 4 列列示结果
_col(20) "sd=" r(sd) ///
_col(40) "N=" r(N)
}
*-实例 2:输出不同组别的估计系数
. xtarsim y x eta, n(1000) t(10) gamma(0.6) beta(1.3) rho(0.2) ///
one(corr 3) sn(9) seed(1234)
. list in 1/10
. xtset ivar tvar
. statsby _b[L.D.y], by(ivar) saving("$DLev_speed", replace): ///
reg D.y L.D.y
. use "$DLev_speed.dta", clear
. rename _stat_1 speed
. sum speed, d
. histogram speed
. sum speed, d
关于我们
- Stata连享会 由中山大学连玉君老师团队创办,定期分享实证分析经验。直播间 有很多视频课程,可以随时观看。
- 你的颈椎还好吗? 您将 ::连享会-主页:: 和 ::连享会-知乎专栏:: 收藏起来,以便随时在电脑上查看往期推文。
- 公众号推文分类: 计量专题 | 分类推文 | 资源工具。推文分成 内生性 | 空间计量 | 时序面板 | 结果输出 | 交乘调节 五类,主流方法介绍一目了然:DID, RDD, IV, GMM, FE, Probit 等。
- 公众号关键词搜索/回复 功能已经上线。大家可以在公众号左下角点击键盘图标,输入简要关键词,以便快速呈现历史推文,获取工具软件和数据下载。常见关键词:
课程, 直播, 视频, 客服, 模型设定, 研究设计,stata, plus,Profile, 手册, SJ, 外部命令, profile, mata, 绘图, 编程, 数据, 可视化DID,RDD, PSM,IV,DID, DDD, 合成控制法,内生性, 事件研究交乘, 平方项, 缺失值, 离群值, 缩尾, R2, 乱码, 结果Probit, Logit, tobit, MLE, GMM, DEA, Bootstrap, bs, MC, TFP面板, 直击面板数据, 动态面板, VAR, 生存分析, 分位数空间, 空间计量, 连老师, 直播, 爬虫, 文本, 正则, pythonMarkdown, Markdown幻灯片, marp, 工具, 软件, Sai2, gInk, Annotator, 手写批注盈余管理, 特斯拉, 甲壳虫, 论文重现易懂教程, 码云, 教程, 知乎
最后
以上就是老迟到高跟鞋最近收集整理的关于statsby: 不用循环语句的循环的全部内容,更多相关statsby:内容请搜索靠谱客的其他文章。








发表评论 取消回复