最近看一些基于LSTM网络的NLP案例代码,其中涉及到一些input_size, num_hidden等变量的时候,可能容易搞混,首先是参照了知乎上的一个有关LSTM网络的回答https://www.zhihu.com/question/41949741, 以及github上对于LSTM比较清晰的推导公式http://arunmallya.github.io/writeups/nn/lstm/index.html#/3, 对于lstm cell中各个门处理,以及隐含层的实际物理实现有了更深刻的认识,前期一些理解上还模糊的点 也在不断的分析中逐渐清晰。
首先给出LSTM网络的三种不同的架构图:
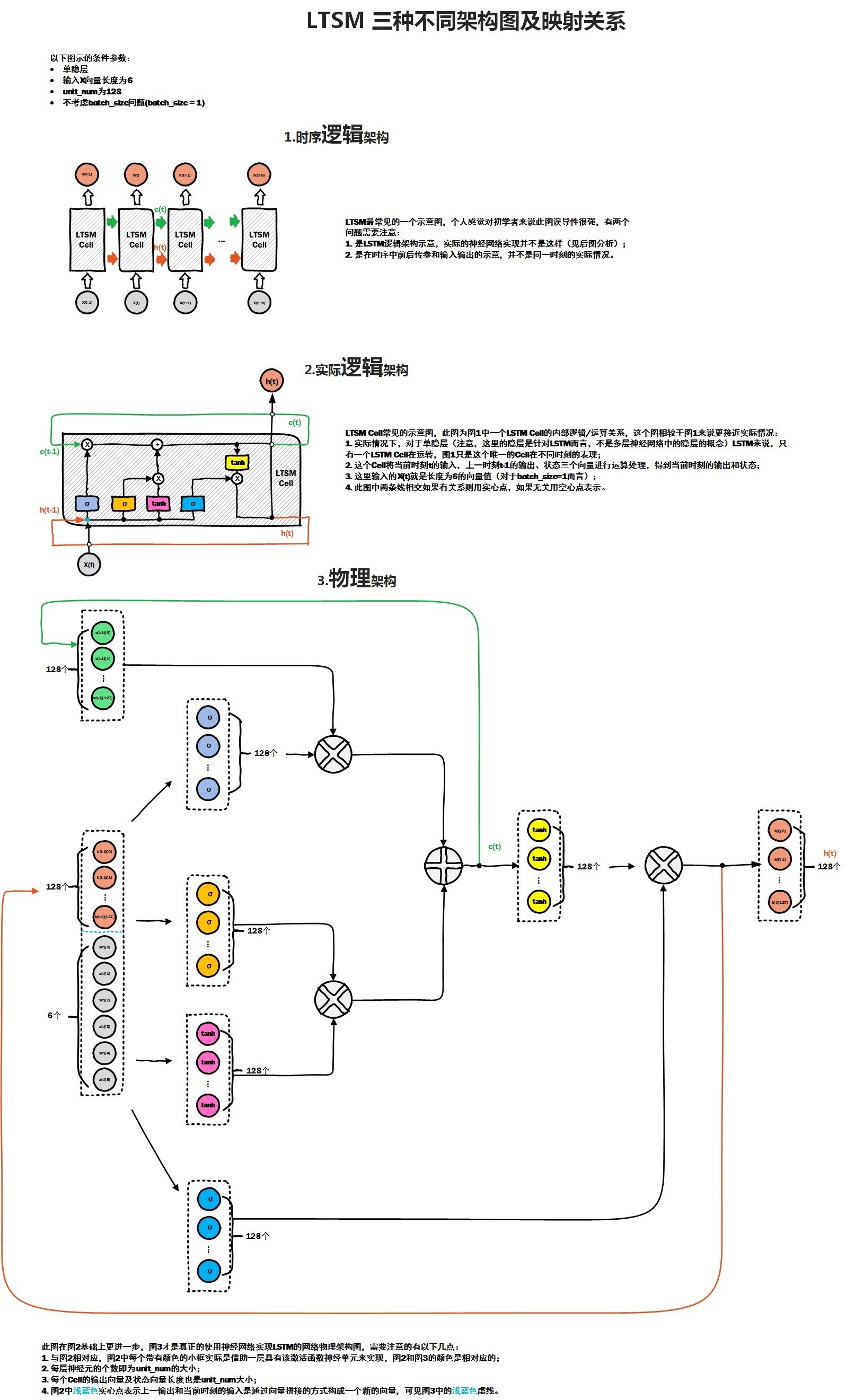
其中前两种是网上最常见的,图二相对图一,进一步解释了cell内各个门的作用,但是在实际的神经网络中,各个门处理函数 其实是由一定数量的隐含层神经元来处理,在RNN中,M个神经元组成的隐含层,实际的功能应该是f(wx + b), 这里实现了两部,首先M个隐含层神经元与输入向量X之间全连接,通过w参数矩阵对x向量进行加权求和,其实就是对x向量各个维度上进行筛选,加上bias偏置矩阵后,通过f激励函数, 得到隐含层的输出。而在LSTM Cell中,一个cell 包含了若干个门处理函数,假如每个门的物理实现,我们都可以看做是由num_hidden个神经元来实现该门函数功能, 那么每个门各自都包含了相应的w参数矩阵以及bias偏置矩阵参数,就是在图3物理架构图中的实现。从图3中可以看出,cell单元里有四个门,每个门都对应128个隐含层神经元,相当于四个隐含层,每个隐含层各自与输入x 全连接,而输入x向量是由两部分组成,一部分是上一时刻cell 输出,大小为128, 还有部分就是当前样本向量的输入,大小为6,因此通过该cell内部计算后,最终得到当前时刻的输出,大小为128,即num_hidden,作为下一时刻cell的一部分输入。比如在NLP场景下,当一个词向量维度为M时, 可以认为当前x维度为M,如果num_hidden = N, 那么与x全连接的某个隐含层神经元的w矩阵大小为 M * N, bias的维度为N, 所以平时我们在初始化lstm cell的时候,样本输入的embedding_size 与 num_hidden 之间没有直接关联,而是会决定每个门的w矩阵维度, 而且之前的一片BasicLSTMCell 源码分析中,我们提到了BasicLSTMCell 是直接要求embedding_size 与 num_hidden 是相等的,这也大大简化了多个w矩阵的计算,这也说明了BasicLSTMCell是最简单和最常用的一种lstm cell
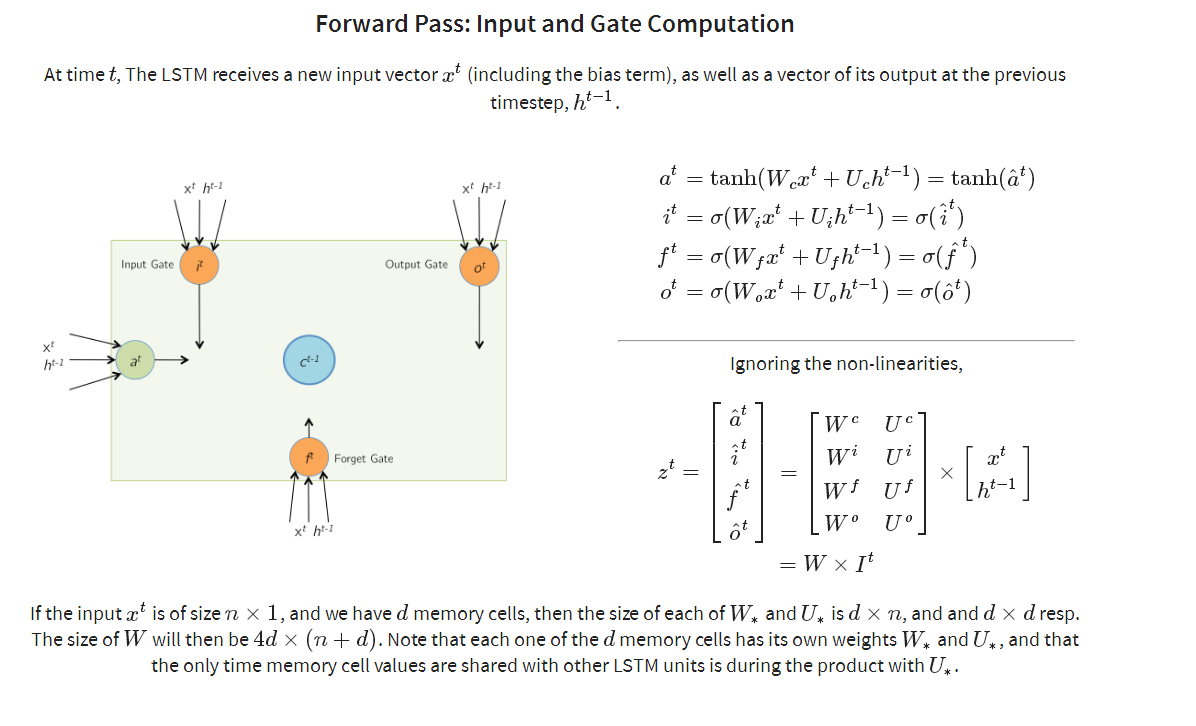
从上图中可以看出,每个门都对应一个w 以及bias矩阵
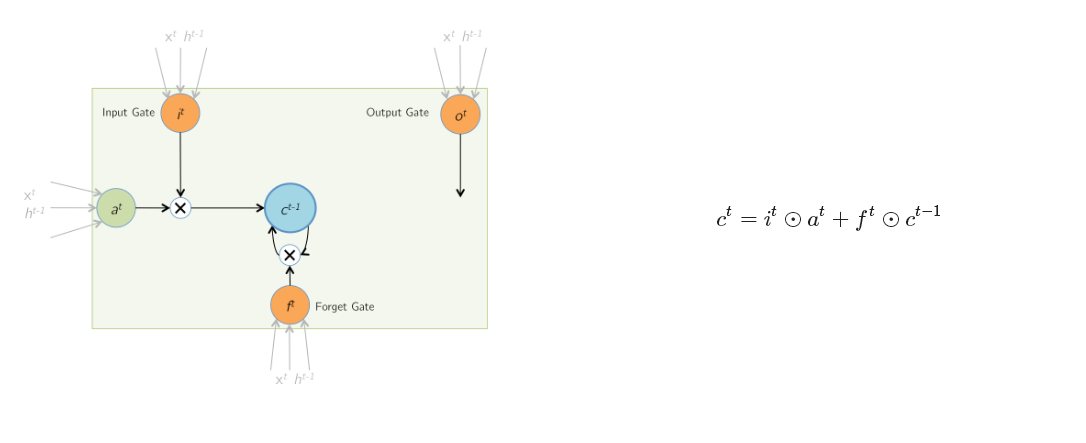
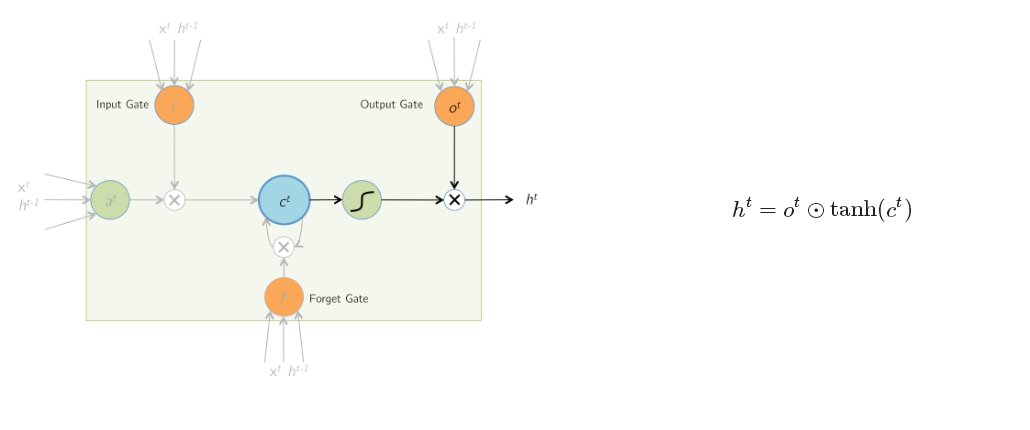
最终当前时刻的输出h 是有cell内多个门函数共同作用的结果。
关于time_step的问题:
假设 文本的样本数据集是(100, 80 , 50), 其中100指的是batch_size, 即样本个数,80 是指句子sentence的最大长度, 也是指参数优化过程中一次处理的最大时间步长max_time steps, 50则是词向量维度embedding_size, 假如num_hidden = 256, 那么每个时间步 输出的是256维度的一阶向量,那么在一次梯度优化过程中输出的二阶向量为80 * 256, 具体可以看下面的公式:

这里的T 就是样本集中的80,也是指一个sentence最大长度,我们在参数优化的过程中,以一个完整句子的输出进行梯度下降计算。
以上只是参考了别人的想法,自己对lstm cell 的一个初步的理解和认识,后续在阅读源码和案例代码的过程中,还需要反复揣摩RNN网络的实际底层架构和计算原理,下一篇准备针对LSTMCell 进行源码分析。
最后
以上就是懦弱天空最近收集整理的关于LSTM 实际神经元隐含层物理架构原理解析的全部内容,更多相关LSTM内容请搜索靠谱客的其他文章。








发表评论 取消回复