我当前在做的项目需求:在xx单子中提取出我想要的关键词,涉及中文分词的内容,可以借助IK分词器实现此功能。
1、引入依赖
ik用于分词,commons-io用来读取文件内容(我懒)
<dependency>
<groupId>com.janeluo</groupId>
<artifactId>ikanalyzer</artifactId>
<version>2012_u6</version>
</dependency>
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.8.0</version>
</dependency>注意:如果项目使用了ElasticSearch,可能会出现冲突,需根据你的情况手动排除,如下
<dependency>
<groupId>com.janeluo</groupId>
<artifactId>ikanalyzer</artifactId>
<version>2012_u6</version>
<exclusions>
<exclusion>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
</exclusion>
<exclusion>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
</exclusion>
<exclusion>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
</exclusion>
</exclusions>
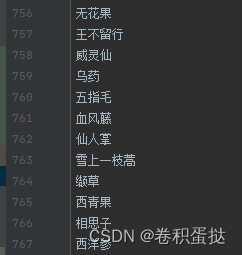
</dependency>2、创建自己的词典
创建文件,在里面输入自己想要扩充的词语,放到resources中,命名如“keywords.dic”
3、创建分词工具类
package com.iherb.user.util;
import org.apache.commons.io.IOUtils;
import org.wltea.analyzer.cfg.Configuration;
import org.wltea.analyzer.cfg.DefaultConfig;
import org.wltea.analyzer.core.IKSegmenter;
import org.wltea.analyzer.core.Lexeme;
import org.wltea.analyzer.dic.Dictionary;
import java.io.StringReader;
import java.nio.charset.StandardCharsets;
import java.util.*;
public class KeywordUtil {
Configuration cfg;
List<String> expandWords = new ArrayList<>();
/**
* 每个词的最小长度
*/
private static final int MIN_LEN = 2;
KeywordUtil() {
cfg = DefaultConfig.getInstance();
cfg.setUseSmart(true); //设置useSmart标志位 true-智能切分 false-细粒度切分
boolean flag = loadDictionaries("keywords.dic");
if (!flag) {
throw new RuntimeException("读取失败");
}
Dictionary.initial(cfg);
Dictionary.getSingleton().addWords(expandWords); //词典中加入自定义单词
}
/**
* 加载自定义词典,若无想要添加的词则无需调用,使用默认的词典
* @param filenames
* @return
*/
private boolean loadDictionaries(String... filenames) {
try {
for (String filename : filenames) {
expandWords.addAll(
IOUtils.readLines(
KeywordUtil.class.getClassLoader().getResourceAsStream(filename),
StandardCharsets.UTF_8
)
);
}
return true;
} catch (Exception e) {
e.printStackTrace();
}
return false;
}
/**
* 提取词语,结果将按频率排序
* @param text 待提取的文本
* @return 提取出的词
*/
public List<String> extract(String text) {
StringReader reader = new StringReader(text);
IKSegmenter ikSegmenter = new IKSegmenter(reader, cfg);
Lexeme lex;
Map<String, Integer> countMap = new HashMap<>();
try {
while ((lex = ikSegmenter.next()) != null) {
String word = lex.getLexemeText();
if (word.length() >= MIN_LEN) { //取出的词至少#{MIN_LEN}个字
countMap.put(word, countMap.getOrDefault(word, 0) + 1);
}
}
List<String> result = new ArrayList<>(countMap.keySet());
//根据词出现频率从大到小排序
result.sort((w1, w2) -> countMap.get(w2) - countMap.get(w1));
return result;
} catch (Exception e) {
e.printStackTrace();
}
return Collections.emptyList();
}
/**
* 提取存在于我扩充词典的词
* @param num 需要提取的词个数
* @return
*/
public List<String> getKeywords(String text, Integer num) {
List<String> words = extract(text);
List<String> result = new ArrayList<>();
int count = 0;
for (String word : words) {
if (expandWords.contains(word)) {
result.add(word);
if (++count == num) {
break;
}
}
}
return result;
}
public static void main(String[] args) {
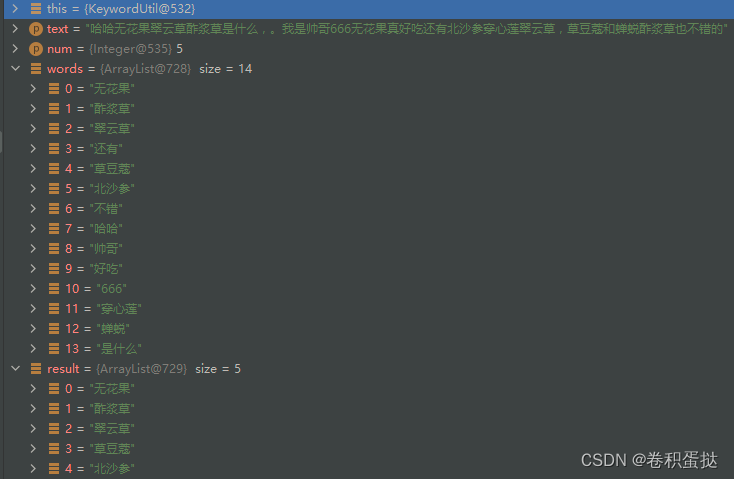
String text = "哈哈无花果翠云草酢浆草是什么,。我是帅哥666无花果真好吃还有北沙参穿心莲翠云草,草豆蔻和蝉蜕酢浆草也不错的";
KeywordUtil keywordUtil = new KeywordUtil();
List<String> keywords = keywordUtil.getKeywords(text, 5);
keywords.forEach(System.out::println);
}
}
4、测试
最后
以上就是孝顺野狼最近收集整理的关于使用java中文分词&&文本关键词提取的全部内容,更多相关使用java中文分词&&文本关键词提取内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复