看过的这些文献, 总的来说, 应该是MSER效果比较好. 我试验了下SWT, 效果不怎么样, 看到其他文献提供的图也有同样的问题, 我想应该是SWT本身的局限而不是程序的问题. 下面的有些论文想实现一下, 可是有的地方作者细节说的很模糊, 这种情况可能需要邮件作者细问了
2016.7.2 21:00
-------------------------------------
先声明阿, 下面的文章我只浅略读过部分, 注在每个文章前面的文字中有一些是我关注的东西
另外说一句, 关于下面的内容, 可能需要你看一下computer vision :a modern approach的High Level Vision部分
以及这本书 Computer Vision Models, Learning, and Inference
首先是ICDAR这几年的总结
D. Karatzas, F. Shafait, S. Uchida, M. Iwamura, L. Gomez, S. Robles, J. Mas, D. Fernandez, J. Almazan, L.P. de las Heras , "ICDAR 2013 Robust Reading Competition", In Proc. 12th International Conference of Document Analysis and Recognition, 2013
(multiple segmentations, Extremal Regions,threshold)Neumann, L., Matas, J.: On combining multiple segmentations in scene text recognition.In: ICDAR (2013)
以及2015 ICDAR
粗看这两年的ICDAR和CVPR, 还有各公司招聘的招聘要求, 感觉不懂DL不算是学过CV呢, 难道还要闭关再学两个月
看看Yann LeCun 关于深度学习的介绍吧 , slides
SSD: Single Shot MultiBox Detector
(CNN, 华南理工)DeepText: A Unified Framework for Text Proposal Generation and Text Detection in Natural Images
(CNN,TextConv+WordGraph) S. Zhu, R. Zanibbi, A Text Detection System for Natural Scenes with Convolutional Feature Learning and Cascaded Classification, CVPR, 2016.
M. Anthimopoulos, B. Gatos, and I. Pratikakis. Detection of Artificial and Scene Text in Images and Video Frames. Pattern Analysis and Applications, 16(3):431–446, 2013.
(2015 ICDAR award winner)L Neumann, J Matas. Efficient Scene Text Localization and Recognition with Local Character Refinement
(Structured Edge detector, multi-scale ACF +Adaboost,filtered by HOG+RF,CNN)Jaderberg, M., Simonyan, K., Vedaldi, A. and Zisserman, A., Reading Text in the Wild with Convolutional Neural Networks.(google,Local Iterative Segmentation, ml , language model)PhotoOCR: Reading Text in Uncontrolled ConditionsAlessandro Bissacco, Mark Cummins, Yuval Netzer, Hartmut Neven Google Inc.
BINARIZATION
Adaptive document image binarization J. Sauvola*, M. PietikaKinen
Thresholding
参考文献: [sahoo88][Sezgin04] , E.R.Davies computer and machine vision, [JSWeszka1978]
(注 T -- threshold)
1.p-tile(根据背景所占的比例(概率)来确定阈值T,根据背景出现的概率来估计T, 需要预先知道背景的概率分布.)
2. mean gray value(所有像素值之和/像素个数 ,一般作为其他估计T方法的初估值)
3. histogram shape analysis(理论上讲, 从前景和背景的灰度直方图的分布来看会出现两个波峰(peak),中间处一个波谷(valley), 这种双峰图形(two mode), 实际上可能会出现多峰(multi-mode)和单峰的情况, 甚至由于背景过于复杂得不到规律, 故存在不能由这种方法确定T的情况)
4. iterative optimal threshold(这种方法先估计一个threshold ,T0, 来区分前景与背景, 然后分别求前景与背景像素的平均值 , 比如Pf 与Pb(我随便起的名字..), 然后求Pf,Pb的均值, 令其为T1 , 以它为threshold对原图进行二值化, 重复这个过程至Ti - T(i-1) < 某个值, 即得到了最优阈值T)
5. entropy-based method(基于熵..这个比较复杂, 最好看看论文原文)
6. clutering-based method(多看原文)
7. hough transform(统计像素找peak)
8. Co-occurrence matrix(上面的方法都是基于像素值来进行分析, 共生矩阵则考虑了像素值之间的空间位置信息)
9. adaptive thresholding, local thresholding(将图像分割成小块, 小区域内求T, 一些方法还考虑了整个图像的分布)
10. .....
使用感受: 读了几个综述, 讲的都是差不多的一件事, 没有一种二值化算法可以适应所有场景, 按照E.R.Davies的说法去试验, 统计像素的值, 统计边缘的像素值, 统计边缘位置所对应的灰度值, 在复杂场景中也是看不出什么规律的. 按照这些经典的算法一个一个去试验, 得到的效果也不是很好.
然而使用thresholding来做分割, 确定阈值又是相当重要的一部份, 我的经验不多, 就不在这一本正经的胡说八道了, 还是多看看相关的论文, 多多实现吧
偶然遇到这个网站http://imagej.net/Auto_Threshold, http://imagej.net/Auto_Local_Threshold
上面提供了图像处理的一些工具, 集成了一些经典的算法, 还是蛮有意思
-----------------------------------------------------------------------
In general, the existing text detection methods can be roughly divided in two categories: region-based and texture-based.
注意他们不是谁优谁劣的关系, 各有优缺点
region-based
(原始方法, vertical edge to create edge map, then dilation,opening, CC analysis, Initial bounding boxes. )Anthimopoulos M, Gatos B, Pratikakis I (2007) Multiresolution text detection in video frames. International conference on computer vision theory and applications, pp 161–166
(propose a new overlay text detection and extraction method using the transition region between the overlay text and background)A new approach for overlay text detection and extraction from complex video scene. IEEE Trans ImageProcess 18(2):401–411
(multiresolution and multiscale edge detection(LoG)(adaptive searching), GMM(Gaussian mixture Model) to characterize color distributions of the foreground and background of a sign(color analysis),andaffine rectification. intensity based OCR [preprocessing(size normalizing, localized intensity normalization),feature extration(Gabor wavelet),feature dimension reduction])Automatic Detection and Recognitionof Signs From Natural ScenesXilin Chen, Member, IEEE, Jie Yang, Member, IEEE, Jing Zhang, and Alex Waibel, Member, IEEE
SWT(试过swt好像不怎么样呢,如何改进?)
(SWT,Stroke Width Transform)Epshtein B, Ofek E, Wexler Y (2010) Detecting text in natural scenes with stroke width transforms, IEEE conference on com puter vision and pattern recognition, San Francisco
(SWT open source code,c++) Google Text Detection on Nokia N900 Using Stroke Width Transform
及对应论文 Google Text Detection on Nokia N900 Using Stroke Width Transform
(SWT lecture)http://videolectures.net/cvpr2010_epshtein_dtns/
(上面视频最后答疑环节, 提到了中文字符, 论文有提到. edge detector用canny要好于其他的edge detector.
对于projective transformation , use some tolerance to solve)
简要说一下SWT算法吧, 时间长了总会忘
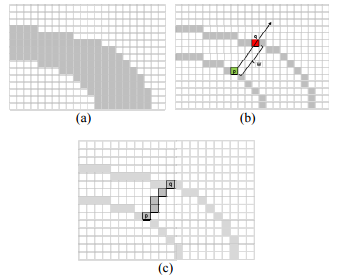
本图及以下图片来源:Epshtein B, Ofek E, Wexler Y (2010) Detecting text in natural scenes with stroke width transforms, IEEE conference on com puter vision and pattern recognition, San Francisco
首先, 用canny edge detector 把 a 变成b, 对于在edge上一点p, 沿着p的梯度方向, 也就是沿着射线 rayr=p+n·dp, n>0寻找另一edge点q, 如果q的梯度方向与p的相反(误差为30度), 则将p、q两点的距离作为字符的宽度, 除非它已有更细的宽度(最开始字符宽度默认为无穷大). 换句话说, 如果不能找到q, 或者q的梯度方向不与p相反, 那么这个射线ray就舍弃(discard)掉了
其实还有部分内容, 看看论文原文吧
(strokes and their relative position, bounding box)Neumann, L., Matas, J.: Scene text localization and recognition with orientedstroke detection. In: ICCV (2013)
Neumann, L., Matas, K.: Real-time scene text localization and recognition. In:CVPR (2012)
DCT
(DCT)Zhong Y, Zhang H, Jain AK (2000) Automatic caption localization in compressed video. IEEE Trans Pattern Anal Machine Intell 22(4):385–392
(DCT)Crandall D, Antani S, Kasturi R (2003) Extraction of special effects caption text events from digital video. Int J Document Anal Recognit 5(2–3):138–157
(DCT)Gargi U, Crandall D.J, Antani S, Gandhi T, Keener R, Kasturi R (1999) A system for automatic text detection in video. International conference on document analysis and recognition, pp 29–32
HYBRID METHODS(混合方法 region-based+texture-based)
usually consist of two stages. The first localizes the text with a fast heuristic technique while the second
verifies the previous results eliminating some detected area as false alarms using machine learning
(wavelet +SVM)Ye Q, Huang Q, Gao W, Zhao D (2005) Fast and robust text detection in images and video frames. Image Vision Comput 3(6):565–576
(stroke filtering, CGV+normalized gray intensity+SVM)Jung C, Liu Q, Kim J (2009) A stroke filter and its application to text localization. Pattern Recogn Lett 30(2):114–122
(edge density , eLBP + SVM)Anthimopoulos M, Gatos B, Pratikakis I (2010) A two-stage scheme for text detection in video images. Image Vision Comput 28(9):1413–1426
(color CC, wavelet histogram + OCR statistic features +SVM)Ye Q, Jiao J, Huang J, Yu H (2007) Text detection and restoration in natural scene images. J Vis Commun Image Represent 18(6):504–513
Ji R, Xu P, Yao H, Zhang Z, Sun X, Liu T (2008) Directional correlation analysis of local Haar binary pattern for text detection. IEEE International Conference on Multimedia & Expo, pp 885–888
texture-based
(slide the sliding windows in different size, and use classifiers to classify them. But the text region may fall between scales, which means the classifier may not correctly classify them)(自己造的英语, 用中文可能表述不清楚,大家凑合看)
Jung K (2001) Neural network-based text location in color images. Pattern Recogn Lett 22(14):1503–1515
Text information extraction in images andvideo: a surveyKeechul Junga;∗, Kwang In Kimb, Anil K. Jainc
Applications of Support Vector Machinesfor Pattern Recognition: A SurveyHyeran Byun1 and Seong-Whan Lee21Department of Computer Science, Yonsei University Shinchon-dong, Seodaemun-gu, Seoul 120-749, Korea
Lienhart R, Wernicke A (2002) Localizing and segmenting text in images and videos. IEEE Trans Circuits and Systems for Video Technol 12(4):256–268
Li H, Doermann D, Kia O (2000) Automatic Text Detection and Tracking in Digital Video. IEEE Trans Image Process 9(1):147–156
Chen X.R, Yuille A.L (2004) Detecting and reading text in natural scenes. IEEE computer society conference on computer vision and pattern recognition, pp 366–373
Viola PA, Jones MJ (2004) Robust real-time face detection. Int J Comp Vision 57(2):137–154
Ojala T, Pietikainen M, Harwood D (1996) A comparative study of texture measures with classification based on feature distributions. Pattern Recogn 29(1):51–59
eLBP
(eLBP)Anthimopoulos M, Gatos B, Pratikakis I (2010) A two-stage scheme for text detection in video images. Image Vision Comput 28(9):1413–1426
(LBP)Ojala T, Pietikainen M, Harwood D (1996) A comparative study of texture measures with classification based on feature distributions. Pattern Recogn 29(1):51–59

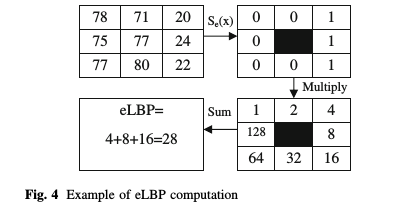
本图及以下图片来源: M. Anthimopoulos, B. Gatos, and I. Pratikakis. Detection of Artificial and Scene Text in Images and Video Frames. Pattern Analysis and Applications, 16(3):431–446, 2013.
简单说一下LBP, 如图3x3像素, 以中心像素为threshold, 对它的8 -neighborhood进行二值化, 然后从对应第三个图(固定的)乘积求和, 最后得到LBP = 1*1+1*64 =65
LBP : http://www.ee.oulu.fi/research/imag/mvg/files/pdf/CVPR-tutorial-final.pdf
http://files.meetup.com/4379272/BIPCVG_LocalBinaryPatterns_2013.01.16.pdf
http://www.cse.oulu.fi/CMV/Research/LBP/LBPShort
相关应用书籍: computer vision using local binary patterns
eLBP, 通过对它的8 -neighborhood, 分别与中心像素做差, 根据差绝对值大小来决定它的8 -neighborhood 像素分别是什么值.

(LTP, local texture patterns, a generalization of LBP )X. Tan and B. Triggs. Enhanced Local Texture Feature Sets for Face Recognition Under Difficult Lighting Conditions. IEEE Transactions on Image Processing, 19(6):1635–
1650, 2010.
LTP 算法是对LBP的一种演化, extends LBP to 3-valued codes, 即由原本的1,0 构成的组合换为 1, 0, -1

图片来源: X. Tan and B. Triggs. Enhanced Local Texture Feature Sets for Face Recognition Under Difficult Lighting Conditions. IEEE Transactions on Image Processing, 19(6):1635 1650, 2010.
MSER
wiki :https://en.wikipedia.org/wiki/Maximally_stable_extremal_regions
(MSER,Maximally Stable Extremal Regions,affinely-invariant stable )
J. Matas, O. Chum, M. Urban, and T. Pajdla. Robust Wide-Baseline Stereo from Maximally Stable Extremal Regions. Image and Vision Computing, 22(10):761–767, 2004.
Per-Erik Forssén. Maximally stable colour regions for recognition and matching. In Computer Vision and Pattern Recognition, 2007. CVPR'07. IEEE Conference on, pages 1–8. IEEE, 2007.
Extremal regions have two desirable properties.The set is closed under continuous (and thus perspective) transformation of image coordinates and, secondly, it is closed under monotonic transformation of image intensities.
(论文看着困难的话看看这个PPT)http://www.micc.unifi.it/delbimbo/wp-content/uploads/2011/03/slide_corso/A34%20MSER.pdf
http://www.vlfeat.org/overview/mser.html
(mser+CNN)Robust Scene Text Detection with Convolution Neural Network Induced MSER Trees Weilin Huang et.al
(ICDAR2011 CC(mser), adaboost(6D vector), normalization,MLP )Scene Text Detection via Connected ComponentClustering and Nontext FilteringHyung Il Koo, Member, IEEE, and Duck Hoon Kim, Member, IEEE
(mser, pixel level segmentation )MSER-based Real-Time Text Detection and TrackingLlu´ıs Gomez and Dimosthenis Karatzas
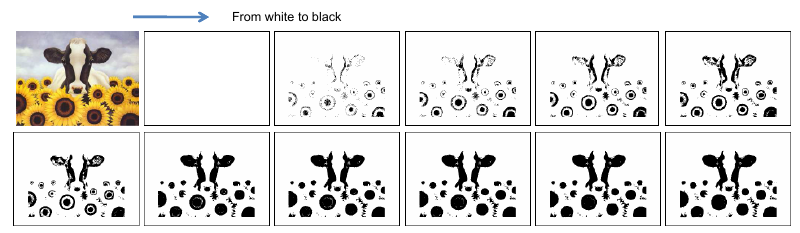
简要说说mser, 它就是一个从低到高进行一系列threshold的过程, 如图
图片来源: 上面那个PPT
看图中的每一个黑点(connect component, 这里叫Extremal Regions), 它是从小到大随着threshold增加慢慢生长变大的过程, 当它长的没那么快时(基本上不变时), 它就达到了Maximally Stable Extremal Regions
如何判断是否为MSER, 原始论文中有公式自己去看
RANDOM FORESTS随机森林
(random forests随机森林)Breiman L (2001) Random forests. Machine Learn 45(1):5–32
http://www.stat.berkeley.edu/~breiman/RandomForests/cc_home.htm
决策树PPT(decision tree)http://www.autonlab.org/tutorials/dtree18.pdf
PDF(probability density function)(这东西到底怎么用..)
wiki : https://en.wikipedia.org/wiki/Probability_density_function
最后
以上就是清秀荷花最近收集整理的关于再探OCR------text detection in natural scene自然场景下的字符识别 [持续更新]的全部内容,更多相关再探OCR------text内容请搜索靠谱客的其他文章。




![再探OCR------text detection in natural scene自然场景下的字符识别 [持续更新]](https://www.shuijiaxian.com/files_image/reation/bcimg11.png)



发表评论 取消回复