参考:
1、https://github.com/spmallick/learnopencv
2、https://keras.io
3、https://github.com/jolilj/CascadedCNNFaceDetection 利用Cascaded卷积神经网络进行人脸检测
深度学习使用Keras - 基础知识
这是使用Keras的深度学习系列的第一篇文章。 我们将在接下来的几周内讨论以下主题(以及更多..)。
1、Keras的基本知识 - 实现单层神经网络
2、在Keras实现一个简单的前馈网络
3、使用预先训练的模型进行转移学习和调整
4、从头开始训练深度神经网络
5、使用TensorBoard和其他工具进行调试和故障排除
| 1.深度学习框架 |
深度学习是使用神经网络进行机器学习的AI的一个分支。 近年来,与计算机视觉,自然语言处理,机器人等应用领域相比,传统的机器学习方法已经有了显着的改进。 本文将介绍卷积神经网络(一种神经网络)的一个非常简单的介绍。
自从2012年Alex Krizhevsky和他的团队赢得了ImageNet的挑战,Deep Learning成为AI工程师的家喻户晓的名字。 ImageNet是一个计算机视觉竞赛,要求计算机将对象的图像正确分类到1000个类别之一。 对象包括不同类型的动物,植物,仪器,家具,车辆等等。
这引起了计算机视觉界的很多关注,几乎每个人都开始研究神经网络。 但那个时候,没有太多的工具可以让你开始使用这个新的领域。 研究人员已经投入了大量的精力来创建有用的图书馆,以便在这个新兴的领域工作。 目前流行的深度学习框架有Tensorflow,Theano,Caffe,Pytorch,CNTK,MXNet,Torch,deeplearning4j,Caffe2等等。
Keras是一个高级API,用Python编写,能够在TensorFlow,Theano或CNTK上运行。 上述的深度学习库是以通用的方式编写的,具有很多功能。 对于深度学习知识有限的初学者来说,这可能是压倒一切的。 Keras提供了一个简单的模块化API来创建和训练神经网络,隐藏了大部分复杂的细节。 这使您可以轻松开始深度学习之旅。
一旦你熟悉了主要的概念并且想深入挖掘并且控制这个过程,你可以选择使用上面的任何框架。
| 2. Keras安装和配置 |
如上所述,Keras是一个高级API,使用深度学习库如Theano或Tensorflow作为后端。 这些库又通过低级库与硬件进行通信。 例如,如果您在CPU上运行该程序,Tensorflow或Theano使用BLAS库。 另一方面,当你在GPU上运行时,他们使用CUDA和cuDNN库。
如果你正在建立一个新的系统,你可能想看看这篇文章安装最常见的深度学习框架。 我们在这里只提到Keras的具体部分。
建议在虚拟环境中安装一切。 如果系统上没有安装虚拟环境,请检查上述文章的步骤5。
我们将安装Theano和Tensorflow作为Keras的后端库,以及一些用于处理数据(h5py)和可视化(pydot,graphviz和matplotlib)的库。
| 创建虚拟环境 |
为python 2或python 3创建虚拟环境,无论你想使用哪一个。
mkvirtualenv virtual-py2 -p python2
# Activate the virtual environment
workon virtual-py2Or
mkvirtualenv virtual-py3 -p python3
# Activate the virtual environment
workon virtual-py3| 安装库 |
pip install Theano
#If using only CPU
pip install tensorflow
#If using GPU
pip install tensorflow-gpu
pip install keras
pip install h5py pydot matplotlib同时安装graphviz
#For Ubuntu
sudo apt-get install graphviz
#For MacOs
brew install graphviz| 配置Keras |
默认情况下,Keras被配置为使用Tensorflow作为后端,因为它是最流行的选择。 但是,如果要将其更改为Theano,请打开文件〜/ .keras / keras.json,如下所示:
{
"epsilon": 1e-07,
"floatx": "float32",
"image_data_format": "channels_last",
"backend": "tensorflow"
}并将其更改为
{
"epsilon": 1e-07,
"floatx": "float32",
"image_data_format": "channels_first",
"backend": "theano"
}| 3. Keras工作流程 |
Keras为训练和评估模型提供了一个非常简单的工作流程。 用下面的图表来描述
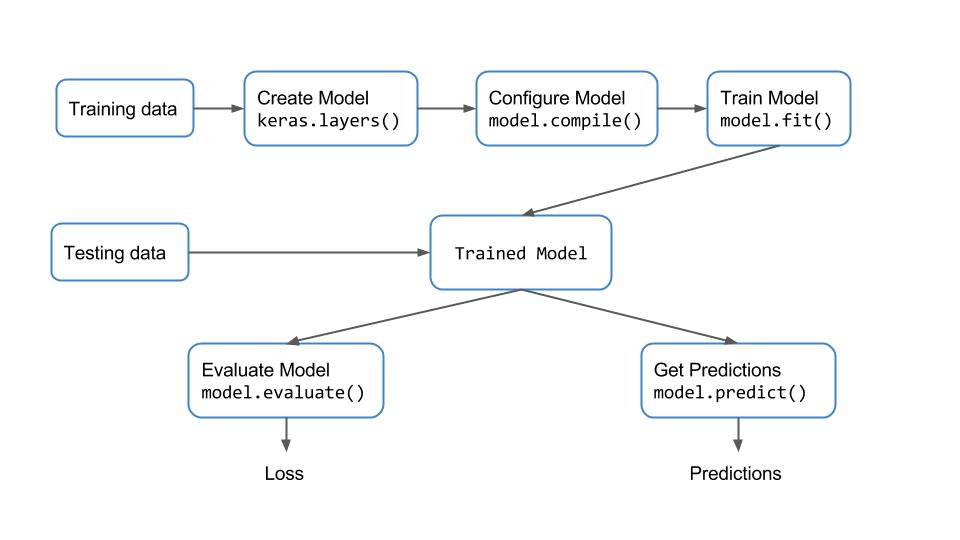
基本上,我们正在创建模型并使用训练数据进行训练。 一旦模型被训练,我们就可以用模型对测试数据进行推理。 让我们了解每个块的功能。
3.1. Keras Layers
层可以被认为是神经网络的基石。 他们处理输入数据并产生不同的输出,这取决于图层的类型,然后被连接到它们的图层使用。 我们将在未来的帖子中介绍每一层的细节。
Keras提供了许多核心层,其中包括
- Dense layers也称为完全连接层,因为输入中的每个节点都连接到输出中的每个节点,
- 包括ReLU,tanh,sigmoid等激活功能的激活层,
- Dropout layer - 用于训练期间正则化,
- Flatten, Reshape, etc等
除了这些核心层之外,还有一些重要的层
- Convolution layers - 用于执行卷积,
- Pooling layers - 用于下采样,
- Recurrent layers,
- Locally-connected, normalization, etc.等
我们可以使用代码片段导入相应的图层
from keras.layers import Dense, Activation, Conv2D, MaxPooling2D3.2. Keras Models
Keras提供了两种定义模型的方法:
- Sequential,用于堆叠图层 - 最常用的。
- Functional API,用于设计复杂模型体系结构,如具有多输出模型,共享图层等
from keras.models import Sequential为了创建一个Sequential模型,我们可以将层列表作为参数传递给构造函数,或者使用model.add()函数顺序添加图层。
例如,用于创建具有10个输出的单个致密层的模型的代码片段都是相同的。
from keras.models import Sequential
from keras.layers import Dense, Activation
model = Sequential([Dense(10, input_shape=(nFeatures,)),
Activation('linear') ])from keras.models import Sequential
from keras.layers import Dense, Activation
model = Sequential()
model.add(Dense(10, input_shape=(nFeatures,)))
model.add(Activation('linear'))模型定义中需要注意的一点是,我们需要指定第一层的输入形状。 这是在上面的代码片段中使用与第一个密集层一起传递的input_shape参数完成的。 其他层的形状由编译器推断。
3.3. 配置训练过程
一旦模型准备就绪,我们需要配置学习过程。 即
- 指定一个确定网络权重如何更新的优化器
- 指定成本函数或损失函数的类型。
- 指定您想在训练和测试期间评估的指标。
- 使用后端创建模型图。
- 任何其他高级配置。
这是使用model.compile()函数在Keras中完成的。 代码片段显示了用法。
model.compile(optimizer='rmsprop', loss='mse', metrics=['mse', 'mae'])要指定的强制参数是优化器和损失函数。
Optimizers
Keras提供了很多优化器可供选择,其中包括
- 随机梯度下降(SGD),
- Adam,
- RMSprop,
- AdaGrad,
- AdaDelta等
对于大多数问题,RMSprop是优化器的一个很好的选择。
Loss functions
在监督学习问题中,我们必须找到实际值与预测值之间的误差。 可以有不同的度量可以用来评估这个错误。 这个度量通常被称为损失函数或成本函数或目标函数。 可能有多个损失函数,取决于你在做什么错误。 一般来说,我们使用
- 二叉交叉熵用于二元分类问题,
- 用于多类分类问题的分类交叉熵,
- 均方误差为回归问题等。
3.4. Training
一旦模型被配置,我们就可以开始训练过程。 这可以使用Keras中的model.fit()函数完成。 用法如下所述。
model.fit(trainFeatures, trainLabels, batch_size=4, epochs = 100)我们只需要指定训练数据,batch size和迭代次数。 Keras自动计算出如何将数据迭代地传递给优化器,以确定指定的时期数量。 剩下的信息在上一步中已经提供给优化器。
3.5. Evaluating the model
一旦模型被训练,我们需要检查看不见的测试数据的准确性。 这可以在Keras中以两种方式完成。
- model.evaluate() - 它找到在model.compile()步骤中指定的损失和指标。 它将测试数据和标签作为输入,并对准确性进行定量测量。 它也可以用来执行交叉验证,并进一步微调参数来获得最佳模型。
- model.predict() - 它找到给定测试数据的输出。 定性检查输出是有用的。
现在,让我们看看如何使用keras模型和图层来创建一个简单的神经网络。
4.线性回归示例
我们将学习如何创建一个简单的单层网络来执行线性回归。 我们将使用Keras中提供的Boston Housing数据集作为例子。 20世纪70年代后期,样本在波士顿郊区的不同位置包含13个房屋属性。 目标是一个地点房屋的中位值(单位:k $)。 有了这13个特征,我们必须训练能够预测测试数据中房屋价格的模型。
4.1. Training
我们使用Sequential模型创建网络图。 然后我们添加一个密度层,输入的数量等于数据中的特征数量和一个输出。 然后我们按照上一节所述的工作流程进行操作。 我们编译模型并使用fit命令进行训练。 最后,我们使用model.summary()函数来检查模型的配置。 所有keras数据集都带有一个load_data()函数,该函数返回代码中显示的训练和测试数据的元组。
from keras.models import Sequential
from keras.layers import Dense
from keras.datasets import boston_housing
(X_train, Y_train), (X_test, Y_test) = boston_housing.load_data()
nFeatures = X_train.shape[1]
model = Sequential()
model.add(Dense(1, input_shape=(nFeatures,), activation='linear'))
model.compile(optimizer='rmsprop', loss='mse', metrics=['mse', 'mae'])
model.fit(X_train, Y_train, batch_size=4, epochs=1000)
model.summary()model.summary()的输出如下所示。 它显示了14个参数 - 13个参数的权重和1个偏差。
4.2. Inference
模型训练完成后,我们要对测试数据进行推理。 我们可以使用model.evaluate()函数找到测试数据的损失。 我们使用model.predict()函数得到测试数据的预测结果。 在这里,我们将地面真值与前五个测试样本的模型预测进行比较。
model.evaluate(X_test, Y_test, verbose=True)
Y_pred = model.predict(X_test)
print Y_test[:5]
print Y_pred[:5,0]输出是
[ 7.2 18.8 19. 27. 22.2]
[ 7.2 18.26 21.38 29.28 23.72]
可以看出,预测遵循了基本的真值,但在预测中存在一些误差。
| 完整代码: |
from keras.models import Sequential
from keras.layers import Dense
from keras.datasets import boston_housing
(X_train, Y_train), (X_test, Y_test) = boston_housing.load_data()
nFeatures = X_train.shape[1]
model = Sequential()
model.add(Dense(1, input_shape=(nFeatures,), activation='linear'))
model.compile(optimizer='rmsprop', loss='mse', metrics=['mse', 'mae'])
model.fit(X_train, Y_train, batch_size=4, epochs=1000)
model.summary()
# Inference
model.evaluate(X_test, Y_test, verbose=True)
Y_pred = model.predict(X_test)
print(Y_test[:5])
print(Y_pred[:5, 0])最后
以上就是悦耳外套最近收集整理的关于learn opencv- 深度学习使用Keras - 基础知识深度学习使用Keras - 基础知识的全部内容,更多相关learn内容请搜索靠谱客的其他文章。








发表评论 取消回复